
Habituées depuis de nombreuses années à transformer les données provenant de leurs systèmes de production en indicateurs de pilotages, les organisations sont devenues expertes en tableaux de bord et autres Dashboards diffusés à tous les niveaux hiérarchiques des organisations.

Une explosion du volume des données qui ne fait que commencer
Avec l’avènement des réseaux sociaux, la généralisation de l’utilisation de mobiles et l’apparition de l’IoT (Internet of Things), la Data est devenue pléthorique, riche, et très diverse. Ce phénomène a été théorisé sous le nom de Big Data. Les organisations doivent convenablement gérer cette nouvelle masse de données, si elles veulent rester dans la course et ne pas être dépassées.
Cette explosion du volume de la Data n’en est qu’à ses débuts. Selon IDC, 200 milliards d’objets connectés verront le jour, et ainsi chaque personne sur terre générera 1,7 mégabytes de données par seconde d’ici 2020. J’aime rappeler qu’on estime à 180 zettaoctets le poids des données digitales à l’horizon 2025, soit encore « un peu » moins que le nombre d’étoiles dans notre univers observable (estimation Nasa : 1024) ce qui nous fait sentir encore bien petit malgré toute notre production de données !
Le Big Data sans intelligence, ce n’est pas grand-chose
Comme une complexité ne vient jamais seule, la maîtrise technique de ces données ne suffit pas. Afin de pouvoir les transformer en valeur, il va falloir « les faire parler ». Pour cela, ces énormes sources de données doivent être canalisées puis « apprivoisées » en les visualisant (Data visualization), en les interprétant (descriptive analytic) et en les modélisant (predictive analytic) avec différentes approches (statistique, machine learning…). La surcouche « intelligente » du Big Data est apparue : c’est la Data science.
La « transformation en valeur » de la donnée va donc à la fois se complexifier et démultiplier la capacité de création de valeur. Cette création de valeur va tout d’abord se réaliser par l’identification des données qui peuvent améliorer, faire croître, ou réinventer… l’activité de l’organisation.
L’identification et l’intégration de nouvelles sources de données
Identifier de nouvelles sources de données est aujourd’hui fondamental dans une approche Data-centric. Bien entendu, il ne faut pas négliger certaines complexités de la collecte, du stockage et de la diversité des données et de la gouvernance.
Dans une approche pragmatique, on cherchera à valoriser dans un premier temps les données existantes dans les systèmes de production de l’organisation. On orientera ensuite la collecte vers des masses de données externes (Open Data, Data providers, flux RSS, réseaux sociaux…) afin d’enrichir les analyses, d’approfondir la compréhension de comportements et de détecter des changements.
Les enjeux métiers (amélioration de la qualité, fiabilité des appareils, sécurité…) amènent aussi les organisations à collecter des données de senseurs et d’objets connectés (IoT) produites par l’homme et les machines. Ces données, de par leurs sources et leurs formats hétérogènes sont souvent stockées dans des systèmes « silotés ». Et tout l’intérêt consiste à « casser » ces silos pour mieux les exploiter et les valoriser.
Même si la canalisation d’énormes volumes de données n’est pas au centre du business modèle de l’organisation, le simple croisement de sources de données externes ajoute de la valeur aux analyses de l’entreprise.
Le Datalake permet la démocratie et évite l’anarchie
Le premier réflexe, pour être capable de manipuler des données externes, est souvent de réconcilier directement les différents flux dans les outils d’analyse. Et ce, sans implémenter une solution centralisée. En effet, les outils d’analyse des données sont simples d’utilisation, puissants par leur capacité de calcul « In memory », et déjà capables de gérer un certain volume de données. Mais ce mode de fonctionnement, bien que pouvant être un point de passage intéressant pour travailler la culture de la donnée externe, va trouver assez rapidement ses limites.
En effet, il ne permet pas le partage des sources de données pouvant avoir de la valeur pour toute l’organisation. Surtout, s’il est mal gouverné, des référentiels de données vont apparaître un peu partout et un mode de consommation très anarchique.
Nous sommes régulièrement confrontés à des situations où apparaissent de multiples branchements directs des systèmes analytiques sur des systèmes opérationnels. Ce mode de fonctionnement dégrade leur performance et déclenche même des dénis de service.
La mise en place d’un Datalake préconisée
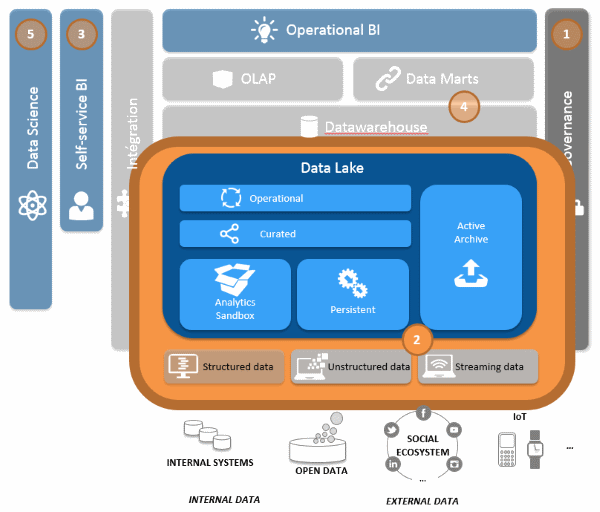
Afin de pouvoir démocratiser l’utilisation de la donnée à différents niveaux d’organisation, nous préconisons la mise en place d’un Datalake. Ce concept est un moyen pour les organisations de mettre en œuvre une plateforme de stockage de données, structurées ou non, provenant de diverses sources internes et externes. Pour y être intégrées, ces données doivent être qualifiées tant sur leur fiabilité que sur leur valeur ajoutée pour l’organisation.
Une question qui nous est très fréquemment posée est la cohabitation du Datalake avec le Datawarehouse d’entreprise. La réponse est claire : oui, les deux composants doivent cohabiter car ils ont deux rôles différents :
- Le Datawarehouse sert à produire le référentiel d’indicateurs partagés pour le pilotage de l’organisation.
- Le Datalake est le réceptacle de toutes les données qualifiées pour tous les types de consommations.
Le Datalake va donc devenir le système source du Datawarehouse. Mais il va permettre aussi la gestion et l’intégration de données en mode streaming pouvant ouvrir un mode d’utilisation « temps réel » des données.
Nous verrons aussi, dans un prochain chantier, l’importance de maintenir le référentiel centralisé de l’organisation pour éviter qu’il y ait autant d’indicateurs que de consommateurs de données !
Quel Datalake mettre en œuvre ?
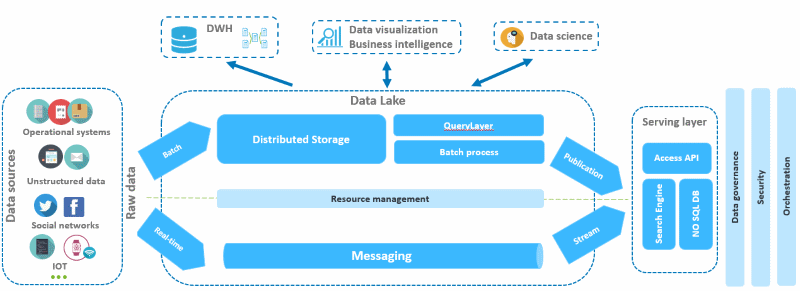
Il n’existe pas de vérité absolue sur l’orientation technologique que doit prendre un Datalake. Cependant nous pouvons citer trois types de briques pouvant s’interconnecter et coexister :
- les plateformes Big Data distribuées de type Spark et/ou cluster Hadoop, qui permettent de gérer nativement les données variées et volumineuses,
- les bases de données NoSQL qui elles, peuvent gérer des données de type log et/ou semi-structurées
- et enfin pour des problématiques de données non structurées présentant un important volume, on peut utiliser des moteurs d’indexation avec analyse sémantique de type NLP (Natural Language Processing).
Je vous invite à consulter notre article Du datalake au datawarehouse agile qui présente bien ces différentes options.
Pour assurer une maintenabilité et exploitabilité optimale du Datalake, la mise en œuvre un système de suivi et de traçabilité des données est conseillée… Sinon le Datalake se transforme assez rapidement en un Dataswamp (ou marécage).
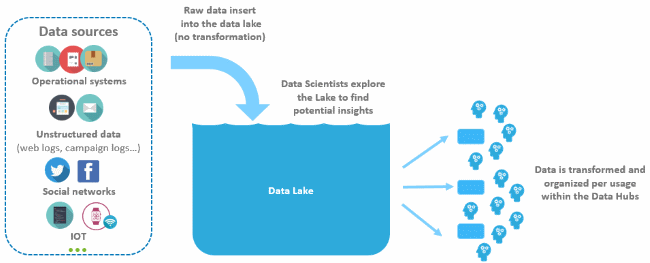
Le Datalake, un accès direct aux données pour les utilisateurs avancés
Contrairement à l’historique ODS (operational data store) qui était une sous-couche de préparation technique de la donnée pour l’alimentation du Datawarehouse, le Datalake va être ouvert à certains utilisateurs avancés.
Afin de transformer et normaliser les données du Datalake, il est possible de brancher des outils de Data préparation. Ils ont pour objectif de qualifier « techniquement parlant » la qualité des données. L’objectif ici : exclure les données mal formées ou aberrantes, ainsi qu’identifier les interactions et les croisements possibles de données.
Mais il va surtout mettre à disposition des utilisateurs Self-service BI, des sources de données qualifiées pouvant leur permettre de croiser des indicateurs déjà calculés et des sources de données brutes. Ce mode de fonctionnement permet à la fois aux utilisateurs avancés de disposer de nouvelles sources de données et de ne pas plugger de manière anarchique toutes les sources désirées.
Le Datalake permet aussi la mise en place de « Analytics Sandbox », potentiellement éphémères, qui donneront aux Data scientists une forte capacité d’analyse. Cette autonomie dans l’utilisation de la donnée, complétée par une mise à disposition de sources de données qualifiées et réutilisables, permet aux Data scientists de se concentrer sur le cœur de leur activité : la mise en place de modèles mathématiques créant de la valeur.
Le datalake est la brique technologique de la stratégie data
La mise en place du Datalake est le chapitre le plus technique de la stratégie Data. Il requiert donc une analyse architecturale poussée. Son implémentation peut être abordée de diverses manières, et le but de cette publication n’est pas de mettre en place un guide technique de mise en œuvre. Je vous propose cependant quelques conseils pour éviter certains écueils fréquemment rencontrés :
- Faire du projet « Datalake » un chantier 100 % technique. Ce composant, bien qu’étant une sous-couche de l’architecture, devient le référentiel Data de l’entreprise. Des utilisateurs avancés vont directement y piocher des sources de données. Son implémentation est donc autant un projet métier que technique.
- Sous-estimer la gouvernance dans sa mise en place et son utilisation. Par exemple, l’ouverture directe au Datalake ne doit se faire que pour les utilisateurs avancés. Et son utilisation correspond à des utilisations ad hoc ne devant pas remplacer les reporting d’entreprises.
- Mettre toutes les données dans le Datalake sans qualification. Il va très rapidement se transformer en marécage et être inutilisable.
- Ne pas croire que l’ODS est un Datalake. Le Datalake doit remplacer l’ODS et non l’inverse. L’ODS, est une sous-couche uniquement technique. Elle n’est pas faite pour une utilisation directe par le métier, et se retrouverait très rapidement inutilisable et saturée pas les gros volumes de données.







![[Data Rider] Booster Mario Kart à l’IoT et à l’IA – Etape 2 : la donnée en temps réel, du capteur au Dashboard](https://fr.blog.businessdecision.com/wp-content/uploads/2024/02/data-rider-2-donnees-temps-reel-1024.jpg)






Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.