
A l’occasion d’un projet d’analyse des logs de web services réalisé pour un client, nous avons été amené à tester MongoDB… et j’avoue que je suis tombé sous le charme de cet outil aussi simple que puissant. Décryptage de ce béguin soudain.
Prise en main ultra-rapide de MongoDB
MongoDB est une solution Big Data de type NoSQL. Elle est cependant fortement scalable et ne nécessite pas de schéma prédéfini pour les données. C’est une solution orientée document : dans MongoDB, pas de tables mais des collections, pas de lignes mais des documents.
L’installation est très simple … même sur Mac. Il suffit d’avoir le gestionnaire de package Homebrew et de taper:
> brew install mongodb
Pour lancer MongoDB, ce n’est guère plus compliqué. Il suffit de lancer la commande suivante dans un terminal.
> mongod --dbpath <path to data directory>
La commande lance le serveur. Il ne reste plus qu’à y accéder avec un client en tapant la commande suivante dans un terminal.
> mongo
Pour accéder ou créer une nouvelle base de données :
> use mydb
Pour visualiser des collections :
> show collections
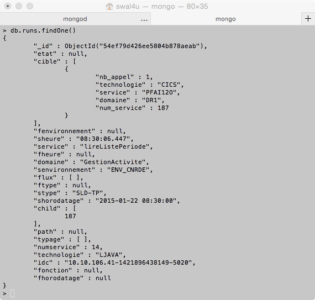
Pour visualiser un document :
> db.collectionname.findOne()
Pour rechercher des documents :
> db.collectionname.find({query})

Est-ce l’attrait de cet écran rempli de signes mystérieux qui m’a attiré ? Peut-être…
Mais un autre élément m’a définitivement conquis.
La librairie Python Pymongo
Je vous ai déjà dit que j’adorais Python ? Python, c’est un peu mon langage ultime, très simple, sans fioriture, et avec une ribambelle de librairies pour faire plein de choses sympa comme du calcul scientifique avec numpy ou du machine learning avec sci-kit-learn.
Figurez-vous que justement, il existe une librairie dédiée pour MongoDB : pymongo.
Je dispose de l’environnement de développement Anaconda. Pour rajouter le module, il suffit de taper:
> conda install pymongo
Que peut-on faire ensuite ? Presque tout…
Il suffit tout d’abord de préciser la librairie en début de programme et d’indiquer la base (dans mon cas, « mydb ») que l’on souhaite utiliser.
On accède aux collections simplement en préfixant leur nom par db. (ici: « db.services » par exemple)

Dans le cadre de mon projet, les données sources contenaient des structures imbriquées qui se prêtaient bien à un stockage document mais le fichier source n’était pas exploitable directement. Il était nécessaire au préalable de le « parser » pour récupérer les informations utiles.

Mais on peut aller plus loin puisqu’il est possible de formater du coup comme on le souhaite le document MongoDB que l’on va insérer.
![]()
Des fonctionnalités XXL
Si on maîtrise la structure du document que l’on insère, on facilite alors d’autant les requêtes que l’on pourra faire par la suite. Dans mon cas, les données de nature technique portaient sur des web services qui appelaient d’autres web services, créant ainsi un parcours difficilement analysable avec une base relationnelle. Les bases graphes semblent plus intéressantes sur ce point. Cependant, elles gèrent moins bien les informations imbriquées et nécessitent de faire des choix structurants sur la modélisation.
En créant une variable spécifique « path » dans chaque document, il devient possible de faire une requête des données pour obtenir des informations sur les chemins empruntés (avec des requêtes de type « chemin qui contient … » ou encore « chemin qui débute par … »)

Exemple de requête de type « chemin qui contient … »
On peut lister les chemins mais on peut aussi les compter.

Exemple de requête de comptage avec un filtre de type « chemin qui débute par … »
MongoDB offre bien d’autres possibilités de requêtes comme des requêtes d’agrégation. Dans l’exemple suivant, je calcule le nombre de services lancés par environnement.

Conclusion
Cette solution est vraiment séduisante et je dois avouer qu’il est bien difficile de lui résister. Va-t-on aller plus loin et se mettre en couple ? Sûrement, cependant il faudrait au préalable voir ce que donne cette relation au quotidien. Et voir, en outre, si les performances dans une architecture de type cluster sont au niveau des fonctionnalités que l’on a pu entrevoir au cours de cette brève rencontre.


![[Data Rider] REX Collecte de données IoT – Étape 1 : Initier la collecte](https://fr.blog.businessdecision.com/wp-content/uploads/2025/05/data-rider-rex-collecte-donnees-1024x512-1.jpg)











Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.