
En 1990, le Machine Learning automatisé (AutoML) est apparu et a silencieusement révolutionné le monde de l’intelligence artificielle (IA). Une analyse du terme AutoML nous apprend qu’il s’agit d’une fusion de deux éléments : Automated (automatisé) et Machine learning (apprentissage automatique).

Les différents types de Machine Learning
- Le supervisé (données étiquetées) ;
- Le non supervisé (données non étiquetées) ;
- Le semi-supervisé (mélange de données étiquetées et non étiquetées) ;
- Par renforcement (apprentissage en fonction des erreurs).

Matinale Data & IA
L’AutoML a pour objectifs l’optimisation et l’accélération des tâches humaines à travers une amélioration du quotidien. Les exemples sont nombreux mais je ne vais en citer ici que quelques-uns : classification automatique des déchets, optimisation de l’entretien des membranes de filtration de l’eau, amélioration des protocoles de sécurité informatique pour détecter les attaques…
La partie « Auto » désigne l’automatisation du « ML » à l’aide des algorithmes d’apprentissage automatique. En d’autres termes, cela signifie passer à une étape supérieure d’IA, ce qui explique que l’AutoML est un sujet qui suscite actuellement énormément d’intérêt dans les milieux professionnels et universitaires. Toutefois, il reste à savoir s’il s’agit là d’un processus ou pas.
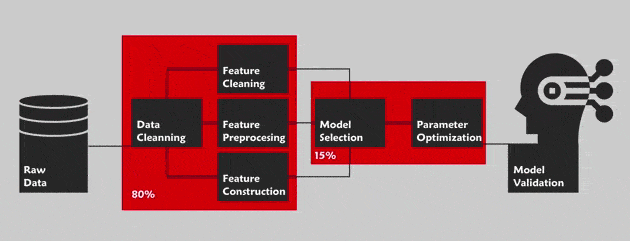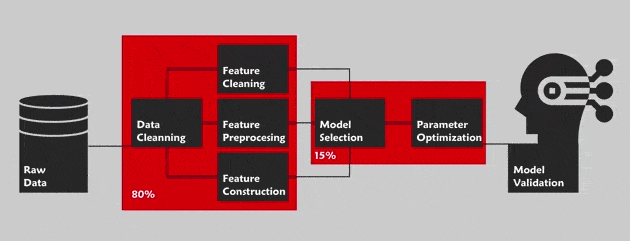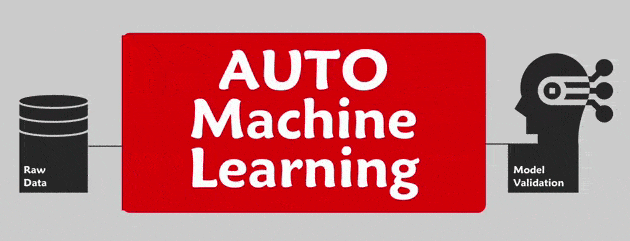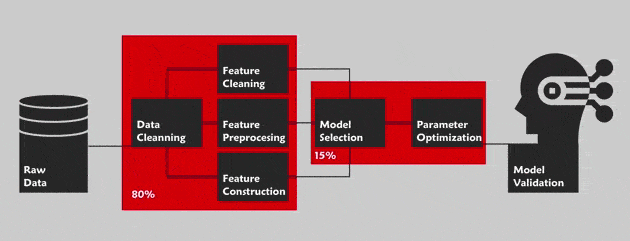
L’AutoML consiste à optimiser le pipeline des projets de Data Science dans son intégralité. Nous faisons ici référence à la méthode Cross Industry Standard Process for Data Mining (CRISP-DM) dont les étapes principales sont : la compréhension du problème métier, la compréhension des données, la préparation des données, la modélisation, l’évaluation et le déploiement. Cette méthode est un guide décrivant, étape par étape, comment réaliser ces projets. Outre la phase de « compréhension du problème métier », l’AutoML vise à l’automatisation de tout le pipeline dans le but de faciliter la tâche des non-spécialistes du domaine (Exemple : le service Cloud AutoML de Google pour les visuels).
Les avantages principaux de l’AutoML
1. Une bonne base pour la préparation des données
La préparation des données doit reposer sur des opérations de nettoyage (filtrage du bruit dans les données) et de formatage (recodage en données catégorielles par exemple) fiables. L’AutoML permet d’accélérer cette phase grâce à un processus formatant et détectant le bruit dans les données de manière différente.
2. Éviter l’utilisation des paramètres par défaut dans les modèles
La recherche des meilleurs paramètres passe par une maîtrise des méthodes de recherche par quadrillage et aléatoires (des techniques d’optimisation qui permettent de calculer les valeurs optimales des hyperparamètres) afin d’obtenir une liste de paramètres parmi lesquels choisir les plus appropriés. Ce processus est parfois chronophage, d’où l’intérêt de l’AutoML qui permet de résoudre ce problème.
3. Simplification des processus de création et de gestion des modèles
En général, les Data Scientists établissent une liste de modèles intéressants en fonction du contexte et du problème. Ce qui requiert une connaissance approfondie et de l’expertise métier dans le domaine de la donnée. L’AutoML simplifie cette étape car il met à disposition un véritable réservoir proposant davantage de modèles, adaptés à une majorité de problèmes.
4. Optimisation du Deep Learning
Le Deep Learning s’inspire du fonctionnement du cerveau humain pour traiter les données et créer les modèles à utiliser dans les processus de prise de décisions. Son objectif est de trouver l’architecture de réseau neuronal la plus appropriée pour aborder une question donnée. Avec, par exemple, Keras, une bibliothèque open source dédiée au Deep Learning, de nombreuses lignes de code sont nécessaires pour créer cette meilleure architecture. Toutefois, grâce à la méthode Auto-Keras (bibliothèque d’apprentissage en profondeur) d’apprentissage automatique, il est désormais possible d’obtenir de meilleurs résultats avec beaucoup moins de lignes.
Bibliothèques d’apprentissage automatique automatisé :
Pour découvrir toute l’étendue des avantages mentionnés ci-dessus, voici quelques-unes des bibliothèques de Machine Learning automatisé disponibles :
| Phases | Usage et Source |
|---|---|
|
The Machine Learning Box (MLBox) |
|
Auto-sklearn H2O Auto-ML |
|
TPOT stands for Tree-based Pipeline Optimization Tool |
| Auto-Keras Ludwig |
Liste d’outils d’AutoML open source et payants
Nous avons également dressé une liste d’outils open source et payants pour du Machine Learning automatisé.
Open source
- TPOT (Tree-based Pipeline Optimization Tool)
- MLBox
- Auto-sklearn
- Auto-Keras
- Auto-Pytorch
Payants
- Google Auto-ML
- DataRobot
- PurePredictive
- H2O.ai
- Amazon Lex
Quelle est donc la réponse à la question initialement posée : « Le Machine Learning automatisé (AutoML) existe-t-il vraiment ? ». Il est clair qu’il serait difficile d’en nier l’existence mais, à mon sens, le mot « automatisé » dans ce contexte qualifie une boucle qui contient de nombreux processus et méthodes (nettoyage, formatage, optimisation de paramètres, modèles d’apprentissage automatique, architecture d’apprentissage en profondeur…) et qui tourne afin de trouver à chaque fois le meilleur scénario pour résoudre un problème donné.
Le Machine Learning automatisé est aujourd’hui en cours de développement. Il peut déjà donner de bons résultats, mais a encore besoin d’amélioration. En effet, son utilisation est généralement limitée à l’apprentissage supervisé car, dans les cas d’apprentissage non supervisé et par renforcement, de nombreuses difficultés sont encore constatées.
L’AutoML ne remplacera pas encore les Data Scientists
L’AutoML ne remplacera pas les Data Scientists, donc aucune raison de s’inquiéter pour les professionnels (du moins pour l’instant) ! Toutefois, il peut certainement être considéré comme un outil pour les Data Scientists. Il peut surtout constituer également un excellent moyen de faciliter l’accès des non-spécialistes à ce domaine si complexe, afin que ceux-ci puissent eux aussi bénéficier de l’expérience d’apprentissage automatique.
Nous pouvons prendre l’exemple de Kaggle (une communauté dont l’objectif est de relever des défis posés en matière d’apprentissage automatique) pour mieux comprendre cela. L’homme a, en effet, toujours gagné à l’aide de modèles non générés par les outils d’AutoML. Autant que je sache, l’AutoML n’a jamais remporté un concours de Data Science !
Les pipelines générés par l’AutoML gagneront-ils ce genre de compétitions un jour ?
J’espère que mon raisonnement aura été facile à suivre pour tous, notamment pour les non initiés. Je me tiens à votre disposition pour approfondir la discussion et répondre à toutes vos interrogations dans la section réservée aux commentaires 😉.








![[Data Rider] Booster Mario Kart à l'IoT et à l'IA – Étape 3 : écoconduite et consommation électrique](https://fr.blog.businessdecision.com/wp-content/uploads/2024/08/data-rider-ecoconduite-1024x512-1.jpg)





Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.