
D’année en année, les entreprises ont fait évoluer leur architecture de données pour faire face à des besoins croissants et à une création de valeur toujours plus forte. Elles sont ainsi passées d’une architecture monolithique dédiée à la Business Intelligence à des solutions orientées Big Data. Aujourd’hui, de nouvelles solutions basées sur le cloud et la virtualisation des données proposent de nouvelles approches.Tour d’horizon des courants d’architecture data avec le Data Warehouse, le Data Lake et le Data Mesh.
Enjeux d’une architecture de données
L’architecture de données désigne la manière dont une entreprise organise ses données. Avoir une architecture de données solide permet une meilleure utilisation des données disponibles. Toute organisation data-driven doit se soucier de la construction et de la maintenance d’une architecture pérenne.
Il est donc primordial de bien comprendre les concepts de base des architectures de données. Passons en revue leur évolution.
Data Warehouse (années 1990) : centraliser les données opérationnelles
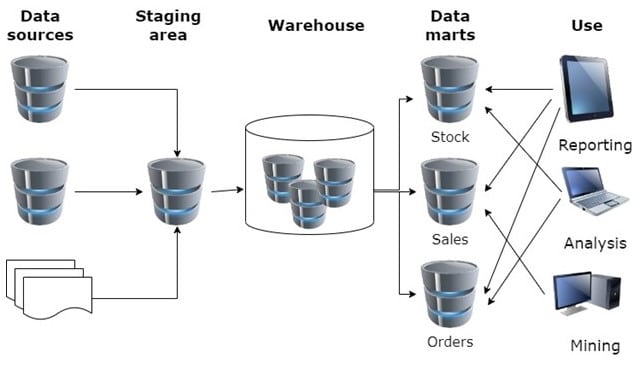
Dans les années 90, les entreprises ont construit leurs systèmes d’information décisionnels pour centraliser leurs données opérationnelles. On ne traitait alors que des données structurées. L’ETL (Extract, Transform, Load) est l’ensemble d’outils qui réalisent les trois fonctions : extraction de données des différentes sources, transformation des données extraites et enfin chargement des données transformées dans le Data Warehouse. Les données sont enfin présentées par domaines fonctionnels, les datamarts. Le datamart est un sous-ensemble de données spécialisé dans un unique métier, ou un thème.
L’utilisation d’un Data Warehouse présente de nombreux avantages évidents comme la cohérence et la qualité des données, ainsi que la facilité des analyses historiques.
Les données sont hébergées dans des bases de données relationnelles pour fournir de la donnée adaptée aux besoins de la Business Intelligence. De la gestion de la clientèle à l’intelligence artificielle, les domaines d’usage des Data Warehouses sont nombreux.
Data Lake (années 2010) : stocker les données brutes
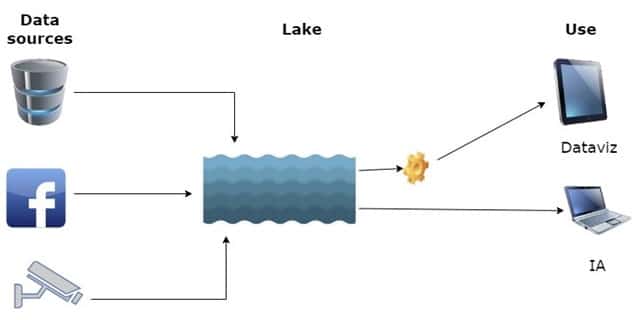
Avec les années 2000, l’entreprise doit faire face à un véritable déluge de données (le Big Data), au besoin de données non structurées (c’est-à-dire des données stockées sans format prédéfini : emails, images, vidéos…), au besoin de données en temps réel (pour prendre des décisions rapides et proactives).
Cette révolution conduit à la création d’un Data Lake, où les données sont stockées dans un format brut. Ce n’est que lorsque les données sont lues en vue d’un traitement qu’elles sont adaptées ; on ne parle alors plus d’ETL (Extract, Transform, Load) mais d’ELT (Extract, Load, Transform).
Le coût de stockage des données baisse, mais leur accès se complexifie.
Data Lakehouse (années 2020) : réunir Data Warehouse et Data Lake
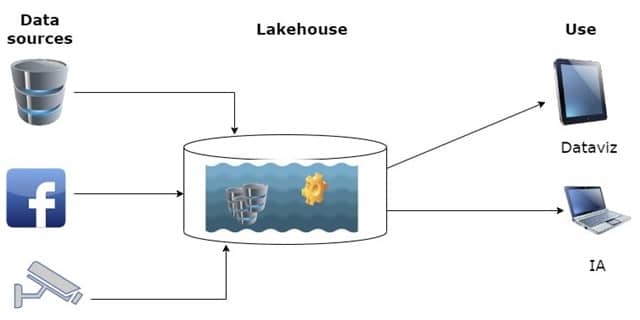
Depuis quelques années, des réflexions pour concilier la flexibilité et le coût réduit du lac de données avec les capacités analytiques de l’entrepôt de données ont conduit à une nouvelle architecture de données connue sous le nom de Data Lakehouse.
Le Data Lakehouse cherche à réunir Data Warehouse et Data Lake, et n’en garder que le meilleur pour surmonter leurs limites respectives. Le Data Lakehouse implémente les structures de données du Data Warehouse et les fonctionnalités de gestion du Data Lake, qui sont moins coûteuses.
Parmi les principaux Data Lakehouse du marché, on doit citer ceux proposés par le trio des Cloud Service Providers que sont AWS, Azure et GCP, construits respectivement autour de Amazon Redshift, Azure Synapse Analytics et Google Bigquery.
On ne doit pas oublier non plus les agnostiques comme la Cloud Data Platform de Snowflake, ou encore le Delta Lake de Databricks.
Muer sans changer d’architecture
Data Warehouse et Data Lake sont des architectures centralisées, avec des inconvénients majeurs : elles manquent de flexibilité, se heurtent au manque de connaissance des équipes data, avec pour conséquence une lenteur de la réponse aux demandes des métiers.
Cependant, il est possible de résoudre ces problèmes sans changer d’architecture physique. Il ne s’agit dès lors plus de migrer (d’une architecture vers une autre), mais de muer.
Le Data Mesh laisse une autonomie aux métiers
C’est ainsi qu’est née l’idée et le concept du Data Mesh, qui n’est pas à proprement parler une architecture mais plutôt une approche décentralisée et fédérée pour la gestion des données analytiques : pas de lourdeur due à une plateforme centrale, une compréhension de la donnée par le métier, et une autonomie laissée aux métiers pour utiliser les outils qui leur conviennent.
Un Data Mesh peut par exemple se baser sur un, voire des Data Warehouse(s), laissant ainsi à chaque métier une parfaite autonomie.
Combiner Data Mesh et virtualisation
Le modèle virtuel implémente une couche sémantique et cache au consommateur de données la complexité des systèmes sous-jacents. La virtualisation des données permet aux domaines de créer rapidement des silos de données en créant de manière itérative des modèles virtuels jusqu’à ce que les besoins de l’entreprise soient satisfaits.
Ce modèle, aussi dénommé Logical Data Warehouse ou Virtual Data Warehouse, est considéré par certains comme la prochaine génération de Data Warehouse. Ses composants peuvent être combinés et recombinés de manière logique plutôt que physique. Il peut prendre en charge une grande variété de sources de données.
Il y a trois ans déjà, Gartner voyait dans la virtualisation une voie mature pour le data management à l’échelle de l’entreprise.
Denodo est aujourd’hui le leader de la virtualisation des données, grâce notamment au service de données à la demande (« Data as a service »), à des automatismes et à la gouvernance intégrée.
Data Hub
Le Data Hub est une plateforme de stockage de données virtuelles. Il déplace et intègre physiquement des données multi-structurées provenant de diverses sources, pour les stocker dans un répertoire central et unifié. De ce fait il est LE point unique de vérité, ce qui facilite la gouvernance des données.
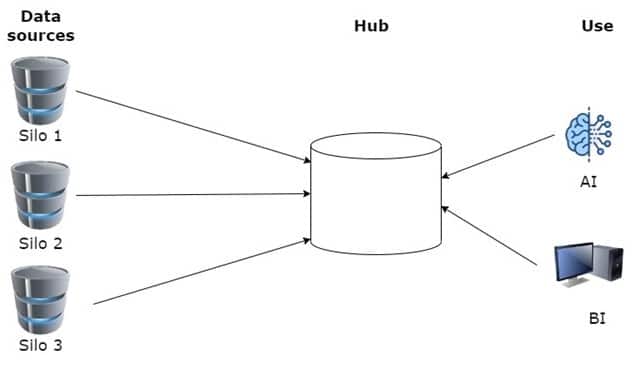
Le data hub harmonise les données qu’il ingère des différents silos puis les indexe, offrant des requêtes plus rapides. Contrairement au Data Warehouse, le Data Hub offre des données de qualité en temps réel. Et contrairement au Data Lake, il n’est pas nécessaire d’avoir une connaissance parfaite du SI.
Le Data Warehouse n’a pas dit son dernier mot
On a vu les avantages que proposent les solutions basées sur le Data Mesh et les nouvelles approches technologiques du cloud et de la virtualisation.
Mais le Data Warehouse n’a pas dit son dernier mot et conserve des avantages sur ses challengers :
- Les performances des requêtes analytiques sont meilleures dans un Data Warehouse car les données y sont « prémâchées »
- Le reporting sur un Data Warehouse n’affecte pas les performances des systèmes opérationnels
- Les fonctions liées à la qualité des données d’un ETL permettent de prendre en charge les exigences les plus complexes
Les systèmes d’information de nos entreprises sont de plus en plus complexes, et les architectures continuent d’évoluer à l’image de tous les nouveaux usages de la donnée.
Gageons que de plus en plus d’entreprises iront vers le Data Mesh et les données en libre-service, mais méfions-nous des projections hâtives : NoSQL n’a pas tué le Data Warehouse, et l’IA continue de nécessiter beaucoup de préparations de données…
Il n’y a donc pas de solution unique et on peut affirmer que différentes approches et architectures vont continuer de cohabiter pour répondre aux besoins de valorisation des données des entreprises.
👉 Retrouvez toute notre actu en temps réel en nous suivant sur LinkedIn 👈


![[Data Rider] REX Collecte de données IoT – Étape 1 : Initier la collecte](https://fr.blog.businessdecision.com/wp-content/uploads/2025/05/data-rider-rex-collecte-donnees-1024x512-1.jpg)











Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.