
Précédemment, nous avons évoqué les capacités du ML sur l’hyperscaler Google Cloud Platform et vous avons montrer comment les mettre en action. L’objectif de ce nouvel article est maintenant de démystifier le passage à l’échelle. Nous vous ferons ici la démonstration avec Google Cloud Platform (GCP) mais la démarche est également applicable à d’autres hyperscalers…
Les différents niveaux de maturité MLOps
On classe communément la maturité MLOps de 0 à 2.
MLOps niveau 0 : processus manuel
A ce niveau, les entraînements et les déploiements sont lancés manuellement via des notebooks de type Jupyter ou Colab. L’inconvénient est qu‘il est difficile de reproduire les tâches successives qui mènent à l’entrainement puis à la mise en production du modèle.
MLOps niveau 1 : automatisation par pipeline ML
L‘objectif du niveau 1 est de permettre de réaliser un entraînement automatisé d’un modèle. Cette automatisation permet de :
- ré-entraîner automatiquement le modèle avec des données de production plus à jour pour contrôler sa performance dans le temps,
- faire évoluer le pipeline avec des optimisations d’entraînement,
- comparer plus facilement avec des modèles de Framework différents.
Pour automatiser le processus, on effectue des étapes automatisées, de validation des données, d’entraînement de modèle, de validation de modèle, de déploiement de modèle, dans un pipeline, ainsi que des déclencheurs de pipeline et une gestion des métadonnées.
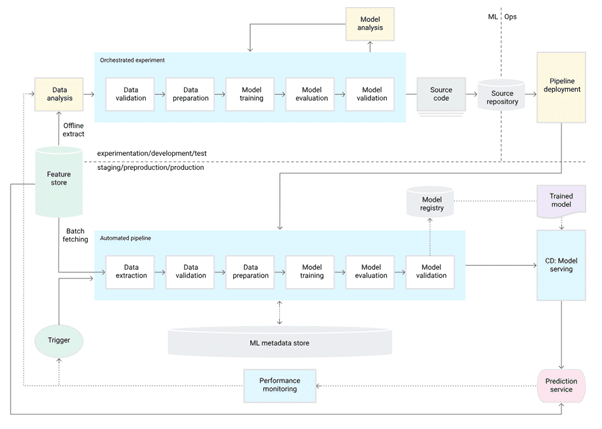
MLOps niveau 2 : déploiement des pipelines ML par CI/CD
Le niveau 1 convient si nous avons un nombre limité de pipelines. Les pipelines restent déployés manuellement. Le niveau 2 a pour objectif de déployer et de mettre à jour des pipelines en production de manière rapide et fiable. Il permet aux data scientists d’explorer rapidement de nouvelles idées concernant l’ingénierie des fonctionnalités, l’architecture des modèles et les hyperparamètres. Ils peuvent également mettre en œuvre ces idées et construire, tester et déployer automatiquement les nouveaux composants du pipeline dans l’environnement cible.
Les pipelines en action
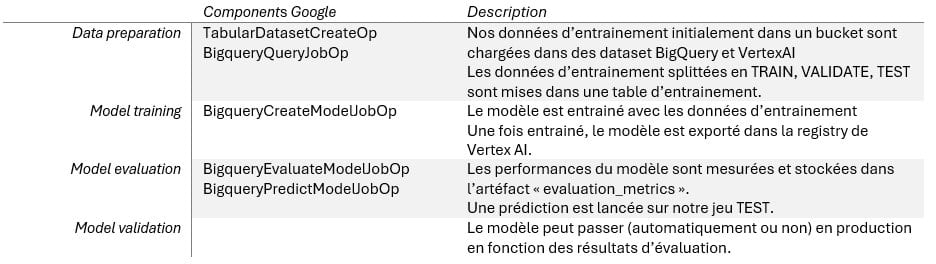
Avec notre use case, nous choisissons d’automatiser notre modèle LOGISTIC_REG (voir ci-dessus) parce qu’il est rapide à entraîner et qu’il ne nécessite pas l’usage de modèles personnalisés (voir ci-dessous). Nous choisissons Kubeflow Pipelines framework (KPF).
Un pipeline prend en entrée des paramètres et est constitué de components (tâches) qui ont en entrée des paramètres ou des artéfacts, et des artéfacts en sortie.
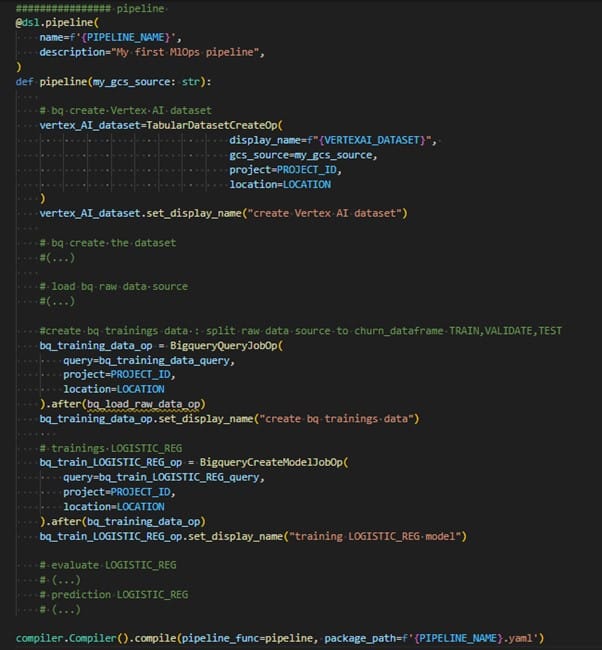
Techniquement, il s’agit de « builder » (en python dans notre cas) les tâches qui, après compilation, donnent un fichier au format « .yaml ». Le « serveur » KubFlow intégré à Vertex AI interprète ce fichier .yaml. Lorsque l’on « run » le pipeline, chaque tâche est lancée dans un conteneur, en respectant l’ordonnancement (if, else if, parallèlisation, etc.).
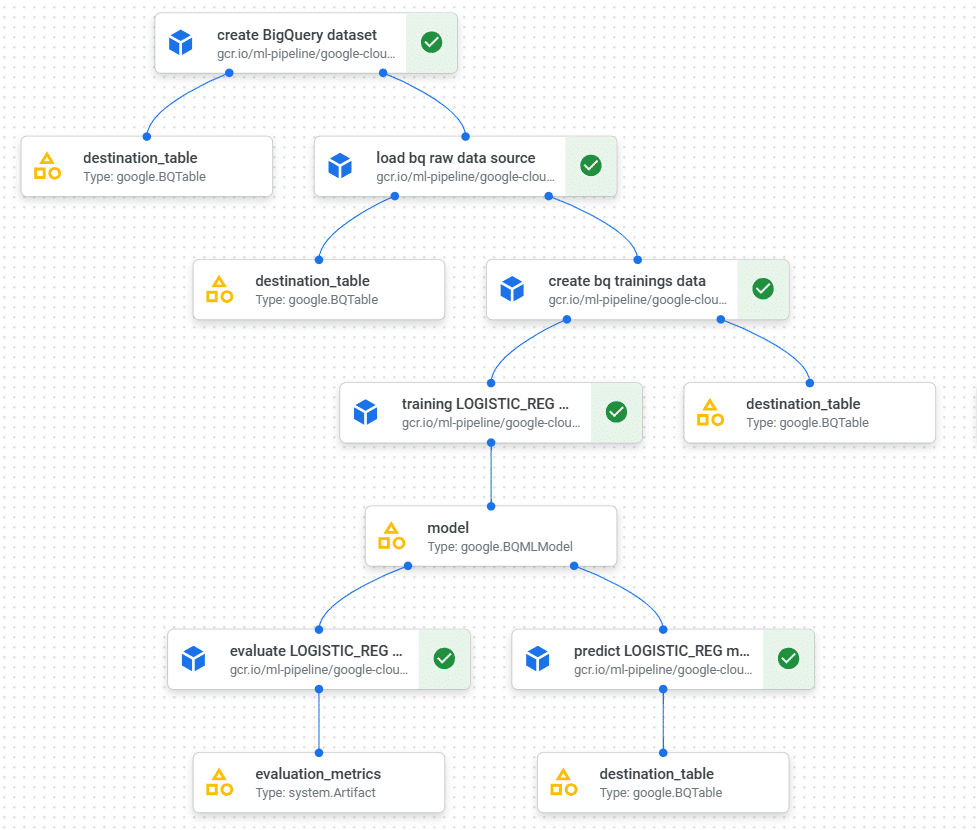
Description du pipeline
Extraits de code du pipeline
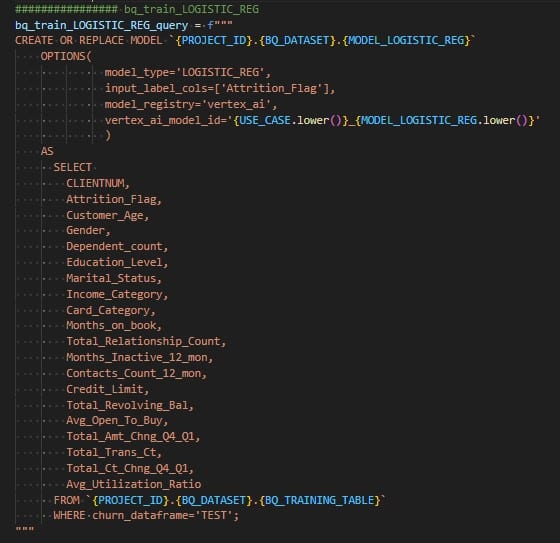
Pipeline triggers
Notre pipeline est enregistré dans l’artifact registry de notre projet (au format .yaml). Il est aussi accessible dans « your templates » sur Vertex AI. A noter : Vertex AI propose une « template Galery » avec une dizaine de pipeline déjà codées (beaucoup plus élaborés que le nôtre »).
Il peut être soit « schédulé » (lancé périodiquement), soit lancé à travers une cloud fonction. Une cloud fonction peut, quant à elle, être déclenchée, par exemple, par :
- Un événement Cloud Pub/Sub (fils d’attente de messages),
- Un évènement Cloud Storage (ajout / modification dans fichier de donnée d’apprentissage par exemple),
- Et bien d’autres événements possibles.
Avons-nous atteint le niveau 1 de maturité ?
Non, bien évidemment car il ne s’agit que d’un test d’implémentation.
Cependant :
✅ Notre pipeline est codé et versionné (sous git)
✅ Notre pipeline compilé (.yaml) et versionné dans le repository Vertex AI
✅ Chaque run du pipeline est conservé dans Vertex AI
✅ Chaque tâche conserve :
- la liste des artéfacts d’entrée et de sortie
- les paramètres
- les logs de traitement
✅ Tous les artéfacts produits sont référencés dans Vertex ML Meta data.
❌ Petit bémol : nos features (la liste des champs qui sont données à notre modèle) ne sont pas référencées dans Vertex AI Feature Store.
Il est important de noter que les pipelines fonctionnent avec du cache. Si les artéfacts de sortie sont déjà produits alors la tâche est « skippée ». Pour une liste de paramètres et de données en entrée le résultat du pipeline est toujours le même.
Enfin, on pourrait penser que BigQuery et BigQuery ML en particulier, ne sont pas vraiment compatibles avec de la gestion de configuration (versionning des requêtes SQL sous git). L’usage des pipelines ici montre cependant le contraire. L’ensemble des requêtes SQL, présentes dans notre projet (git) de développement, est intégré à notre pipeline avec la compilation et ainsi versionné sous git.
Lire aussi
IA à l’échelle : le Machine Learning à portée de clics grâce aux Cloud providers
Lire la suiteRetours d’expérience sur les pipelines et MLOps sous VertexAI (limitations, avantages inconvénients)
Les pipelines (Kubflow) sont de formidables outils d’automatisation qui prennent en charge énormément de sujets qu’il serait long et fastidieux à implémenter « from scratch » sur un cluster Kubernetes.
Les concepts et le principe de codage des pipelines sont plutôt complexes, il faut plusieurs jours avant de commencer à être à l’aise.
En ML « Changing Anything Changes Everything », avant de commencer sur un projet de type MLOps, il semble important de se poser quelques questions :
- Comment sont versionnées mes données d’entraînement ?
- Comment doivent être véhiculées les données d’une tâche à l’autre ?
- Quelles données doivent être partagées d’un modèle à l’autre ?
- Comment bien séparer le code métier (data featuring, paramétrage et algorithme d’entrainement) du code lié à la mécanique des pipelines ?
Les pipelines permettent de réaliser un entrainement continue des modèles avant un passage en production. En revanche, jusqu’ici rien ne définit la gouvernance et l’organisation d’une équipe complète, constituée de data scientists, de data ingénieurs, de MLOps ingénieurs, et autres.
Google propose dans ce ML blueprint une « fondation » qui définit :
- Un espace interactif (notesbook, exploration)
- Un espace opérationnel (production, non production, pipelines)
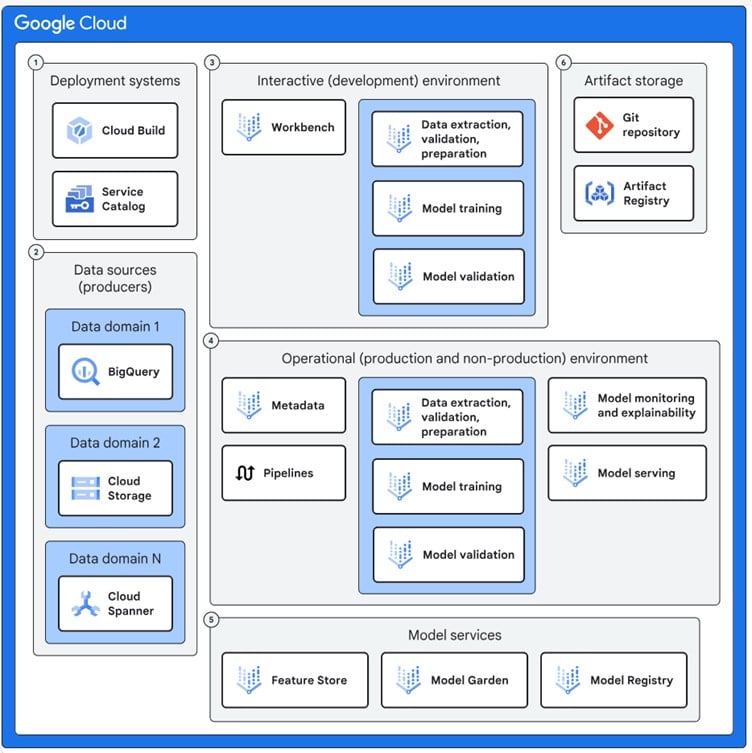
Il est vivement conseillé de mettre en place un principe d’organisation, à l’échelle du besoin pour, a minima :
- Bien définir et surtout accorder des rôles (au sens IAM) par groupe de fonction,
- Restreindre les accès en least privilège sur les environnements de production/non production,
- Appliquer des règles de sécurité nécessaires (contrôler l’accès aux données, gérer les compte de services, etc.),
- Mettre en place un suivi des consommations avec une stratégie de labelling adéquat.
Les modèles personnalisés en action
Entraîner un modèle personnalisé, ce n’est pas sortir des sentiers battus, c’est plutôt entrer de plein pied dans l’univers des Data Scientists.
Vertex AI permet d’entraîner et de déployer des modèles de type PyTorch, TensorFlow, scikit-learn et XGBoost. Il met à disposition des images de conteneurs pré-buildés d’entraînement et de prédiction pour chacun de ces 4 frameworks.
Nous savons désormais créer des « components » de pipeline qui tournent dans des conteneurs. « Il nous suffit juste » d’utiliser ces images de base.
La tâche reste ardue :
- Les modèles « non personnalisés » proposés par Google sont déjà conçus pour utiliser les jeux de données de type Vertex AI dataset et BigQuery dataset. A l’inverse, les modèles personnalisés eux utilisent en entrée des données chargées depuis du CVS (Cloud storage) et manipulées via les librairies pandas ou équivalent.
- La « compilation du modèle » se complexifie et le travail de MLOps se résoudra, probablement, en reprenant ou en adaptant le code issu des notesbooks des Data Scientists.
- Enfin, dans la console, les résultats d’évaluation des modèles non personnalisés, sont particulièrement bien affichés. Nous n’avons pas exploré la capacité, à travers Vertex AI, à rendre l’expérience utilisateur identique dans le cas des modèles personnalisés. Nos premiers tests sur les « expérimentations » intégrées dans Vertex AI n’ont pas été très probants.
Nous reprenons notre jeu de test bankchurner et choisissons d’entrainer un modèle de type XGBoost.
Notre pipeline « en cours de développement » ressemble au précédent.
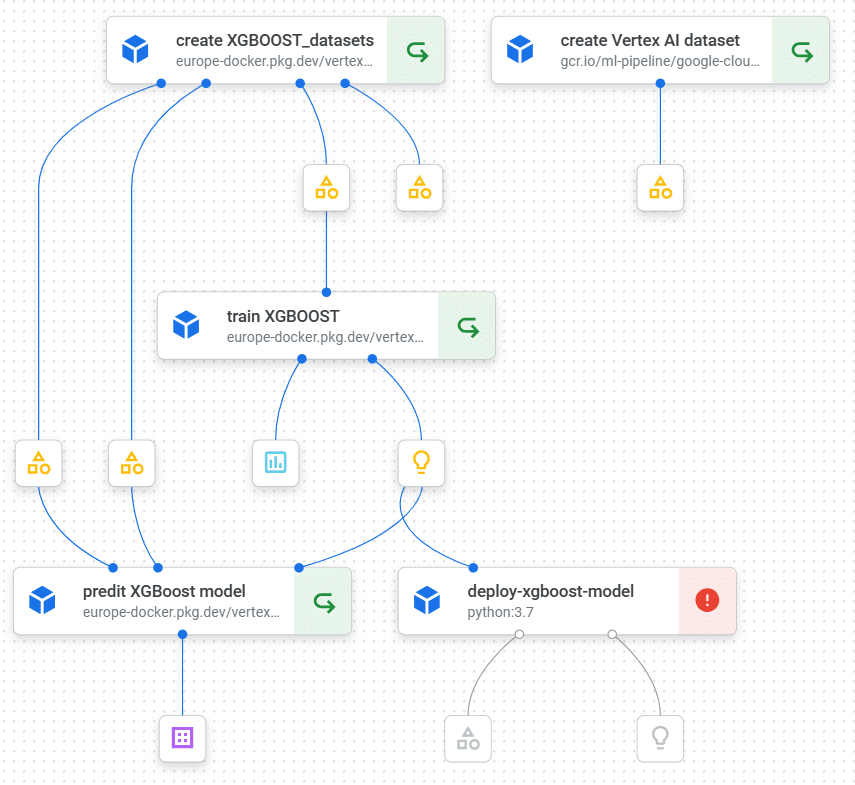
Notez qu’en l’état, la tâche de déploiement est en échec. Vertex AI est, comme tous les services Google cloud, intégré au services Google Cloud Logging. Le lancement de la tâche deploy-xg-boost-model est loggée et nous pouvons compléter notre code Python pour qu’il écrive lui aussi des logs dans Cloud logging.
Préparation du dataset pour un modèle personnalisé
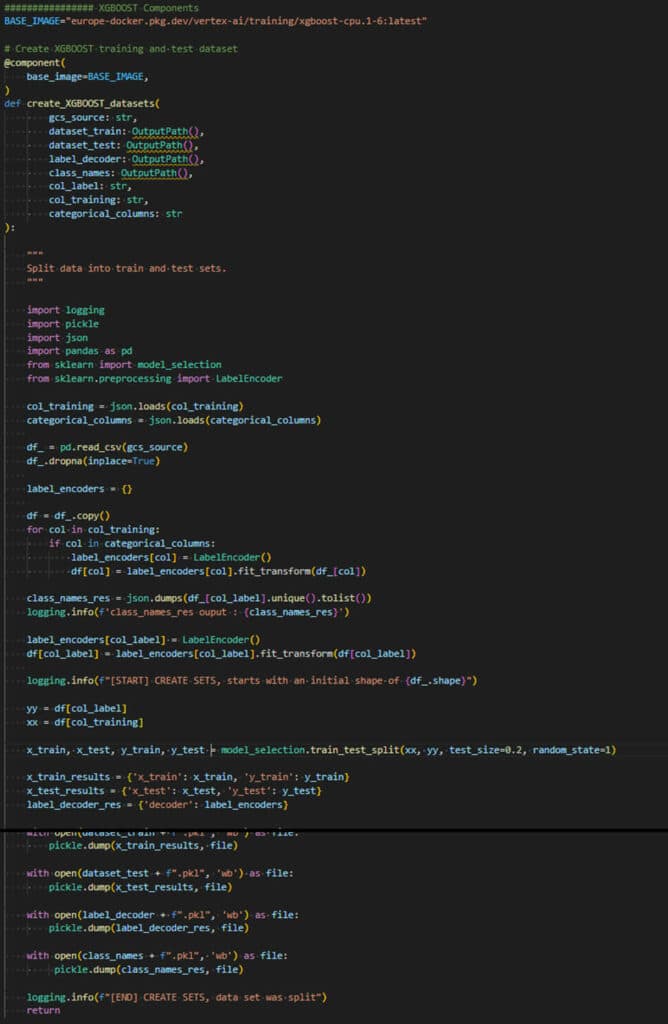
– Les données sont chargées dans un datafram panda,
– Le split des données est fait via un module sklearn,
– La transformation des données pour l’apprentissage est elle aussi faite via un module sklearn. Cela fait partie des nombreuses possibilités que Google permet via AutoML et BigQuery et qu’il faut désormais traiter.
– « pickle » permet de sérialiser en numérique des objets Python. Nous l’utilisons pour véhiculer les données d’entraînement d’une tâche à l’autre. Ce n’est probablement pas une très bonne pratique !
Entraînement d’un modèle personnalisé
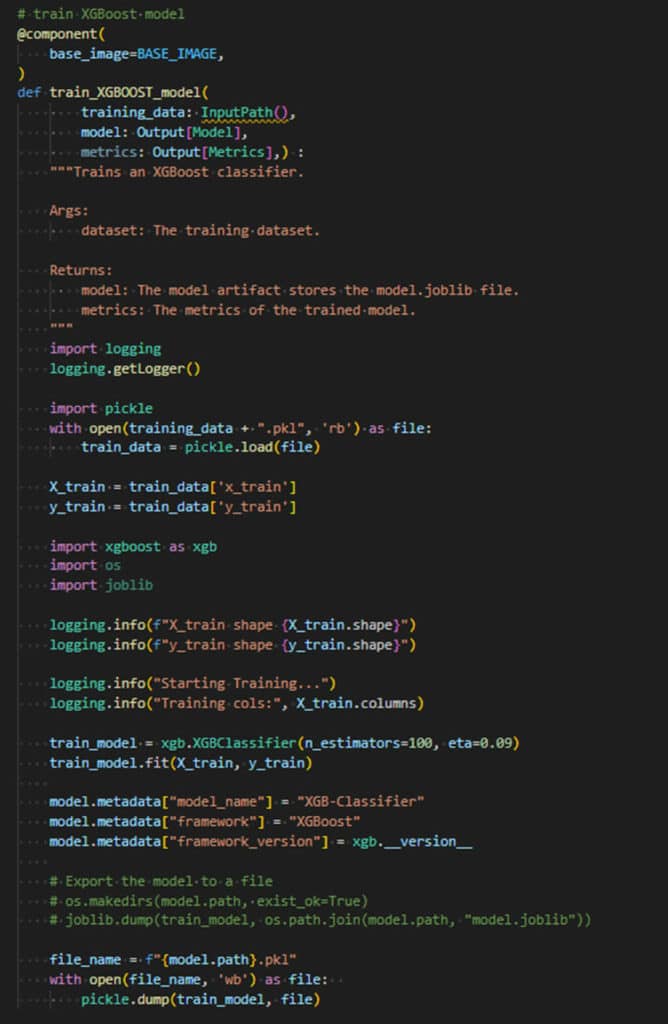
- Les données d’entraînement sont chargées par pickel. L’artéfact InpuPath nous a permis de retrouver le chemin dans Google Cloud Storage.
- La librairie xgboost nous permet d’entrainement avec sa fonction fit
- Une fois entrainé, le modèle est exporté dans l’artéfact de sortie « model » soit avec « pickle » soir avec « jolib »
Vertex ML Metadata
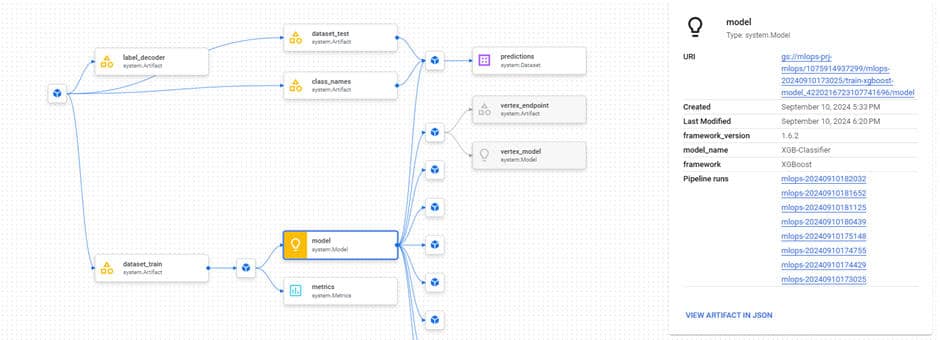
La représentation des metadata permet d’avoir une bonne vision et surtout une traçabilité des artéfacts qui ont contribué à l’entraînement et à la prédiction sur un modèle.
Dans cet exemple :
- Les données d’entraînement sont facilement identifiables
- Les données de test sont utilisées pour réaliser une prédiction batch et évaluer la qualité du modèle sur des données non connues par le modèle. Le résultat de la prédiction est lui aussi conservé.
- « class_names » conserve le mapping de conversion entre les données de type string et les données de type « int » qui ont servies à l’entraînement.
Retours d’expérience sur les modèles personnalisés (limitations, avantages inconvénients)
C’est au passage aux modèles personnalisés que l’on mesure combien AutoML et BigQuery ML nous ont considérablement facilité la tâche jusqu’ici.
Aller plus loin sur ce chemin demande aussi bien de bonnes compétences en développement qu’une étroite collaboration avec les Data Scientists.
À retenir
Malgré la volonté des cloud providers de démocratiser le ML, cette science « expérimentale » nécessite cependant très vite la présence de Data Scientists aguerris.
Le ML et le cloud vont réellement de pair. Les services sont interopérables, accessibles sans licence, quasiment tous disponibles en pay as you go, tous gérés et prêts à la production sans installation préalable. L’implémentation est modérément complexe mais largement facilitée par une documentation abondante.
En résumé, voici parmi les différents topics parcourus ce qui nous ferait aller vers l’un ou l’autre :
AutoML
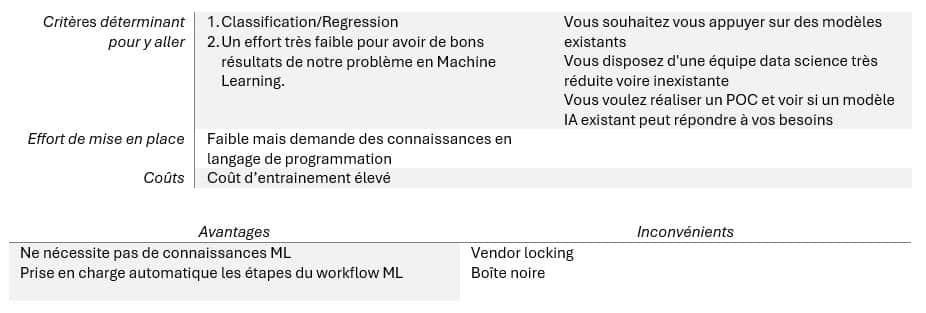
BigQueryML

MLOps/Pipelines

Modèles personnalisés

J’espère que cet article et cette démonstration vous aura aidé à démystifier le passage à l’échelle pour vos projets. A bientôt !


![[Data Rider] REX Collecte de données IoT – Étape 1 : Initier la collecte](https://fr.blog.businessdecision.com/wp-content/uploads/2025/05/data-rider-rex-collecte-donnees-1024x512-1.jpg)











Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.