
La course est lancée pour construire des modèles de langage de plus en plus grands et meilleurs ! Mais à mesure que les LLMs grandissent, ils deviennent de plus en plus ingérables. Les coûts computationnels sont astronomiques et les gains de performance commencent à plafonner. Mixture of Experts (MoE), une architecture astucieuse ancrée dans les années 1990, réémerge comme une solution…

Entreprise + IA + climat : l’équation à résoudre d’urgence
Webinar Demain 11h00 – 11h30En divisant les tâches entre des modèles « experts » spécialisés, MoE offre en effet une efficacité et une scalabilité accrues, permettant l’entraînement de modèles massifs tout en minimisant les surcharges computationnelles. Les avancées récentes, comme le Mixtral-8x7B de Mistral AI et les techniques innovantes de fusion de modèles, ont remis MoE sous les projecteurs. L’émergence des « frankenMoEs », qui assemblent des modèles pré-entraînés, souligne encore la flexibilité et le potentiel de cette approche.
Les « frankenMoEs » (ou « MoErges ») sont nommés d’après le monstre de Frankenstein, car ils sont créés en fusionnant plusieurs modèles pré-entraînés en une seule entité plus puissante.
MoEs en quelques mots :
- Pré-entraînement : significativement plus rapide comparé aux modèles denses avec le même nombre de paramètres.
- Inférence : plus rapide que les modèles denses avec un nombre de paramètres équivalent.
- Exigences en VRAM : élevées car tous les experts doivent être chargés en mémoire.
- Fine-tuning : historiquement difficile, mais les avancées récentes en MoE instruction tuning montrent des promesses.
Comment le MoE révolutionne les LLMs
Dans cet article, nous allons explorer le fonctionnement interne de Mixture of Experts (MoE), en examinant comment ce paradigme architectural révolutionne les Large Language Models (LLMs). Nous examinerons ensuite les applications récentes de MoE dans les LLMs et nous pencherons sur le modèle Pseudo MoE ainsi que sur les frankenMoEs créés avec MergeKit. Enfin, nous nous tournerons vers l’avenir pour discuter de la manière dont MoE ouvre la voie à une nouvelle génération de LLMs plus puissants, efficaces et accessibles que jamais. C’est parti !
Une vue d’ensemble de Mixture-of-Experts (MoE)
Mixture-of-Experts (MoE) est une architecture d’apprentissage automatique qui incorpore l’idée de « diviser pour régner » afin de résoudre des problèmes complexes. Dans cette approche, le modèle est composé de multiples modèles individuels appelés « experts », chacun se spécialisant dans un aspect des données. Le modèle inclut également une fonction de « gating » qui détermine quel expert ou combinaison d’experts consulter pour une entrée donnée.
La caractéristique clé des modèles MoE est leur capacité à gérer une gamme diversifiée de motifs de données grâce aux différentes expertises de leurs modèles composants. Chaque expert a son propre ensemble de paramètres et est généralement un modèle plus simple que celui nécessaire pour modéliser efficacement l’ensemble des données. Le mécanisme de gating apprend ensuite à reconnaître quel expert est le plus susceptible de fournir la meilleure sortie pour une entrée particulière, divisant ainsi efficacement l’espace de problème entre les différents experts.
Dans un véritable modèle MoE, les experts et la fonction de gating sont entraînés ensemble de manière end-to-end. Cet entraînement conjoint permet aux experts de se spécialiser dans différentes parties de l’espace d’entrée et à la fonction de gating d’apprendre comment utiliser au mieux les experts en fonction de l’entrée. C’est une sorte de « compétition coopérative » entre les experts où ils rivalisent pour contribuer au résultat final mais coopèrent dans le sens où leur expertise combinée mène à un meilleur modèle global.
Imaginez un modèle de langage de 7B paramètres où nous remplaçons ses couches standard par des couches MoE avec 8 experts chacun. Seulement 2 experts sont actifs par entrée, comme dans le Mixtral-8x7B. Cela nous donne la capacité d’un modèle de ~50B mais au coût computationnel d’un modèle de 14B, car nous n’utilisons qu’une fraction des paramètres totaux à tout moment. C’est la puissance de MoE : des cerveaux plus grands, des factures d’énergie plus petites.
Composants d’une couche MoE
Lorsqu’ils sont appliqués aux modèles transformer, les couches MoE ont deux composants principaux :
- Sparse MoE Layer : remplace les couches feed-forward denses dans le transformer par une couche sparse de plusieurs « experts » structurés de manière similaire.
- Router : détermine quels tokens dans la couche MoE sont envoyés à quels experts.
La plupart des large language models (LLMs) qui génèrent du texte utilisent une architecture standard transformer-only decoder (voir image ci-dessous). Mixture of Experts (MoE) introduit un changement simple mais percutant : elle remplace la sous-couche feed-forward standard à l’intérieur du transformer par une couche MoE spécialisée.
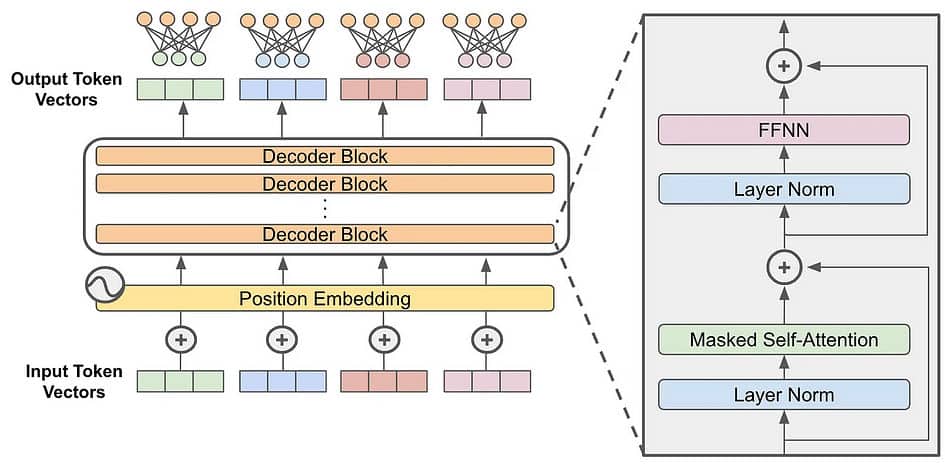
Ce que cela signifie en pratique ? La couche MoE se compose de multiples « experts » indépendants, chacun étant essentiellement une sous-couche feed-forward séparée avec ses propres paramètres uniques. Le nombre d’experts peut varier considérablement, allant de quelques-uns à des milliers, selon le modèle spécifique.
Le diagramme ci-dessous montre l’entrée alimentée dans la fonction de gating, qui pondère ensuite la contribution de chaque modèle expert pour produire la sortie finale. Les modèles experts eux-mêmes seraient montrés comme des réseaux individuels, chacun recevant la même entrée et produisant sa propre sortie.
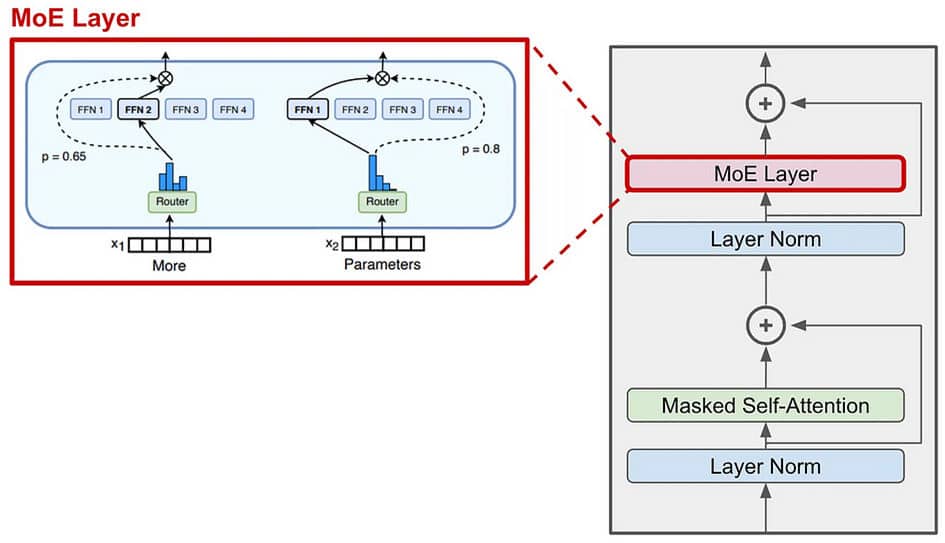
L’avantage principal des modèles MoE est leur efficacité dans la modélisation de fonctions complexes avec moins de paramètres qu’un seul grand modèle. Comme différents experts peuvent partager des paramètres, cela réduit le nombre total de paramètres nécessaires. Cette caractéristique rend les modèles MoE particulièrement utiles dans des environnements où les données sont diverses et complexes, et où un seul modèle peut avoir du mal à capturer tous les motifs différents présents dans les données.
La question principale maintenant est : Comment décider quel expert activer ? Un réseau de gating appris (G) décide quels experts (E) envoyer pour une partie de l’entrée :
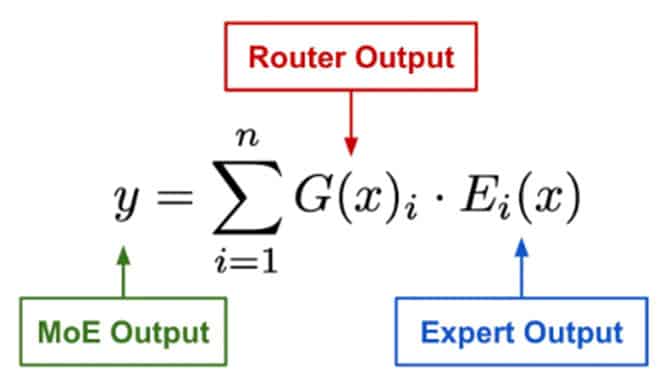
La sortie d’un module MoE est calculée en combinant les sorties de ses experts à l’aide de poids attribués par un router. Le router produit un poids pour chaque expert, indiquant sa contribution à la sortie finale. La puissance des MoEs réside dans leur capacité à produire des sorties spars où seuls quelques experts reçoivent des poids non nuls. Cette sparsité nous permet de construire et d’entraîner des réseaux neuronaux exceptionnellement grands tout en maintenant des exigences computationnelles raisonnables, car seule une sous-partie des paramètres du modèle est utilisée activement à tout moment.
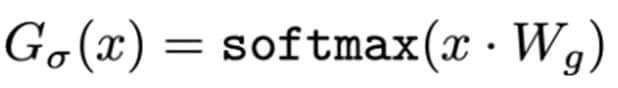
Dans les modèles MoE, les mécanismes de gating contrôlent comment les tokens sont acheminés vers différents experts. Une approche simple consiste à utiliser un softmax pondéré comme montré ci-dessus, mais cela peut ne pas aboutir à une sélection sparse des experts. Shazeer Noam a abordé cette question en proposant le Noisy Top-k Gating, qui ajoute du bruit et sélectionne seulement les top k experts, favorisant la sparsité et améliorant l’efficacité de l’entraînement.
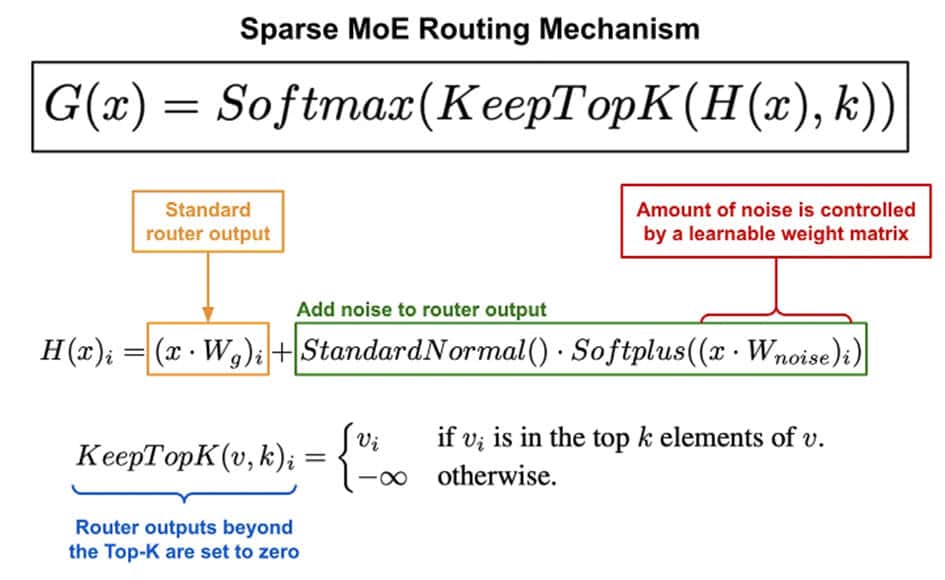
Le mécanisme de gating fonctionne de manière similaire au softmax gating mais avec deux améliorations clés :
1. Injection de bruit gaussien : Avant d’appliquer le softmax, une quantité configurable de bruit gaussien est introduite dans la sortie du router. Cette injection de bruit favorise la diversité dans la sélection des experts.
2. Top-K Masking des experts : Pour garantir la sparsité dans la sélection des experts, seules les sorties des top-K experts sont retenues, tandis que les autres sont masquées (réduites à négatif infini). Cela garantit qu’un nombre limité d’experts contribuent à la sortie finale.
Real-World Examples and Applications
- Mistral 7B : Ce LLM open-source développé par Mistral AI est conçu avec un accent sur l’efficacité et la performance. Il utilise une configuration 8x7B, ce qui signifie qu’il se compose de huit modèles experts, chacun avec 7 milliards de paramètres. Cela permet à Mistral 7B de se spécialiser dans différents aspects du traitement du langage, ce qui se traduit par une performance améliorée sur une variété de tâches par rapport à des modèles denses de taille similaire.
- GPT-4 : Bien que non officiellement confirmé par OpenAI, il est largement supposé que GPT-4 utilise une architecture MoE, basée sur plusieurs indices et analyses. Cela est soutenu par des fuites, des observations de ses capacités, et des inférences tirées des articles de recherche d’OpenAI. L’architecture MoE spéculée dans GPT-4 expliquerait probablement ses performances accrues dans diverses tâches telles que l’écriture créative, la génération de code et la gestion des instructions nuancées.
- PaLM 2 (Pathways Language Model 2) : Le dernier LLM de Google, PaLM 2, suggère également l’utilisation de MoE, bien que les détails spécifiques ne soient pas divulgués publiquement. Ses capacités améliorées en matière de raisonnement, de codage et de tâches multilingues suggèrent une architecture plus complexe que son prédécesseur, et MoE est un candidat plausible pour réaliser cela.
- Claude : Le modèle Claude d’Anthropic est un autre prétendant à l’utilisation de MoE. Bien que cela ne soit pas explicitement déclaré, ses performances solides dans diverses tâches et son accent sur la sécurité et les considérations éthiques s’alignent avec les avantages potentiels de l’architecture MoE.
Le modèle Pseudo MoE
Dans cette section, nous allons créer un modèle “pseudo” MoE. Ce n’est pas un vrai modèle MoE car nous n’entrainons pas les experts et la fonction de filtrage ensemble de manière intégrée. À la place, nous allons utiliser des modèles pré-entraînés comme nos experts et définir notre propre fonction de filtrage simple. Bien que cette approche ne capture pas pleinement la puissance d’un véritable modèle MoE, elle fournit une introduction utile au concept et nous permet d’explorer comment différents experts et fonctions de filtrage peuvent affecter la performance du modèle. Elle offre également une base pour comprendre comment un vrai modèle MoE pourrait être mis en œuvre et entrainé.

Maintenant que nous avons défini les mécanismes de gating soft et hard, nous allons maintenant définir le modèle Pseudo MoE :

Nous allons maintenant évaluer notre modèle Pseudo MoE sous différents mécanismes de gathing, hard et soft.

Dans notre nouveau modèle amélioré Pseudo MoE, nous avons remplacé la simple fonction de filtrage basée sur la longueur de l’entrée par une approche d’analyse de sentiment plus nuancée, en utilisant la bibliothèque TextBlob. Cela permet au modèle de diriger intelligemment les entrées vers l’expert le plus approprié en fonction de leur tonalité émotionnelle. De plus, nous avons élargi l’expertise du modèle en incorporant le modèle DistilBERT, une alternative légère mais puissante à BERT, en tant que nouvel expert.
Pour évaluer ces améliorations, nous avons testé le modèle mis à jour sur une variété d’entrées avec des sentiments divers. Cela a fourni des informations précieuses sur les forces et les faiblesses de chaque expert, révélant comment leur performance varie en fonction du contexte émotionnel du texte d’entrée.

Grâce à la bibliothèque MergeKit, nous pouvons aujourd’hui mettre en œuvre une version rapide et avancée du Pseudo MoE proposé précédemment, offrant trois méthodes distinctes pour initialiser les routeurs :
- Hidden (Recommandé) : C’est la façon la plus efficace de configurer vos portes, en utilisant les informations de vos prompts pour optimiser les performances. Cela nécessite un peu plus de puissance de calcul, mais c’est le choix par défaut pour une raison !
- Cheap Embed (Léger) : Si vous travaillez sur un appareil avec des ressources limitées, cette option est un bon compromis. Elle est plus simple et plus rapide, mais peut ne pas être aussi précise que la méthode “Hidden”.
- Random (Expérimental) : C’est une option aléatoire, idéale si vous prévoyez d’affiner votre modèle plus tard ou si vous cherchez des résultats imprévisibles.
Pour explorer cette méthode de création d’experts avec MergeKit, je recommande cet excellent article : Create Mixtures of Experts with MergeKit, de Maxime Labonne.
L’avenir de l’IA ne réside pas seulement dans la construction de modèles plus grands, mais plutôt dans la création de modèles plus intelligents, plus adaptables, adaptés à des domaines spécifiques, capables d’évoluer aux côtés des besoins humains.
L’avenir de MoE et des LLM
L’avenir de MoE et des LLM est prometteur, mais plusieurs défis doivent être relevés. Ceux-ci incluent le développement d’algorithmes robustes pour la sélection des experts, la gestion de la complexité de l’intégration de multiples experts et l’assurance de l’interprétabilité et de l’équité de ces systèmes. De plus, les considérations éthiques autour de la confidentialité des données, des biais et de l’impact environnemental des modèles à grande échelle doivent être abordées.
En regardant vers l’avenir, l’intégration de la multimodalité dans les LLM, comme on le voit dans les modèles tels que GPT-4o, promet de révolutionner davantage les capacités de l’IA. Ce passage vers des modèles capables de traiter et de générer non seulement du texte, mais aussi des images, du son et d’autres formes de données, ouvre un monde de nouvelles possibilités pour des applications dans divers secteurs et domaines.
L’avenir de l’IA reside dans la construction de modèles plus intelligents et plus adaptables
La convergence de MoE et des LLM, couplée au développement continu de modèles multimodaux, représente un moment charnière dans la recherche en IA. En combinant les forces de ces approches, nous pouvons libérer de nouveaux niveaux d’intelligence, d’efficacité et de créativité dans les systèmes d’apprentissage automatique, ouvrant la voie à des technologies d’IA plus avancées, durables et équitables. L’avenir de l’IA ne réside pas seulement dans la construction de modèles plus grands, mais plutôt dans la création de modèles plus intelligents, plus adaptables, adaptés à des domaines spécifiques, capables d’évoluer aux côtés des besoins humains.



![[Data Rider] REX Collecte de données IoT – Étape 1 : Initier la collecte](https://perspective.orange-business.com/wp-content/uploads/2025/05/data-rider-rex-collecte-donnees-1024x512-1.jpg)










Commentaire (0)
Votre adresse de messagerie est uniquement utilisée par Orange Business, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Orange Business en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.