
Les outils de Data Science permettent maintenant d’élargir le champ des possibles avec l’intégration d’outils de cartographie. Ceci est aussi réalisable grâce aux données sous licence libre d’OpenStreetMap et grâce aux efforts des collectivités locales et des entreprises pour mettre à disposition leurs données en ligne. L’Open Data et la Data Science permettent ainsi aujourd’hui d’optimiser l’analyse des données géographiques en mesurant des interactions très compliquées à modéliser autrement. Démonstration.

OpenStreetMap : réunir des données sur de multiples sujets
OpenStreetMap est un outil collaboratif open source qui est librement éditable et modifiable par tout utilisateur. Si vous êtes un commerce, vous pouvez – tout comme sur Google Maps – ajouter des informations sur la nature de votre commerce, vos heures d’ouvertures et beaucoup d’autres champs encore.
A l’image de Wikipedia, c’est un outil de plus en plus fiable, et il a bénéficié tout récemment de la contribution de Microsoft, qui a mis à disposition sur GitHub les coordonnées de tous les bâtiments américains synthétisés à l’origine pour Bing Map.
Pour les Data Scientists qui s’intéressent aux données spatiales, OpenStreetMap est une source inégalée pour réunir des données sur de multiples sujets. Un logiciel de Data Science permet par ailleurs d’interroger les données grâce à l’API (nous en parlerons plus loin) et de mesurer en tout point la distance avec des voies de transports ou les commerces, ainsi que les parcs ou les zones humides.
Nous aborderons différents aspects de ces outils :
- des cas d’usages pour les entreprises
- l’open data (beaucoup de données publiques sont géocodées) et les API
- les interfaces entre R / Leaflet et les librairies de cartographie Java comme Leaflet
3 cas d’usages pour les entreprises
1. Comptabilisation des POI
Les POI (Points of Interest) sont des lieux dignes d’intérêt. Lieux touristiques, commerces, administrations, stations de transports ou parcs urbains peuvent en faire partie.
Une entreprise souhaitant étudier son implantation peut utiliser ces données comme critère de choix et optimiser sa localisation, comme par exemple dans :
- le secteur du commerce, on peut ainsi évaluer la fréquentation touristique
- le secteur de l’immobilier, on peut aussi mieux cerner les atouts d’une zone par rapport à une autre
2. Étude des zones de chalandise
Dans le commerce, il est important de mieux connaître sa clientèle potentielle. En recoupant des données socio-démographiques ou économiques avec les localisations, un retailer peut mieux comprendre la concurrence et la population dans différents rayons géographiques.
Deux sources de données gouvernementales sont très utilisées dans ce domaine :
3. Optimisation de la logistique
Tout service logistique est confronté au problème de l’optimisation des tournées de livraison. La démocratisation des systèmes d’information géographiques permet à toutes les entreprises du secteur d’avoir accès à des données et des outils encore récemment réservés aux géographes.
L’analyse de données géolocalisées va donner la possibilité de mieux allouer les camions par entrepôt grâce à l’utilisation d’algorithmes de recherche opérationnelle.
Couplé à l’internet des objets (IoT), ces mêmes entreprises peuvent aussi suivre en temps réel leur flotte de camions, calculer les distances et temps de transport associés et informer les clients du délai de livraison.
Open Data et API
De plus en plus d’entreprises et d’organismes publics mettent à disposition des données en Open Data. Ces données sont accessibles :
- Sur une plateforme web dédiée
- A travers une API permettant de faire des requêtes à partir de la plupart des outils data du marché
Qu’est-ce qu’une API ?
API est l’acronyme de « Application Programming Interface », autrement dit interface de programmation. Chez Google, les API les plus connues concernent Google Maps dans le domaine de la cartographie ou Adwords qui permet aux annonceurs d’interagir via leurs propres applications avec leur compte Adwords.
Il existe aussi de plus en plus d’API d’intelligence artificielle. Celles-ci sont, soit librement utilisables et documentées sur le web, soit créées par un Data Scientist pour un usage spécifique en entreprise. Dans le 2ème cas, un exemple simple consiste à créer un modèle de machine learning avec Microsoft Azure ML et à appeler ce modèle pour l’appliquer à de nouvelles données dans Excel. Les API REST se sont rapidement répandues car elles sont simplement définies par des méthodes standardisées.
Schématiquement, on peut comparer ces méthodes à une télécommande de télévision où chaque bouton a une fonction (changer de chaine, augmenter le volume, etc.). L’ensemble de ces boutons est l’interface pour faire communiquer l’utilisateur et le téléviseur.
API Open Data : illustration
Pour illustrer ce qu’est une API Open Data, nous allons utiliser la plateforme de la MEL. La page de documentation de cet API explique très clairement ce qu’il est possible de faire avec.
On y distingue :
- Un service sur les datasets permettant de faire une recherche dans les multiples jeux de données disponibles
- Un service sur les records permettant de faire une recherche sur l’ensemble des données d’un dataset.
Il est aussi possible d’exporter les données en masse sous de multiples formats (csv, xls, xml, json, etc.). Cette interface est la plus simple si on a peur de mettre les mains dans l’API. C’est en fait une autre partie de l’API qui se nomme download.
Si les données sont de nature spatiale, un service de cartographie est intégré à la plateforme.
Les données spatiales
Parmi les catégories de données disponibles sur la plateforme de la MEL, on peut obtenir des données sur les transports en commun. Chacun des jeux de données est géocodé, nous allons maintenant voir, avec un exemple simple, comment les exploiter avec un langage de programmation statistique, avec pour la cartographie le package Leaflet sous R ou Folium sous Python.
Nous utiliserons :
- Les listes des arrêts de bus, métro et tramway au format geojson (sous forme de points – latitude + longitude, avec données descriptives)
- Les limites de zones IRIS, qui sont des zones de recensement INSEE avec une population de l’ordre de 2000 à 3000 personnes au format shapefile (sous forme de polygones + données descriptives)
Ces données peuvent alors être aisément importées pour les avoir comme objets spatiaux (SpatialPointsDataFrame / SpatialPolygonDataFrame sous R, ou GeoDataFrame sous Python).
On peut d’ores et déjà faire, par exemple, une carte simple du réseau tramway Lille – Roubaix et Lille – Tourcoing.
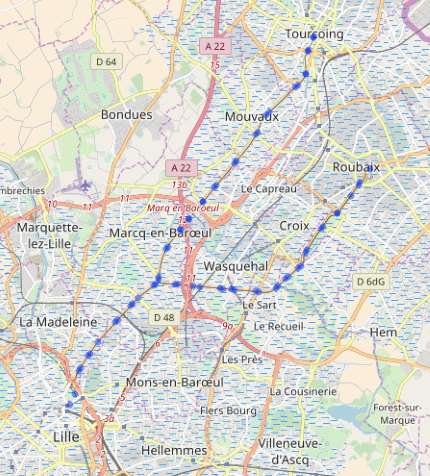
Ainsi que les limites de zones IRIS :
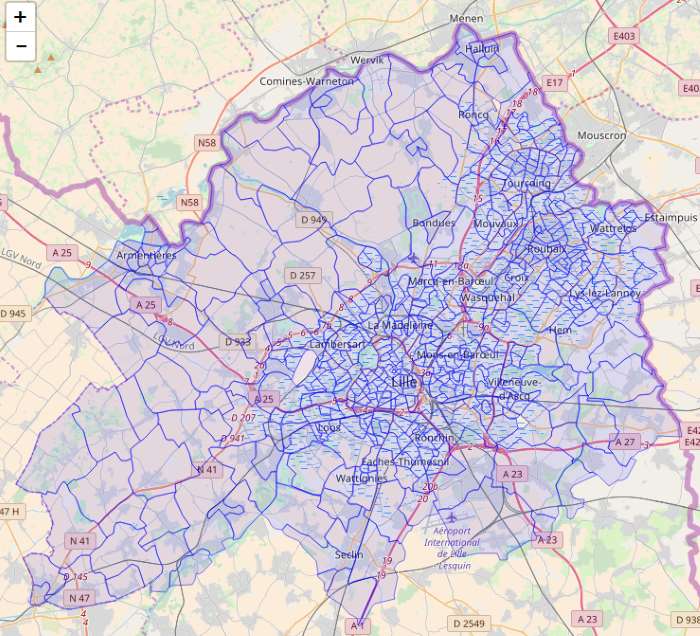
Données spatiales et données tabulaires
Nous cherchons à mesurer la densité de transports en communs dans la métropole lilloise. Ceci peut servir de critère de choix de localisation pour un commerce ou pour un futur propriétaire immobilier.
Pour simplifier, on peut calculer pour chacune des zones IRIS :
- le centre (ou centroïde)
- le nombre de bus / métros / tramways dans un rayon de 500 et 1000m (on les appelle des « buffer »)
On obtient alors une table avec 6 indicateurs pour chacune des zones, et on applique un algorithme de clustering (kmeans par exemple) pour segmenter les différents types de zones.
Les données peuvent être attachées par zone (population, etc.) pour faire ces calculs. Au final, tous les types de données peut être représentés avec des échelles de couleur, des légendes adaptées, et plusieurs couches d’information au sein d’une même carte interactive.
Le résultat est le suivant :

On peut naviguer interactivement dans la carte (cliquez sur l’image) pour afficher les stations. Notez qu’un clic sur une zone ou sur l’icône d’une station fait apparaitre son nom sous forme de bulle :
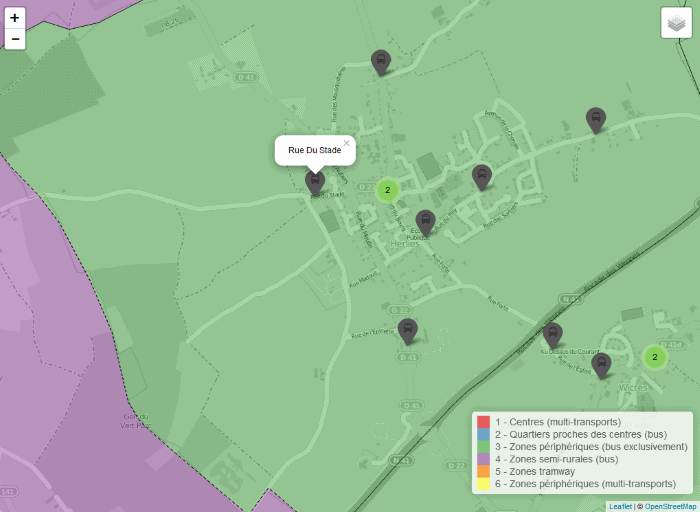
Il est aussi possible de choisir avec le menu en haut à droite d’afficher ou non les différentes couches de la carte.
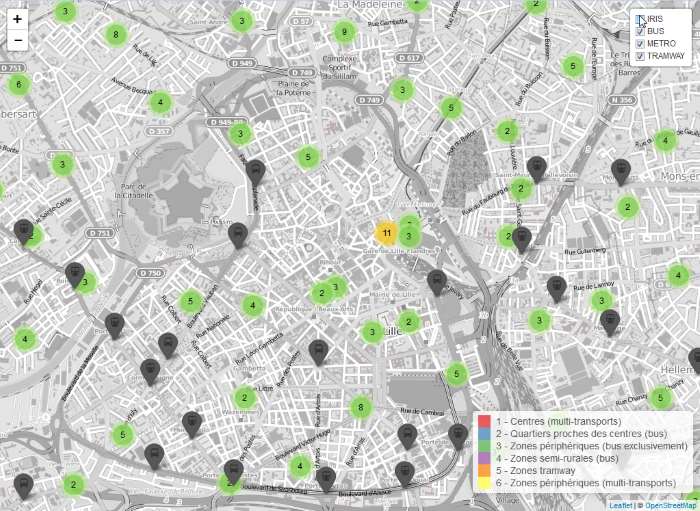
On a ainsi obtenu en quelques lignes de code un outil qui peut être déployé en ligne tel quel, ou s’intégrer à un outil aux contenus plus variés comme un tableau de bord.
La Data Science avec des données spatiales
Une fois les données rassemblées et représentées, les datascientists peuvent utiliser de multiples techniques et résoudre des problématiques :
- d’offre et de demande (où la demande n’est-elle pas satisfaite ?)
- d’autocorrélation spatiale (est-ce que deux entités géographiques proches évoluent de la même façon ?)
- d’interpolation de données (estimation de données de proche en proche, lié à l’autocorrélation)
- de classifications spatiales
- d’analyses de réseaux (routes, etc.)
C’est donc un nouveau « terrain de jeu » qui s’ouvre pour de nombreuses entreprises.


![[Data Rider] REX Collecte de données IoT – Étape 1 : Initier la collecte](https://fr.blog.businessdecision.com/wp-content/uploads/2025/05/data-rider-rex-collecte-donnees-1024x512-1.jpg)











Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.