
Si vous baignez dans l’univers de la Data depuis un certain temps, vous avez sûrement croisé ces termes énigmatiques : Data Lake, Data Warehouse, Data Lakehouse et Data Mesh. Vous aimeriez bien démêler ce jargon anglophone et comprendre les concepts qui se cachent derrière ? Ou peut-être les maîtrisez-vous déjà sur le bout des doigts, mais vous vous demandez toujours comment les expliquer à des personnes non initiées ?

Salon de la Data et de l’IA
Quelle que soit votre situation, cet article devrait vous intéresser. Je vais vous présenter de manière concise les définitions et les concepts de Data Lake, Data Warehouse (et Data Mart), Data Lakehouse et Data Mesh. En outre, pour faciliter votre compréhension et vos futures explications, je vous proposerai une analogie pertinente pour chaque concept.
Préparez-vous à plonger dans les profondeurs fascinantes du monde des données ! C’est parti !
Data Lake (Lac de données)
C’est un espace dans lequel l’entreprise stocke l’ensemble de ses données structurées et non structurées. L’objectif est de centraliser les données du SI de manière rapide et efficace pour ensuite faciliter les découvertes, les croisements et réduire le temps entre l’expression d’un besoin et sa réalisation.
Le Data Lake est associé à l’univers du Big Data puisqu’il est généralement volumineux (on parle en Téra et en Péta), varié (structuré, semi-structuré, non structuré) et parfois avec une forte vélocité (Streaming, IOT). Les données sont gardées dans leur version d’origine (brutes) et également dans une version préparée (normalisation, enrichissement, …) afin de faciliter leurs usages. Souvent, les données enrichies sont précalculées dans le Data Lake puis envoyées dans le Data Warehouse pour une plus grande facilité d’usage.
💡 Analogie avec le lac d’Annecy

Imaginez un grand lac entouré de montagnes, par exemple le lac d’Annecy. Les montagnes représentent vos différentes applications (capteurs IOT, base de données opérationnelle, CRM, application Web, …). De ces montagnes coulent plusieurs rivières telles que l’Eau-Morte, l’Ire et le Laudon. Chaque rivière est un flux de données provenant d’une application qui vient alimenter votre Data Lake. On peut avoir des cours d’eau (peu de volume), des fleuves (gros volume), des rivières calmes (alimentation Batch) et des rivières avec un fort courant (Streaming). Les rivières font voyager des poissons (données structurées), mais transportent également des débris et divers matériaux résiduels (données non structurées).
Maintenant, imaginez que vous vous équipez pour faire de la plongée dans ce lac afin d’explorer ses profondeurs à la recherche de beaux poissons ou de trésors cachés ! Ou encore mettez-vous dans la peau d’un pêcheur qui va regarder sa prise, analyser la taille du poisson et son espèce. Selon sa qualité, il va le relâcher ou bien le garder pour le consommer.
Data Warehouse (Entrepôt de données)
C’est un espace centralisé dans lequel l’entreprise stocke l’ensemble de ses données structurées à des fins d’analyse et de reporting. Il contient une vision de l’état courant (plus ou moins en temps réel), mais également un historique sur certaines données. Les données sont organisées en fonction des usages et répondent donc à des besoins précis pour optimiser les requêtes effectuées dessus.
Le Data Warehouse peut être alimenté à partir d’un Data Lake ou bien directement depuis différents systèmes du SI avec un travail de préparation à effectuer en amont.
💡 Analogie avec un supermarché

Imaginez le Data Warehouse comme votre supermarché, celui dans lequel vous faîtes vos courses, et où les produits sont répartis dans les rayons, et regroupés ensemble par type (les pâtes, les différents riz, les sauces, …). Tout est bien rangé et organisé pour faciliter la vie de l’acheteur mais surtout lui donner envie de consommer.
Les produits frais sont régulièrement remplacés. La date de péremption est différente selon les produits, mais lorsqu’elle est dépassée, les produits sont enlevés des rayons.
Mais les supermarchés sont très grands, et ce n’est pas toujours simple de s’y retrouver. C’est pour cette raison qu’ils sont organisés par rayon (les Data Mart).
Data Mart (Magasin de données)
C’est un sous-espace du Data Warehouse. C’est un découpage souvent organisationnel pour répondre aux besoins spécifiques de différentes entités d’une organisation.
💡 Analogie avec un supermarché (bis 😉)

Retournez dans votre supermarché préféré, et focalisez-vous sur l’organisation et le découpage en secteurs, puis en rayons. Il y a le coin des fruits et légumes, la zone des produits laitiers ou encore des surgelés. Un secteur correspond dans notre exemple à un Data Mart. Selon le secteur, on comprend bien que l’organisation des rayons (ou de nos données) est bien différente pour s’adapter aux produits et à leur consommation. Les fruits et légumes sont présentés sur de beaux étals, les produits laitiers dans des réfrigérateurs géants, et les féculents en rayons sur plusieurs étages.
Pour vous aider à vous repérer dans votre magasin, il y a des panneaux au plafond pour indiquer les différents secteurs, et sur chaque rayon encore un panneau pour indiquer la catégorie des produits présents, et parfois dans les rayons des petits panneaux pour séparer chaque type de produit. Et pour finir, des informations détaillées sont disponibles sur les produits en eux-mêmes. J’en profite pour faire un clin d’œil à la Data Gouvernance qui n’est pas abordé dans cet article mais qui reste indispensable au sein d’un SI pour le maitriser et faciliter son bon usage.
Data Lakehouse (Plateforme de données)
C’est la combinaison du Data Lake et du Data Warehouse ! L’objectif est d’associer le meilleur de ces 2 solutions pour maximiser les performances, minimiser les coûts, gagner en agilité et réduire le time to market ! Mais concrètement, qu’est-ce que cela signifie ?
Il s’agit généralement de solutions dans les nuages (on emploie le plus souvent en anglais, Cloud 😉) qui séparent la partie stockage de la partie traitement. Ainsi, il est possible de stocker des données brutes, structurées ou non à bas coûts. On peut également faire des traitements de préparation et enrichissement des données, et de les remettre à disposition sur le même stockage. Finalement, c’est ce qui est fait déjà sur un Data Lake, me direz-vous ? Oui ! La nouveauté, c’est que ces données (structurées) sont accessibles directement en SQL et ce, de manière performante (ce qui n’était pas le cas sur un Data Lake Hadoop avec Hive, ou coûteux avec Impala). Un autre avantage est la non-duplication des données puisque tout est centralisé. Précédemment, on stockait les données dans le Data Lake, puis une partie en double dans le Data Warehouse.
Chaque Cloud propose sa solution de Data Lakehouse, mais d’autres solutions non hyper-scaler locking sont également disponibles :
• GCP avec Google Big Query
• Azure avec Azure Synapse Analytics
• AWS avec Amazon Redshift
• Snowflake
• Et Databricks
💡 Analogie avec un magasin de bricolage

Prenons l’exemple de votre magasin de bricolage préféré. Vous pouvez entrer dans le magasin et parcourir les rayons à la recherche de vos articles. Certains produits sont en rayon, d’autres sont même mis en scène, et d’autres encore ne sont pas directement disponibles dans le magasin. Pour les obtenir, il faut commander le produit et aller le récupérer quelques minutes après en sortie du dépôt. C’est un véritable progrès car auparavant, il fallait commander l’article et venir le chercher plusieurs jours après ou alors se le faire livrer.
On trouve également dans la cour des matériaux des sacs de béton tout prêt (déjà préparé), ou bien du sable et des graviers en tas dans lesquels on vient piocher (non préparé). A la fin on aura du béton dans les deux cas. Le premier aura nécessité un travail préparatoire en amont, pour ensuite nous faire gagner du temps et avoir un résultat connu d’avance. Pour le second, on se sert des ingrédients bruts qu’on agence et qu’on proportionne comme on le souhaite afin d’obtenir le béton désiré.
Avec le Data Lakehouse, c’est la même chose. On peut questionner les données structurées facilement, celles qui sont prévues et optimisées pour (et sans duplication), mais également les autres données structurées, même si elles ne sont spécialement prévues pour être requêtées, ce qui facilite l’analyse et l’exploration.
Data Mesh (Maillage de données)
Le Data Mesh va à l’encontre d’une centralisation et prône plutôt une fédération des données. Ainsi, les données d’une entreprise sont découpées en plusieurs espaces indépendants, mais communicants entre eux et avec une gouvernance commune. On parle donc d’un maillage entre plusieurs systèmes qui peuvent être des Data Warehouse, des Data Lake et Warehouse, ou des Data Lakehouse !
Au lieu de tout centraliser dans un seul gros système, on va donc avoir plusieurs petits systèmes qui devront être pilotés et qui vont s’échanger des données entre eux. Les interfaces d’échanges deviennent primordiales en interne, ce qui facilite également le partage externe. On retrouve donc une donnée distribuée volontairement car elle reste ouverte, partagée et gouvernée pour être facilement utilisable des autres systèmes. L’organisation, la gouvernance et les processus sont extrêmement important pour un fonctionnement en Data Mesh. On parle de produit (et de cycle de vie du produit) car la donnée devient un vrai produit à part entière et doit être traité comme tel dans l’entreprise.
💡 Analogie avec nos voitures personnelles
J’aime à comparer le Data Mesh à nos voitures personnelles. Chaque voiture a son conducteur (le pilote d’un produit), et transporte des passagers (les données). Pour que toutes les voitures puissent partager la route de manière de sécurisée, un code de la route, des panneaux de signalisation et de direction (gouvernance) a été mis en place. Et les voitures disposent de feux et du klaxon pour communiquer (contrat d’interface) avec les autres véhicules même s’ils sont différents.
💡 Analogie avec un orchestre

Pour cette dernière analogie, je vous propose de penser à un orchestre ! Il est composé de musiciens talentueux individuellement et jouant différents instruments. Chaque musicien suit sa partition, mais tous travaillent ensemble pour produire une harmonie musicale. Ils sont synchronisés par le chef d’orchestre pour garantir l’harmonie.
Dans une entreprise orientée data-driven avec le Data Mesh, il faut donc s’imaginer comme un orchestre où chaque système indépendant doit être à l’écoute des autres et ses synchroniser pour obtenir un système global performant et harmonieux garanti pour une gouvernance fédératrice.
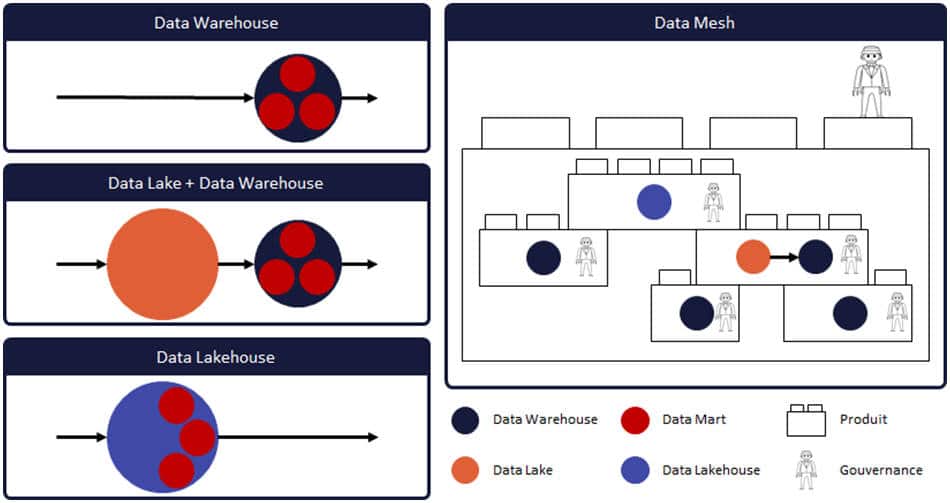
En résumé
Parce qu’une image vaut mille mots, j’ai créé cette illustration comme synthèse de cet article pour montrer le positionnement de chaque système par rapport aux autres.
J’espère que cet article vous a permis de mieux appréhender ces différents concepts. Et vous, dans votre entreprise, quel système est en place ? Nous pouvons vous accompagner pour le faire évoluer d’un Data Lake + Data Warehouse en Data Lakehouse ou bien pour vous aider à transformer votre SI vers une architecture Data Mesh ! Contactez-nous ou laissez-nous un commentaire sous cet article 😉
👉 Retrouvez toute notre actu en temps réel en nous suivant sur LinkedIn 👈














Commentaires (2)
Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.
Simple, clair et précis.
Bravo !