
Pétrole, or noir numérique, actif stratégique… Avec le Data Mesh, la donnée est considérée comme un produit. Charge aux domaines de données de gérer le cycle de vie de ces produits ainsi que de les partager et promouvoir à l’échelle de l’organisation. Cette structuration en data products est le deuxième des quatre piliers du Data Mesh.
Aujourd’hui, les entreprises les plus avancées travaillent sur la notion de Data Products. Elles missionnent alors pour les construire des entités telles que leur Data Factory, leur Data Office ou encore leur DSI.
Le Data Mesh va plus loin dans la généralisation de cette notion, en distribuant la réalisation des produits dans les domaines, mais aussi en considérant les données elles-mêmes comme un produit et non pas seulement comme une composante d’un produit numérique plus large. En exposant ainsi uniquement des produits de données et en fournissant les interfaces pour y accéder, le Data Mesh procure aux domaines consommateurs la responsabilité et la liberté d’analyser et de restituer les données au travers des services applicatifs les plus adaptés à leurs besoins et tenant compte des outils dont ils disposent.
Replay
Data Mesh : comment Spiderman établit les concepts clés des nouvelles architectures data ?
Lire la suiteAvec le Data Mesh, les données sont le produit
Remarque : Le Data Mesh distingue les notions de data product et de data as a product. Le data product (ou produit de données) se définit ainsi comme « un produit qui facilite un objectif final grâce à l’utilisation de données », c’est-à-dire le fait d’exploiter des données au sein d’un produit numérique. Le principe de data as a product (données en tant que produit), introduit par le Data Mesh est un sous-ensemble des data products dans lequel les données deviennent elles-mêmes le produit. Elles constituent alors la finalité et non pas seulement le moyen. Dans la suite du document, par logique de simplification, nous utiliserons le terme « data product » pour désigner des « data as a product ».

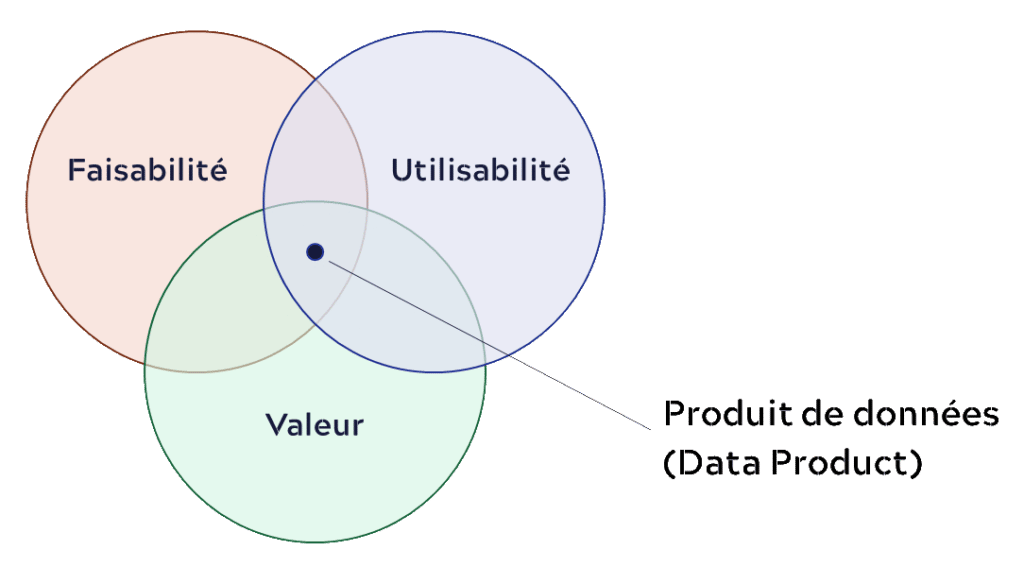
Avec le Data Mesh, les données deviennent donc littéralement le produit, consommable généralement sous la forme de dataset. Pour être efficaces, les data products doivent se conformer à un ensemble de caractéristiques qui les placent à l’intersection de l’utilisabilité, de la faisabilité et de la valeur (diagramme de Marty Cagan’s).
L’analogie avec une bouteille d’eau permet de préciser un peu plus encore les contours de ces données en tant que produits. Dans cette métaphore, les données sont l’eau. Pour être consommée, l’eau nécessite un contenant, la bouteille. Pour les données, ce sera généralement un dataset.
Cependant, elle mobilise aussi du marketing, des informations de composition, une notice d’utilisation, un lieu d’exposition ou de vente comme un rayon de supermarché ou une page produit d’un e-commerçant.
Avec le Data Mesh, les données deviennent littéralement le produit, consommable généralement sous la forme de dataset.
Un produit doit respecter six caractéristiques fondamentales
Dans la théorie du Data Mesh, un produit doit respecter six caractéristiques fondamentales. Celles-ci lui confèrent d’être :
- Découvrable : le produit est référencé dans un catalogue de données ou une marketplace et accompagné d’un ensemble de métadonnées visant à faciliter son exploration et son identification par les consommateurs à toutes les étapes de son cycle de vie.
- Adressable : gage de productivité, chaque data product est localisé à une adresse permanente et unique qui garantit la continuité de son exploitation par les domaines consommateurs quelle que soit son évolution au cours du temps et en conformité avec la politique d’accès.
- Documenté : la donnée est définie et documentée par le domaine au sein d’un catalogue fédéré pour garantir une compréhension et une interprétation claires et sans équivoque par les consommateurs (provenance, localisation, fraîcheur des données, sémantique, cycle de vie, modèle de données, etc.).
- Fiable : la qualité des données est mesurée et supervisée en continu par les domaines producteurs (communication d’indicateurs qualité) afin de rendre les produits fiables et pour s’assurer d’un niveau de confiance élevé des utilisateurs quant à leur exploitation.
- Interopérable : les produits reposent sur des standards communs, favorisant ainsi leur mise à disposition, réutilisation et croisement…
- Sécurisé : actif stratégique, la donnée est protégée en fonction du niveau de sensibilité et des habilitations (droit d’accès, authentification, chiffrement…).
Pour schématiser, un produit consiste généralement en un jeu de données ou dataset.
On distingue 5 grands types de data products :
- Les données brutes (raw data) issues directement d’une source de données. Seules quelques opérations élémentaires de traitement ou de nettoyage sont réalisées. Les domaines consommateurs sont alors totalement responsables de la valorisation des données fournies.
- Les données dérivées (derived data) qui peuvent être assimilées à des données brutes enrichies avec des données complémentaires sur la base d’un travail d’assemblage et de préparation réalisé par le domaine propriétaire. Les domaines consommateurs sont alors totalement responsables de la valorisation des données fournies.
- Les données résultant du traitement de données sources (brutes ou dérivées) par un algorithme (algorithme de recommandation, de scoring, de classification ou autre) conçu et réalisé par le domaine propriétaire. Les domaines consommateurs restent en charge de leur interprétation et de leur usage final.
- Les données d’aide à la décision qui sont des données analytiques actionnables, résultant de traitements potentiellement avancés. Si le domaine propriétaire est responsable de l’analyse des données, les domaines consommateurs restent en charge de leur interprétation et de leur usage final.
- Les données d’aide à la décision automatisée constituent un type similaire au précédent à ceci près que toute l’intelligence, incluant l’interprétation et l’actionnabilité, est placée sous la responsabilité du domaine propriétaire, les domaines consommateurs étant, dans ce contexte, limité à un rôle d’opérateur.
Mais pour être tout à fait exact, un data product est l’association d’un dataset, de la gouvernance associée, des moyens (process) nécessaires à sa construction, sa destination (analyse, communication etc.) et son packaging de diffusion. Il peut aussi prendre la forme d’un algorithme de data science, qui, mis à disposition sous forme d’API, peut être interrogé par les domaines. S’inspirant de la philosophie DevOps, un Data Product réunit les donnée, le code et l’infrastructure nécessaires.
Un produit peut également, et c’est même recommandé, exploiter d’autres produits de données. Un algorithme de scoring client fourni par le domaine e-commerce exploitera par exemple le produit “données client” mis à disposition par le marketing.
💡 5 grands types de data products
📌 Les données brutes (raw data)
📌 Les données dérivées (derived data)
📌 Les données résultant du traitement de données sources par un algorithme
📌 Les données d’aide à la décision
📌 Les données d’aide à la décision automatisée
Par ailleurs, afin d’être consommable en self-service, les produits nécessitent de recourir à des modes de mise à disposition standardisés, prioritairement via des API. D’autres formes de mise à disposition sont aussi possibles pour des besoins spécifiques (connecteurs, outil de data visualisation, studio Data Science, etc.) L’avantage de ces canaux est de permettre d’appliquer une gestion des habilitations pour maîtriser les accès aux données.
La gestion des produits nécessite également la mise en place de règles et de processus de gouvernance et de standardisation pour en favoriser les usages à l’échelle de l’entreprise.

Construire un Data Product : mode d’emploi et atouts
Au-delà des 6 caractéristiques incontournables du data product, la conception de ces produits repose sur des actions opérationnelles. Ainsi, il convient de choisir les sources de données, de les documenter, de détailler la chaîne technique de mise à disposition de la donnée (outils et méthodologies, fréquence de rafraîchissement, etc.) et ses modes de diffusion.
Pour des données météo par exemple, la diffusion peut s’opérer de manières très diverses : séries temporelles, courbes de tendance, calculs algorithmiques… À chaque mode de diffusion pourra correspondre des produits différents. Une même donnée peut être diffusée selon de multiples modalités en fonction de ses usages et des utilisateurs.
Cette approche présente différents avantages dont la standardisation des modes de distribution qui permet aux domaines de suivre finement la consommation et d’évaluer les besoins prioritaires.
🔎 Amadeus & Data Mesh : des centaines de Data Products
Fournisseur de solutions pour l’industrie du voyage (compagnies aériennes et ferroviaires, aéroports, hôtels, agences, tour-opérateurs…), Amadeus est engagé dans une approche Data Mesh. Yan Morvan (Cloud Data Platform principal engineer) et Damien Claveau (Data Platforms Operations lead engineer) ont fait le point sur les avancées de cette démarche à l’occasion du Salon Big Data & AI 2022.
Amadeus travaille ainsi parallèlement sur les quatre piliers : Gouvernance fédérée, automatisation de la Data Platform sur le cloud, organisation en domaines de données, mais aussi déploiement de Data Products. L’entreprise propose ainsi à ses clients internes et partenaires des centaines de produits de données directement consommables. Il s’agit, par exemple, de rapports de BI relatifs à des listes de réservations d’une compagnie agrégées en fonction d’indicateurs multiples.
Pour délivrer les Data Products, Amadeus a mis en œuvre des “workspaces applicatifs” indépendants qui sont rattachés à une application ou à une équipe de développement. Les workspaces contiennent les services d’analytics nécessaires à la transformation des données. Les applications de ces espaces sont connectées aux différents data stores du Data Mesh.
Comment mettre en œuvre l’approche Data Product ?
Ce pilier du Data Mesh peut s’avérer exigeant en termes de mise en œuvre, au même titre que le découpage par domaines. Il implique en effet une transformation de l’organisation avec une orientation affirmée vers l’agilité à l’échelle, que ce soit dans une déclinaison de type Spotify ou SAFe. La mise en place de telles organisations, reposant sur des tribus ou des squads, nécessite une forte implication des collaborateurs et une évolution en profondeur des modes de travail.
Si les départements du digital et de l’IT ont appris à déployer ces méthodologies, les métiers y sont en revanche peu familiers. L’adoption a toutefois vocation à être progressive. Les métiers peuvent en outre s’appuyer sur des équipes agiles localisées au sein de centre de compétences ou de services dédiés.
La conception et le cycle de vie des produits s’appuient sur une fonction-clé, celle de Data Product Manager. Rattaché à un domaine, il aura pour rôle de coordonner toutes les activités nécessaires pour le ou les produit(s) qu’il a en charge.
La conception d’un premier produit est l’étape initiatique clé. Elle contribue à la transformation en introduisant les principes de feuille de route produit et de MVP (Minimum Viable Product), tout en promouvant l’agilité et ses bénéfices. Elle encourage les producteurs à établir des priorités et donc à identifier les fonctions et produits les plus créateurs de valeur.
Le produit pilote portera idéalement sur un cas d’usage pertinent, qui nécessitera notamment d’accéder à des sources de données multiples, proches des métiers et jugées complexes d’accès dans l’entreprise.
La réalisation du produit est l’opportunité d’acquérir les compétences méthodologiques et organisationnelles. Mais pour prétendre à l’agilité, les domaines ont aussi besoin d’une plateforme et de services IT la rendant possible. C’est tout l’enjeu du 3e pilier du Data Mesh : la Self-service Data Infrastructure as a Platform.
💡 Ce qu’il faut retenir
📌 6 caractéristiques pour les produits de données : découvrable, adressable, documenté, fiable, interopérable et sécurisé
📌 Des standards de mise à disposition (API, marketplace…)
📌 Adoption progressive de l’agilité à l’échelle
📌 Une démarche initiatique clé : la conception du premier produit
📌 Développement et consommation facilités par la plateforme
👉 Retrouvez toute notre actu en temps réel en nous suivant sur LinkedIn 👈
Cet article a été rédigé en collaboration avec Christophe Auffray.








![[Data Rider] Booster Mario Kart à l'IoT et à l'IA – Étape 3 : écoconduite et consommation électrique](https://fr.blog.businessdecision.com/wp-content/uploads/2024/08/data-rider-ecoconduite-1024x512-1.jpg)




Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.