
Spark est un framework open source de calcul distribué. Plus performant qu’Hadoop, disponible avec trois langages principaux (Scala, Java, Python), il s’est rapidement taillé une place de choix au sein des projets Big Data pour le traitement massif de données aussi bien en batch qu’en streaming. Depuis la version 2.0, Spark propose une nouvelle approche pour le streaming : Structured Streaming. Je vous propose de la découvrir ensemble ce qu’est Spark Streaming et comment il fonctionne dans une série de 3 articles. C’est parti !

Fonctionnement de Spark Structured Streaming
Structured streaming, c’est la possibilité de traiter des flux de streaming avec la librairie Spark SQL en utilisant des objets classiques comme les dataframes ou les datasets. Cette approche remplace l’ancienne librairie spark streaming et qui avait l’énorme désavantage de manipuler des objets comme les DStreams.
L’équipe en charge de Spark continue donc d’unifier le framework en positionnant la librairie SQL au centre du projet pour traiter aussi bien le batch, le streaming ou le machine learning.
Mais revenons au streaming.
Un traitement de ce type peut se décomposer en 3 phases :
- Lecture d’un flux (dans notre cas, un topic Kafka)
- Transformation des données
- Écriture dans une cible (dans notre cas, deux cibles HDFS et postgresSQL)
Pour la lecture Kafka, on peut procèder comme ceci.
def readFromKafka(topic: String, bootstrapServers: String): Dataset[String] = {
val df = spark.readStream
.format("kafka")
.option("kafka.bootstrap.servers", bootstrapServers)
.option("subscribe", topic)
.option("startingOffsets", "latest")
.option("failOnDataLoss", value = false)
.load()`
.select(col("value))
}On va ensuite sauvegarder les données reçues sur hdfs. Pour cela, il suffit d’écrire une fonction simple qui prendra en entrée notre dataframe précédent. On va lui donner 3 paramètres supplémentaires :
- Path : l’emplacement où stocker les données
- CheckpointHdfsPath : l’emplacement où stocker les informations de checkpoint (nous verrons l’intérêt plus tard)
- TriggerDelay: le délai en ms entre deux écritures (et oui, on fonctionne en toujours en micro-batch)
def writeToHdfs(df: DataFrame, path: String, checkpointHdfsPath: String, triggerDelay: Long = 60000L): StreamingQuery = {
df.writeStream
.trigger(Trigger.ProcessingTime(triggerDelay))
.format("parquet")
.option("path", path)
.option("checkpointLocation", checkpointHdfsPath)
.outputMode(OutputMode.Append())
.start()
}Le mode micro-batch signifie que Spark va générer du code qui va s’exécuter à fréquence régulière. Cette fréquence est réglable via le paramètre trigger. Si jamais le traitement prend plus de temps que le délai entre 2 exécutions, ce n’est pas forcément grave: les exécutions qui auraient dû se lancer sont tout simplement oubliées. Evidemment, si le traitement prend trop de temps, les données risquent de s’accumuler dans Kafka, ce qui va nécessiter plus de temps pour les traiter. Il ne faut donc pas que ce phénomène persiste trop longtemps.
Pour la sauvegarde sur Postgres, le principe est le même sauf que l’on indique le nom d’une table plutôt qu’un chemin.
def writeToPostgre(data: DataFrame, table: String, triggerDelay: Long = 60000L): StreamingQuery = {
agg.writeStream
.trigger(Trigger.ProcessingTime(triggerDelay))
.outputMode(OutputMode.Update())
.foreach(writerSQL(table))
.option("checkpointLocation", checkpointCkdbPath)
.start()
}Dans notre cas d’usage, on va au préalable agréger les données sur une fenêtre de temps avant d’écrire le résultat dans postgres. Nous verrons cela tout à l’heure.
Spark génère des requêtes indépendantes pour chaque écriture en streaming.
Stéphane Walter
Dans le détail, l’écriture dans une base de données est un peu plus complexe, surtout avec la version spark 2.3.0 que nous utilisons. C’est pourquoi nous passons par l’instruction `foreach(writerSQL(table))`. Je ne détaillerai pas plus cette partie dans cet article car cela nous amènerait trop loin. Sachez simplement que nous insérons les données en mode upsert dans la database.
Le point capital à comprendre sur le Structured Streaming est que Spark génère des requêtes indépendantes pour chaque écriture en streaming. Ce point n’est jamais abordé dans la documentation qui traite de cas très simples.
Comment cela va se traduire sur notre exemple ?
- Une première requête qui va lire les données Kafka puis sauvegarder les données sur HDFS.
- Une deuxième requête qui va aussi lire les données Kafka, les agréger avant de les insérer dans une table postgres.
On aurait pu croire que la lecture Kafka ne se ferait qu’une fois et que le demi-flux alimenterait en Y deux flux de sortie.
Si jamais vous avez l’idée, à partir des données agrégées d’alimenter non pas 1 table mais 5 tables par exemple, cela va générer 5 traitements distincts comprenant donc 5 lectures kafka, 5 calculs d’agrégat et 5 écritures en base. Autant dire que les performances vont forcément se dégrader.
Dans ce cas de figure, essayez d’alimenter 1 seule table d’agrégat au niveau de granularité qui va bien puis construisez dans la base des vues pour reconstituer les tables demandées.
Ce mode de fonctionnement présente l’avantage de la simplicité. Aucune adhérence entre les requêtes. Chaque requête est autonome et gère ses interruptions, coupures, problèmes via les checkpoints.
Il faut maintenant programmer les requêtes. Cela peut se faire comme ceci.
val input = readFromKafka("topicTest", "kafka:9092")
val outputHdfs = writeToHdfs(input, "testHdfs", "ckpHdfs")
val data = normalize(input)
val agregat = aggData(data)
val outputDb = writeToPostgres(agregat, "testTable", "ckpTable")
spark.streams.awaitAnyTermination(TIMEOUT)La dernière instruction est essentielle. C’est elle qui va indiquer à Spark de faire tourner les requêtes jusqu’à ce que la valeur de TIMEOUT soit atteinte. Nous verrons plus tard quelle valeur mettre pour ce timeout.
Les subtilités du streaming
La gestion des données en retard
- Que se passe t’il quand les données arrivent en retard ?
- Faut-il les prendre en compte dans les calculs ?
- Si une donnée arrive avec un jour de retard, dois-je recalculer l’agrégat de la veille ?
- Si une donnée arrive avec un an de retard, dois-je recalculer l’agrégat de la veille, de la semaine dernière, du mois dernier, etc. ?
Spark propose une solution intelligente (valable uniquement pour les calculs d’agrégats) : le watermark.
Le watermark va fixer la limite acceptable de retard. Au-delà, la donnée ne sera pas prise en compte. Cela va permettre à Spark de purger les données conservées en mémoire.
Mais comment cela marche-t-il ?
Pour comprendre, on a besoin de détailler notre méthode pour calculer les agrégats.
def aggData(df: DataFrame, watermark: String = "60 seconds"):DataFrame = {
df.select("requestId", "hostname", "status","datum", "bytes")
.withWatermark("datum", watermark)
.groupBy(window($"datum", "60 seconds","60 seconds"), $"hostname", $"status")
.sum("bytes")
.withColumnRenamed("sum(bytes)","bytes")
.withColumn("datum",$"window.start")
}Détaillons maintenant notre méthode.
On reçoit un dataframe en entrée et nous conservons uniquement 5 colonnes :
- requestId : un identifiant unique de l’enregistrement
- hostname : un nom de machine qui servira de dimension
- status : un statut qui servira aussi de dimension
- datum : l’horodatage de l’enregistrement au format timestamp
- bytes : un nombre de bytes transmis par les machines
Nous allons donc agréger les bytes sur une fenêtre de temps de 60s et le calcul de cet agrégat se fera toutes les 60s également.
Le watermark nécessite que les données en entrée soient horodatées.
Dans notre exemple, c’est le champ datum qui joue ce rôle.
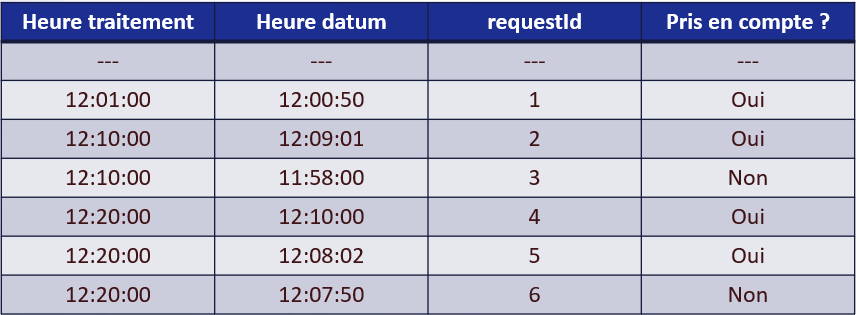
Quelques explications sur ces résultats dont certains surprendront ceux qui débutent sur Spark Structured Streaming.
- Ligne 2 (heure d’horodatage 12:00:50) – C’est le premier enregistrement donc il est pris en compte.
- Ligne 3 (heure d’horodatage 12:09:01) – L’enregistrement a moins d’une minute de retard donc il est pris en compte. Mais de quel retard parle-t-on ?
- Ligne 4 (heure d’horodatage 11:58:00) – L’enregistrement a plus de 60s de retard donc il n’est pas pris en compte.
- Ligne 5 (heure d’horodatage 12:10:00) – Le résultat le plus surprenant de prime abord: la donnée arrive avec plus de 10 min de retard et Spark va le conserver pour faire son calcul d’agrégat. C’est tout simplement dû au fait que le retard ne se calcule pas par rapport à l’heure du traitement mais par rapport à l’heure des données reçues. Au moment où je traite cette donnée, la dernière donnée reçue datait de 12:09:01 donc cet enregistrement n’est pas en retard.
- Ligne 6 (heure d’horodatage 12:08:02) – C’est la même explication. A noter que l’enregistrement 4 n’est pas pris en compte car il traité dans le même lot (le même micro-batch).
- Ligne 7 (heure d’horodatage 12:07:50) – Ici en revanche, l’enregistrement a exactement 71s de retard par rapport à l’enregistrement 2 : il n’est donc pas pris en compte.
La lecture Kafka
Kafka ne gère pas grand-chose: c’est le client qui doit demander à Kafka quels messages il veut lire. Le terme technique utilisé se nomme OFFSET et correspond à une sorte d’index de la donnée.
Sur ce projet, on a réglé l’offset à latest dans les paramètres de lecture. Cela signifie que quand Spark démarre, il ne commence à lire qu’à partir du dernier message (en oubliant tous les messages précédents). C’est indispensable quand on est sur un projet à très forte volumétrie.
- Que se passe-t’il quand le traitement plante ou s’arrête ?
- Va-t-il redémarrer sur le dernier message à cause du latest ? Non
Spark va ckecker en fait le dossier des checkpoints et redémarrer à partir du dernier offset traité.
Lors d’une indisponibilité très importante de la plateforme (mais pas du kafka), il est donc primordial de purger les checkpoints sinon votre traitement va essayer de traiter tout le stock de messages accumulé et risque de ne jamais pouvoir rattraper son retard.
Les doublons Kafka
Kafka garantit la fourniture des messages mais pas leur unicité.
Cela signifie que Kafka peut envoyer plusieurs fois le même message.
Ce problème n’est pas systématique.
Spark propose une commande simple pour gérer ce cas : dropDuplicates.
def aggData(df: DataFrame, watermark: String = WATERMARK_VALUE):DataFrame = {
df.select("requestId", "hostname", "status","datum", "bytes")
.withWatermark("datum", watermark)
.dropDuplicates("datum", "request_id")
.groupBy(window($"datum", "60 seconds","60 seconds"), $"hostname", $"status")
.sum("bytes")
.withColumnRenamed("sum(bytes)","bytes")
.withColumn("datum",$"window.start")
}Attention à bien rappeler le nom de la colonne sur laquelle s’applique le watermark sous peine d’avoir des fuites mémoires avec Spark qui conserverait l’ensemble de l’historique pour réaliser son dropDuplicates.
Les données de détail ne sont donc pas dédoublonnées et nécessitent d’utiliser des distincts lorsqu’on fait des analyses.
La maintenance des traitements de streaming
Si vous travaillez sur un cluster de production, vous avez sûrement mis en place Kerberos pour sécuriser les connexions entre machine. Or la durée de vie des tickets Kerberos est limitée. Au bout d’un certain temps (autour de 4 jours), le ticket expire et le traitement tombe en erreur à cause d’un défaut de droit.
De manière générale, on évitera si possible de killer le traitement de manière trop brutale. Dans ces conditions, comment assurer la mise à jour de notre job ou le renouvellement d’un ticket Kerberos ?
Notre préconisation est de mettre en place un arrêt planifié du traitement sur une période creuse via un timeout positionné sur l’instruction awaitTermination.
spark.streams.awaitAnyTermination(TIMEOUT)Afin de planifier l’arrêt à heure fixe (03h00), nous avons développé une fonction qui calcule automatiquement la valeur du timeout en fonction de l’heure de lancement effective. Une fois arrêtée, il suffit de relancer le traitement avec un ordonnanceur comme pour un traitement batch.
Et grâce au checkpoint, cet arrêt régulier ne provoque pas de perte de messages.
Cela termine ce premier article. Dans le prochain post, nous aborderons la transformation de données, le contrôle qualité et les tests unitaires.







![[Data Rider] Booster Mario Kart à l’IoT et à l’IA – Etape 2 : la donnée en temps réel, du capteur au Dashboard](https://fr.blog.businessdecision.com/wp-content/uploads/2024/02/data-rider-2-donnees-temps-reel-1024.jpg)






Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.