Le Mlops reste un sujet chaud de cette année. En effet, de nombreux défis demeurent à surmonter pour aller vers une chaîne d’industrialisation de l’IA complètement automatisée. Le MLOps est la clé pour tirer les bénéfices de la valeur créée par le Machine Learning. Pour faire simple, le MLOps va faire la jointure entre l’idée qui émerge de la tête d’un Data Scientist jusqu’à la mise en œuvre d’un modèle auprès des décisionnaires. Cet article présente nos travaux de construction d’une chaîne Mlops infusée aux outils open-source.
Le MLOps : un savant mélange de DevOps et de Machine Learning
Le MLOps consiste en de nombreuses techniques mêlant le DevOps, le ML et une bonne dose de coopération.
Si vous disposez de vos propres serveurs / infrastructure et que vos équipes baignent dans les outils Open-source, cet article est fait pour vous.
Le MLOps IaaS (Infrastructure As A Platform) pourrait paraître plus complexe à mettre en œuvre en raison des nombreux outils nécessaires. Mais cette apparente contrainte offre une capacité d’adaptation plus grande que les outils éditeurs et Cloud. On y trouve notamment l’opportunité d’adapter une chaîne MLOps à votre degré de maturité dans l’IA, que nous aborderons plus tard.
Un peu de contexte
La naissance d’un cas d’usage en Data Science commence souvent par une expérimentation sur un poste en local. Une installation fraîche avec les dernières versions d’outils, des développements et des expérimentations multiples pour atteindre un modèle performant. Mais la réalité vient brusquement mettre un coup de frein à main lorsqu’il s’agit de pousser le modèle en production. “On ne va pas envoyer le pc chez le client”.
Elle revêt le sujet aussi sérieux que complexe de l’industrialisation de l’IA. Derrière la réalité dépeinte précédemment, plusieurs constats sont applicables. Tout le monde ou presque aujourd’hui connaît la statistique des 88% des modèles d’IA qui ne dépassent pas la phase de POC. Plusieurs raisons expliquent cette statistique, que le MLOps promet de réduire drastiquement.
Le premier constat porte sur la récence de l’IA et les pratiques en Data Science au sein du monde de l’informatique. L’intégration des équipes de Data Scientists au SI peut s’avérer difficile tant les pratiques divergent, mais aussi parce que le Machine Learning (ML) est un domaine spécifique. Le ML n’a rien à voir avec les métiers de l’infra. Le point de jonction entre les deux domaines du ML et de l’Infra repose sur le code. Ce n’est pas aussi simpliste, mais pour résumer nous pouvons dire que les Data Scientists produisent le code, et l’infra le déploit. Le second constat est que les pratiques des Data Scientists restent obscures du point de vue des équipes Infra. Comment coopérer sur des domaines distincts ?
L’enjeu du MLOps : donner les outils et la capacité à coopérer
C’est là tout l’enjeu du MLOps : donner les outils et la capacité à coopérer. Plus subtil, la coopération se réalise via les outils mis à disposition. En effet, la standardisation des environnements de développements, l’ajout d’automatisation et de sécurisation via le CI/CD (Continuous Integration/Continuous Delivery) côté Infra. Et par la mise en place de tests et de bonnes pratiques de développement côté Data Science.
Pour faire encore plus simple, l’infra va offrir aux Data Scientists des outils (Docker) que nous pouvons comparer à des boites dans lesquelles ils vont mettre leurs travaux. Les Data Scientists auront tout le loisir et la liberté d’utiliser ce que bon leur semble (packages Python, Tensorflow, JupyterNotebook…). Ensuite, le CI/CD va agir comme un service postal. Pour la comparaison, les DevOps seront les postiers logisticiens qui ont construit le parcours des colis. De sorte que ces colis passent par une ligne logistique automatisée et y ajouter un supplément sécuritaire avant qu’ils n’arrivent à destination.
Bien évidemment, une telle chaîne ne se construit pas du jour au lendemain. Prenez une grande inspiration, nous vous expliquons tout.
Machine Learning : La question de la maturité
La question de la maturité s’aborde selon plusieurs perspectives.
La première consiste à se positionner entre vos besoins et le niveau d’intégration de la Data Science dans votre entreprise.
La seconde est le processus de construction d’une chaîne MLOps. En effet, c’est un nouveau paradigme qui demande un investissement dans le temps pour prendre en main et intégrer une chaîne MLOps. Il faut le voir comme une montée en compétence des équipes sur les processus et l’orchestration des composants de l’infrastructure.
Google a rédigé un article sur le MLops maturity level qui explique très clairement le positionnement.
Nos experts sauront vous aider à définir la chaîne MLOps en fonction de votre maturité et de vos besoins. D’une chaîne frugale pour de l’analyse jusqu’à une architecture complexe, ils vous guideront dans l’éventail des solutions intermédiaires.
Dans la partie qui suit, nous faisons le parallèle avec la seconde perspective (intégration du MLOps) dont il est question plus haut.
Chaîne MLOps : la question des outils
A présent, nous nous focalisons sur les outils qui composent notre chaîne MLOps. Nous détaillerons l’utilité des outils en expliquant leur rôle.
Dans un premier temps, nous avons mis en place une configuration locale de MLflow pour apprendre les concepts du MLOps et prendre en main l’outil (montée en compétence). Dans un second temps, nous sommes passés à la construction de la plateforme qui est le sujet de cet article.
L’outil MLflow a de nombreuses fonctionnalités de gestion du cycle de vie d’un modèle. Comme nous pouvons le voir dans la figure ci-après, MLflow dispose d’un éventail quasi complet des fonctionnalités inhérentes au MLOps :
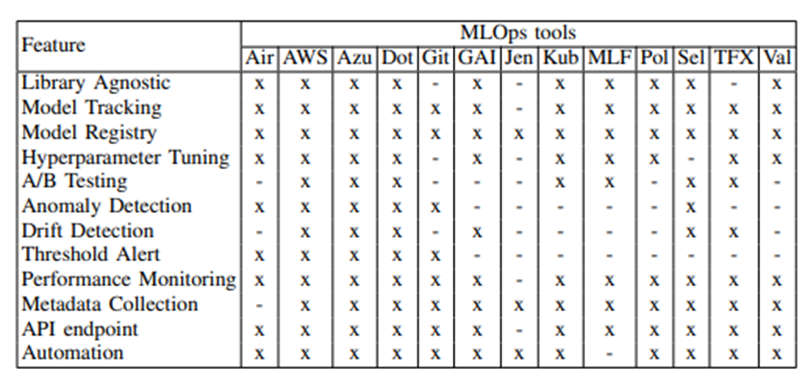
Nous le verrons plus tard, les composants manquants (Détection d’anomalie, du drift, seuil d’alerte, automatisation) ont été implémentés de sorte à obtenir une chaîne complète telle qu’elle est définie dans l’article cité ci-dessus.
La standardisation des environnements de développement des Data Scientists est possible par la technologie Docker. C’est la première étape vers l’industrialisation. Docker est un outil de virtualisation qui facilite l’industrialisation des projets informatiques. La solution Docker est conçue de sorte qu’un processus dockerisé est isolé, portable et reproductible.
L’isolation jour un rôle dans la standardisation des environnements et contribue à la sécurisation de la plateforme au sens large. La portabilité est un concept relatif à Docker dans le sens où un processus conteneurisé peut être transmis, ce qui est d’autant plus pratique du fait de la légèreté d’un conteneur (moins d’1Go la plupart du temps). Enfin, grâce au cumul des caractéristiques précédentes, un processus dockerisé est reproductible.
Sans entrer dans plus de détail, nous pouvons voir Docker comme un outil qui met en boîte un service et son projet, nous parlons alors de conteneurisation. Nous utilisons un service de base (dans notre cas, nous conteneurisons Python, MLflow…), que nous appelons “image” dans la terminaison Docker. En l’occurrence ici, nous utilisons un service Python auquel nous ajoutons le code d’un modèle de ML.
L’image Python est disponible auprès des Data Scientists comme sur étagère sur Gitlab. L’image de base est la même pour tous. Le Data Scientist a la liberté d’ajouter les packages Python dont il a besoin. La source unique d’une image fait écho à la standardisation et à la sécurisation.
Le Data Scientist récupère l’image Python sur son poste pour développer. Nous préconisons l’utilisation de VsCode puisque l’outil offre des extensions pour développer à l’intérieur de conteneurs Docker : DevContainer. L’utilisation d’environnements de développement standardisés permet de s’affranchir des configurations locales souvent très hétérogènes et qui rendent un projet difficilement reproductible et donc difficilement industrialisable. Le développeur va pouvoir constituer son code et pouvoir lancer ses premières expérimentations.
MLflow, où comment assurer la traçabilité de nos expérimentations
C’est à ce moment que MLflow entre en jeu. Il suffit d’ajouter quelques lignes au code de ML. Elles vont permettre d’interagir avec MLflow pour consigner les expérimentations, les paramètres du modèle, les résultats. Mais aussi et surtout les indicateurs de performance du modèle que nous pouvons choisir et implémenter librement. MLflow va conserver les modèles dans le Model Registry et les métriques en base de données. Depuis l’UI MLflow, nous pouvons parcourir l’historique des expérimentations et ranger les modèles en fonction de leurs indicateurs de performance afin de sélectionner le meilleur.
Du point de vue de l’architecture, MLflow va créer un certain nombre d’artefacts qu’il convient de ranger à la bonne place. Les artefacts d’un modèle sont des fichiers non-structurés (.json, .pkl…). Nous les enregistrons dans un compte de stockage d’objets Blob sur Azure pour les besoins de l’exercice. Les métriques associées aux modèles sont des données structurées qui sont stockées dans une base de données PostgreSQL. En effet, MLflow va lire ces métriques pour les afficher dans son interface à partir du backend-store PostgreSQL que nous avons configuré. MLflow est la pièce centrale dans la mesure où il centralise les informations de plusieurs ressources (Tracking Server).
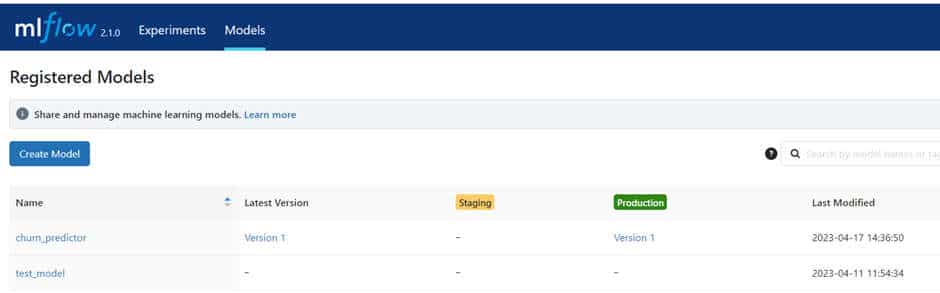
MLflow : notre processus
Les parties précédentes nous ont permis de capter une partie de la chaîne. En effet, jusqu’à présent, nous n’avions qu’un environnement de développement. C’est-à-dire une instance de MLflow, une équipe de développeurs et un seul serveur. Mais cette configuration pose de nombreux problèmes dans la mesure où un seul environnement n’est pas dans une logique d’industrialisation.
Comment allons-nous gérer la présence d’un second environnement ? Comment l’ajout d’un environnement va impacter le processus MLOps ?
Pour les besoins de l’exercice, nous avons créé un second environnement que nous avons appelé “Production” [1]. L’ajout d’un nouvel environnement va ainsi permettre de dissocier l’espace de développement de la production. Cela offre la possibilité d’ajouter un cran de sécurité afin de pouvoir maîtriser le déploiement des modèles et de s’inscrire dans les SI.
Il faut que nous parlions des problèmes que nous avons rencontré à ce stade. La mise en place d’une instance unique de serveur reste relativement simple à mettre en œuvre en suivant la documentation. Toutefois, nous avons dû repenser notre façon de concevoir une chaîne de MLOps. En effet, il n’existait que très peu de ressources pour nous aider construire une telle chaîne en 2022. Il existe plusieurs pistes sur lesquelles raisonner :
- Utiliser les artfeacts créés en développement en production ?
- Avoir une seule instance de MLflow branchée sur tous les environnements ?
Faire transiter des artefacts consisterait à automatiser la copie d’artefacts d’un espace vers un autre. Mais le modèle a une vision développement et risque de réagir différemment en production. Il faudrait migrer les données PostgreSQL aussi ?
Une seule instance pour plusieurs environnements, la gestion des droits serait complexe et la solution relativement peu sécurisée.
Pour vous épargner les tortueuses questions, en fin de compte, ce qui fait foi, c’est le code.
En réalité, l’espace de développement est davantage un espace pour l’expérimentation. A partir de sous échantillons de données, il est tout à fait envisageable de construire le code, les tests de code, mais aussi de tester le modèle lui-même avec des tests. Tout cela contribue à fiabiliser la qualité du code et du modèle. Ce sera sur l’ensemble des données disponibles en production que nous pourrons entraîner le modèle.
C’est le passage d’un environnement à un autre qui permet à une chaîne d’être réellement qualifiée de MLOps. L’espace entre se révèle être une cassure.
Gitlab va jouer un rôle indispensable à notre chaîne Mlops. Plus particulièrement le CICD avec Gitlab CI afin d’automatiser le processus.
L’étape de l’industrialisation
Entrons à présent dans l’étape de l’industrialisation.
De la même façon, nous sommes partis d’un cas d’usage sur l’attrition bancaire.
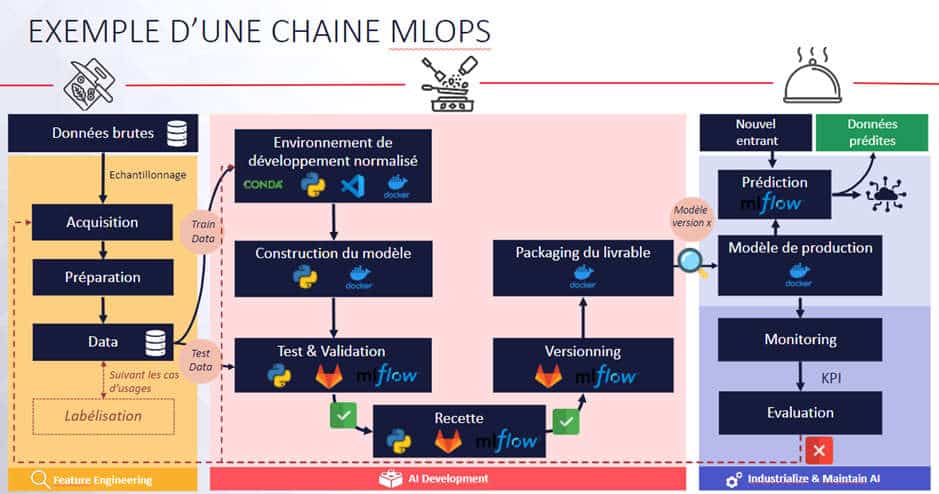
Chaine de CI/CD (tests, build image docker, model registry…)
Nous pouvons conteneuriser le code du modèle dans l’image Python à partir de Gitlab CI. Mais nous allons aussi pouvoir construire l’essence même du MLOps, à savoir un pipeline de CI/CD. Celui-ci embarque les tests (qui visent à répondre au besoin de fiabilisation du code, du modèle) et permet de répondre à la fiabilisation de la chaîne elle-même.
En outre, cela résout le tracas de la séparation entre les environnements. Seul le code est transmis à l’autre environnement grâce à notre modèle empaqueté par Docker, et porté par Gitlab CI. A chaque environnement ses instances !
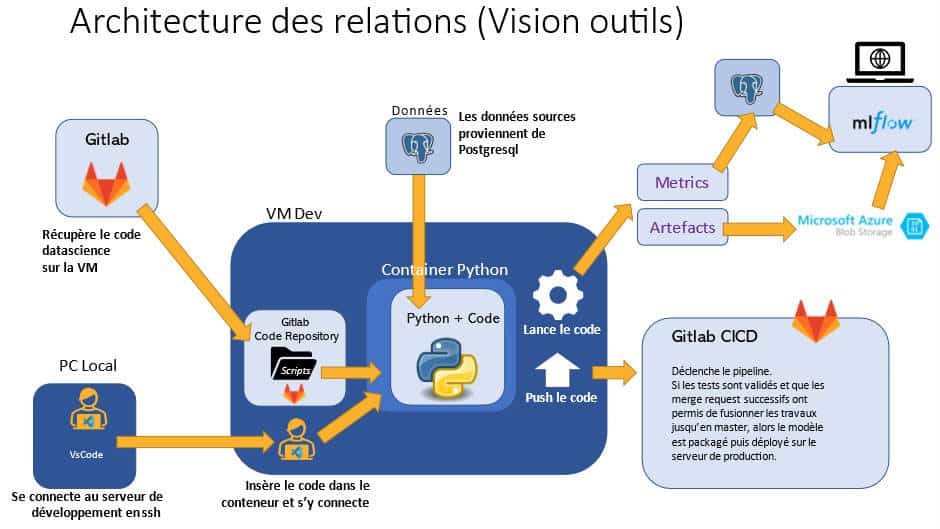
Voyons à présent comment le CI/CD cristallise la sécurité, la fiabilité et balise le chemin complet vers l’automatisation d’une chaîne de MLOps.
D’abord, la sécurisation pris au sens large s’aborde selon différents angles de vue. La sécurité de la plateforme elle-même, la gestion des utilisateurs mais aussi la sécurisation d’un modèle.
Ensuite, la fiabilité d’une chaîne MLOps repose sur deux pilliers : le code et le modèle.
Nous parlions précédemment des fonctionnalités non couvertes par MLflow. Il nous semblait important de traiter le Drift des modèles. Cette notion correspond au fait qu’un modèle dérive. En effet, un modèle est fondé sur un périmètre de données. Dès lors qu’un modèle est industrialisé, il va avoir tendance à se dégrader. Nous avons implémenté un code permettant de détecter le drift d’un modèle.
Pourquoi utiliser le MLops IaaS ?
- Pas de vendor-locking dans la mesure où les outils open-source laissent une liberté totale dans l’utilisation qu’il est possible de faire avec le scomposants.
- On-Premise et Cloud compatible : peut s’inscrire dans une infrastructure hybride voire implémenté dans le cloud en IaaS.
- Offre une maîtrise très fine de l’ensemble de la chaîne.
- Capacité à être au plus proche des besoins des Data Scientists (langage, librairies, mode de fonctionnement, etc.)
- Les coûts de RUN restent très faibles.
Ce qu’il ne faut pas négliger :
- Veille importante quant à l’évolution des outils open-sources
- Nécessite un investissement relativement important sur la composante Build
- La sécurisation de la plateforme et la gestion des identités (peu supporté dans les outils).
- La gouvernance se révèle complexe.
✍️ Cet article a été rédigé par Loïck Bernard.
👉 Retrouvez toute notre actu en temps réel en nous suivant sur LinkedIn 👈
[1] A ne pas reproduire chez soi sous peine de s’attirer les foudres des équipes infrastructure. Le bon sens voudrait qu’entre le développement et la production, il existe des espaces intermédiaires d’intégration, de recette. Pour rappel, c’est pour les besoins de l’exercice.


![[Data Rider] REX Collecte de données IoT – Étape 1 : Initier la collecte](https://fr.blog.businessdecision.com/wp-content/uploads/2025/05/data-rider-rex-collecte-donnees-1024x512-1.jpg)











Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.