
Précédemment, nous vous avons fait découvrir les différents services Google. Aujourd’hui, nous allons nous mettre en ordre de marche pour tester ces outils de Machine Learning grandeur nature, en utilisant Google Cloud Platform. C’est parti…
Lire aussi
IA à l’échelle : le Machine Learning à portée de clics grâce aux Cloud providers
Lire la suite« Use case » : bankchurner ou comment prédire le départ client d’une banque
Ce cas d’usage, que nous avons nommé « bankchurner« , comprend 10127 enregistrements sur des clients bancaires. Les 23 champs donnent :
- Des informations classiques : Numéro de client, Age du client, Genre, Revenus et d’autres informations plus techniques comme le Montant et le nombre total des transactions dans l’année.
- « customer attrition » indique si le client est encore dans la banque ou non : « Existing Customer» ou « Attrited Customer »
L’objectif : prédire le départ d’un client de la banque.
Ce « use case » sera pris pour exemple tout au long de notre découverte des outils ML.
Pour commencer, l’AutoML (Machine Learning automatisé), s’il tient toutes ses promesses, va nous permettre de faire nos premiers pas.
Il nous aide ainsi dans les différentes tâches du worklow et nous assiste notamment dans la préparation des données et l’entrainement du modèle. Aucune connaissance théorique n’est a priori nécessaire.
Entrainement d’un modèle avec l’AutoML
L’AutoML prend en entrée 4 types de données avec pour chacun les objectifs suivants :

Notre « use case » entre dans la catégorie « Tabular data » et notre objectif est une « Classification binaire » (Une seule classe « Attrition flag » qui prend les valeurs « Customer Existing » ou « Customer Attrited »).
Création de l’ensemble de données
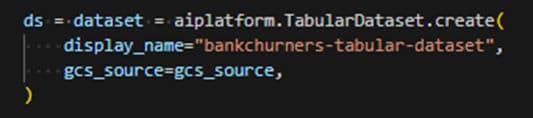
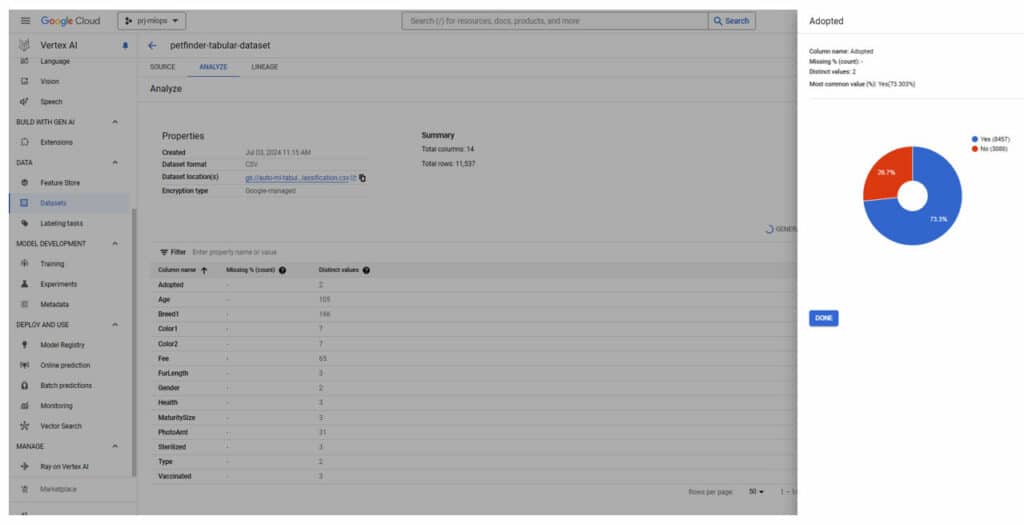
La création d’un dataset est nécessaire pour l’AutoML. Les données d’entrainement au format CSV sont chargées dans le dataset à partir d’un bucket Google cloud. Par défaut un split aléatoire de 80 %, 10 %, 10 % est appliqué pour définir les jeux de « Training », « Validation » et « Test ».
Une fois chargé, le dataset indique les propriétés et les champs de la source de donnée. Sur demande il est possible de disposer d’informations statistiques par champs (données manquantes, nombre de données distincts, répartition).
Préparation du job d’entraînement
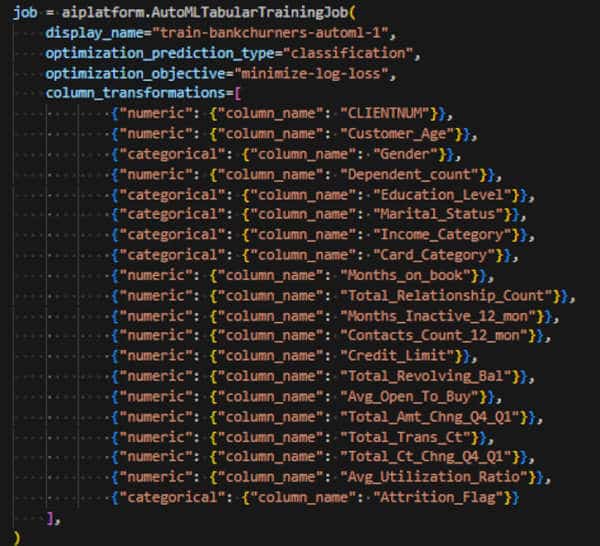
La préparation du job d’entraînement pour des données tabulaires se limite aux seuls paramètres d’optimisation « classification », »minimize-log-loss ». AutoML fait tout le reste !
Comme indiqué plus haut, les modèles ne prennent en entrée d’apprentissage que des données numériques. L’AutoML offre la possibilité de transformer les données pour l’apprentissage.
Par exemple la colonne « Income_Category » qui comprend des valeurs « Less than $40K », « $40K – $60K », … vont être converties en autant de valeurs numériques dans la catégorie.
Entraînement du modèle
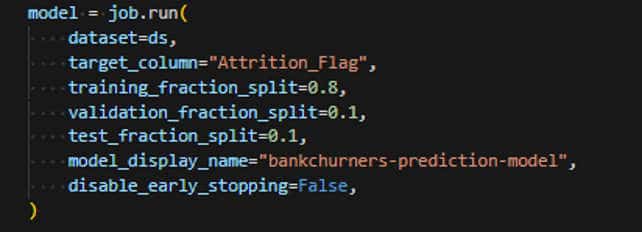
Le job d’entrainement proprement dit prend en entrée le dataset de données, le nom de la colonne que nous souhaitons prédire et optionnellement une répartition différente du jeu d’entrainement. Et c’est tout !
En sortie de cette phase d’entrainement le modèle est disponible dans le « Model Registry ». Il n’est pas utilisable en l’état.
L’entrainement a été effectué, quelque part en Europe (pour notre cas) dans VertexAI en dehors de notre projet.
Vous pouvez, sous certaines conditions, exporter votre modèle dans une image docker. Vous pouvez alors le déployer dans votre projet et l’utiliser (là encore avec certaines limitations).
Évaluation et utilisation du modèle
L’évaluation et l’utilisation du modèle passent nécessairement par son déploiement. En sortie de cette phase, le modèle est accessible sur un endpoint, il tourne dans Vertex AI, quelque part en Europe sur une VM avec le gabarit que vous avez choisi.
Évaluation du modèle
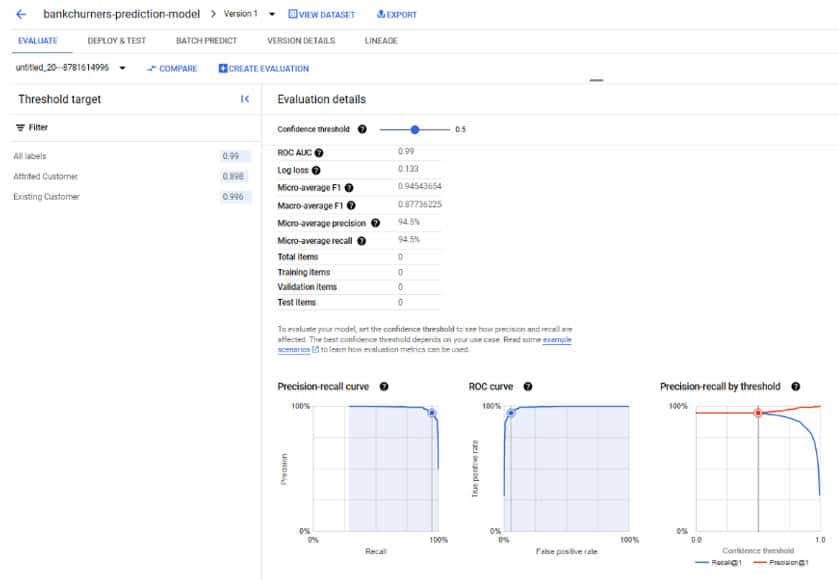
Vertex AI expose l’ensemble des métriques nécessaires aux Data Scientists.
Utilisation du modèle
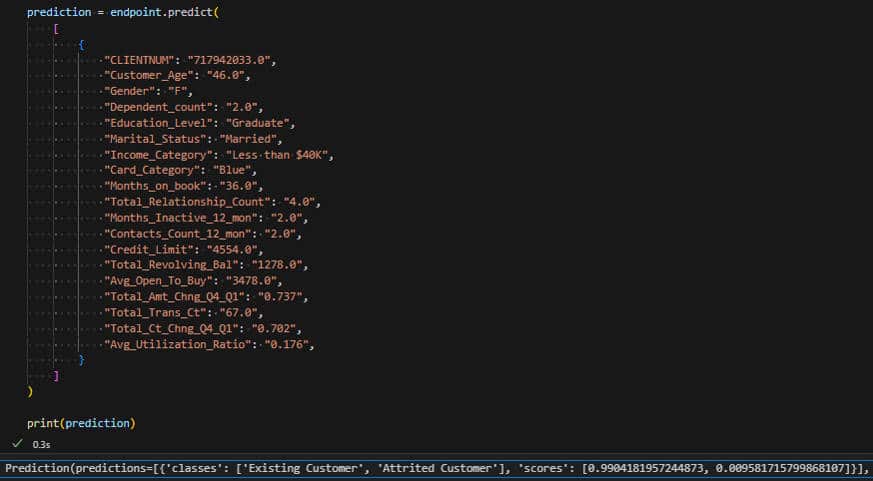
Prédire consiste à interroger avec des valeurs de test.
Dans l’exemple, notre client est resté dans la banque avec un score à 99,04 % et a quitté la banque avec un score de 0,01 %.
Il est aussi possible de faire une prédiction batch sur l’ensemble des clients de la banque.
Retours d’expérience l’AutoML (limitations, avantages inconvénients)
L’objectif est atteint. Moyennant quelques bouts de code complémentaires, on constate que les prédictions sont conformes aux attentes. Les notebooks (Colab et Workbench) rendent l’apprentissage vraiment très aisé. Les exemples, sous GitHub dans le projet vertex-ai-samples, sont nombreux et viennent enrichir la documentation Vertex AI à chaque fois que nécessaire.
L’AutoML permet d’aborder le Machine Learning sans en avoir la connaissance ni technique ni théorique.
L’entraînement du modèle est relativement long en plus des 2 heures de traitement. Le modèle doit être déployé pour être évalué (il faut penser à supprimer son déploiement). Le tout nous a coûté une vingtaine d’euros et quelques euros supplémentaires par minute (pour le temps où le modèle a été déployé).
Maintenant que nous avons vu les bases du ML avec l’AutoML on se dit tout de même que nos chères data scientists et data ingénieurs risquent de se trouver à l’étroit. Il y a peu de possibilités pour la préparation des données (feature ingeniering) et peu de possibilités de paramétrage du modèle, etc.
Cependant, ne voyez pas les modèles AutoML comme des modèles « au rabais ». Ils sont au contraire un concentré d’optimisation (d’où les 2 heures de traitement). Leur précision est probablement élevée et c’est que l’on voudra vérifier en comparaison d’autres modèles (personnalisés).
Il est assez difficile d’identifier les algorithmes sous-jacents (la documentation Google les décrits comme des méta-ensembles d’arbres et de réseaux neuronaux).
Autres limitations AutoML :
- Le type « Text data» n’est plus disponible depuis septembre 2024 sur l’AutoML et est passé dans la partie Générative AI.
- Tous les modèles ne peuvent pas être exportés. La prédiction Batch ou les fonctions « d’explication » ne sont pas disponibles en dehors de Vertex AI.
Entrainement et déploiement de modèles BigQuery ML
« L’architecture sans serveur de BigQuery vous permet d’utiliser des requêtes SQL pour analyser vos données. Vous pouvez stocker et analyser vos données dans BigQuery ou utiliser BigQuery pour évaluer vos données là où elles se trouvent. »
Ainsi définit par Google, BigQuery offre une approche différente et plus proche des données pour de l’entrainement des modèles.
Les modèles ML de BigQuery peuvent être classés en deux catégories : les modèles intégrés (build-in) et les modèles externes.
- Les modèles intégrés BigQuery ML sont entrainés au sein de BigQuery, comme la régression linéaire, la régression logistique (ie : la classification), et autres.
- Les modèles externes BigQuery ML sont entrainés à l’aide d’autres services Google Cloud DNN, boosted tree et random forest (qui sont entrainés sur Vertex AI) et les modèles AutoML (qui sont entrainés sur le backend Vertex AI).
Nous choisissons d’investiguer sur 2 modèles : l’AutoML et classification.
Notre jeu de donnée bankchurner s’importe aisément du format CSV vers BigQuery.
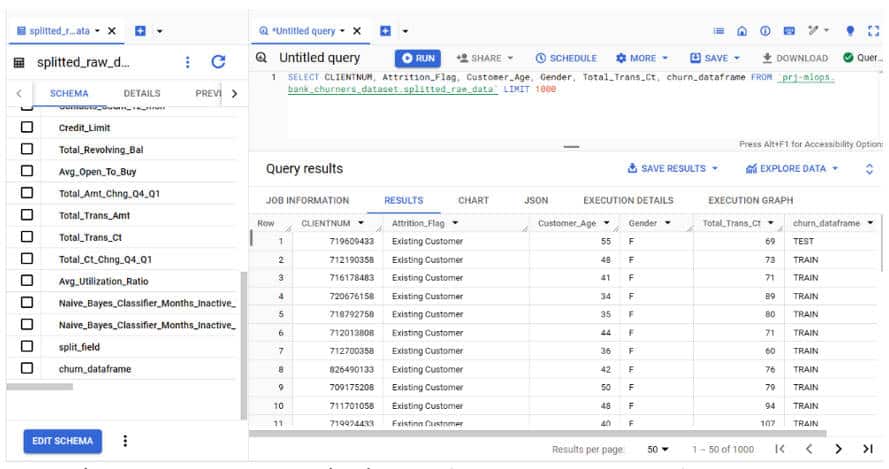
Nous réservons 80% des données à l’entrainement (TRAIN) et moins de 20% pour nos tests (TEST).
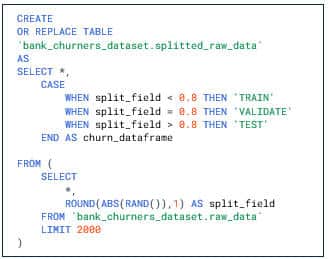
Entraînement et évaluation des modèles
La création des modèles avec BigQuery se fait en SQL comme si nous faisions de l’analytique.
1. Modèle de type AUTOML_CLASSIFIER
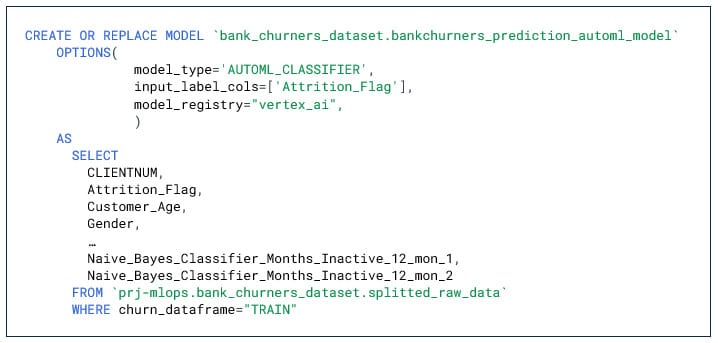
Notre premier modèle de type AUTOML_CLASSIFIER, comme pour de l’AutoML classique prend très peu de paramètres en entrée : le type de modèle et la colonne à prédire.
L’apprentissage se fait sur notre sous-ensemble « churn_dataframe= TRAIN ». En AUTO_SPLIT, par défaut Biquery se charge de splitter les données d’entrainement en 80%/10%/10%.
Le modèle entrainé se retrouve directement dans les « Models » de notre dataset avec les évaluations. Cette fois nous n’avons pas besoin de déployer le modèle pour en avoir une évaluation. Nous retrouvons les mêmes onglets TRAINING et EVALUATION.
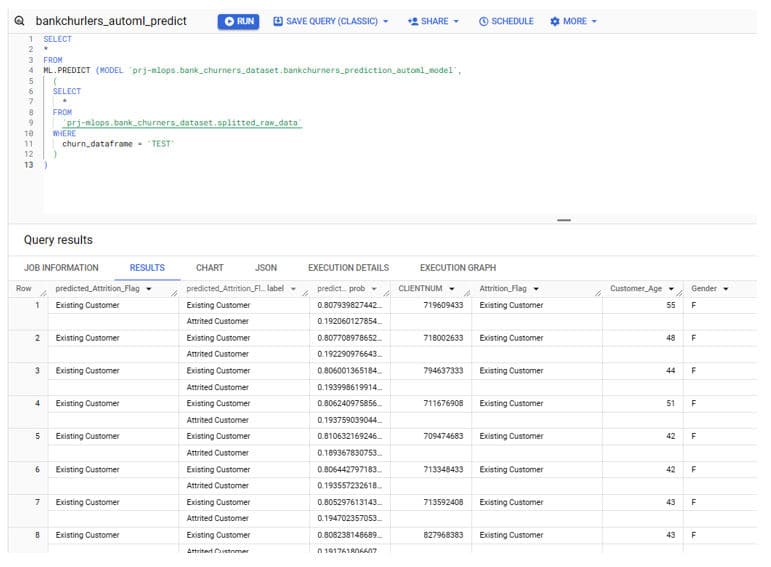
La prédiction batch se fait là aussi très simplement en SQL sur la base cette fois de notre sous-ensemble « churn_dataframe= TEST ».
Les résultats sont très conformes aux attentes.
2. Modèle de type LOGISTIC_REG
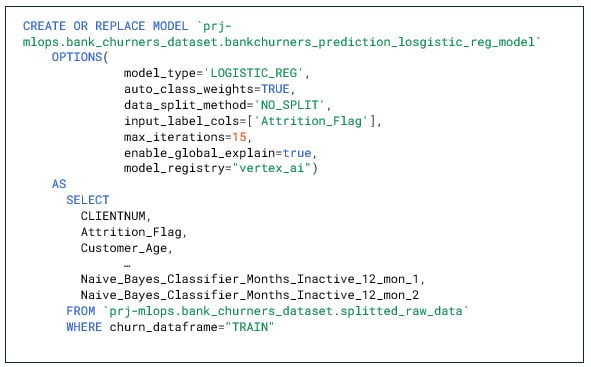
Notre second modèle de type LOGISTIC_REG n’est plus un modèle d’AutoML. Il admet en entrée beaucoup plus de paramètres (Poids de classes, tunning des hyperparamètres, L1/L2 régulation). Clairement à ce niveau les compétences de nos data scientistes deviennent indispensables.
Nous nous limiterons donc à quelques paramètres de base.
Et là, surprise : l’entraînement de ce dernier modèle, avec les mêmes données ne prend plus qu’une 1 minute contre 2 heures pour le modèle d’AutoML.
Les résultats demeurent pour autant tout aussi satisfaisants que le modèle AutoML.
Explication d’un modèle
Pour faire le choix des labels (ou features) à utiliser, il est intéressant de comprendre comment le modèle réalise ses prédictions.
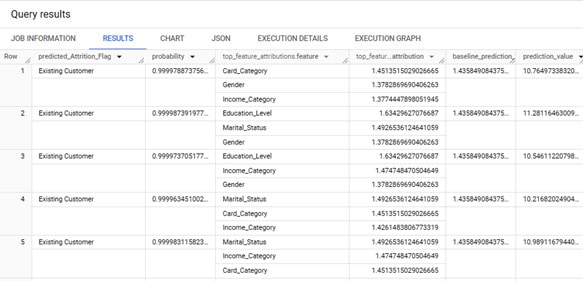
La fonction ML.EXPLAIN_PREDICT (toujours en SQL) permet d’afficher les n features qui ont le plus influées dans la prédiction pour chaque ligne de test.
A noter que cette fonctionnalité n’est pas disponible sur le modèle AutoML.
Vertex IA Expainable ajoute une fonctionnalité complémentaire avec la fonction ML.GLOBAL_EXPLAIN que donne le top 10 des features importantes pour le modèle. C’est pourquoi nous avons ajouté le paramètre (enable_global_explain=true) lors de la création du modèle. Cette fonction n’est pas non plus disponible pour les modèles d’AutoML.
Bizarrement, l’onglet INTERPRETABILITY est visible pour nos 2 modèles :
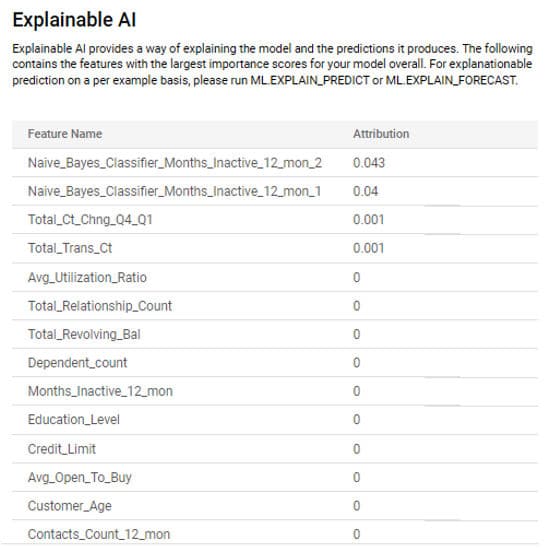
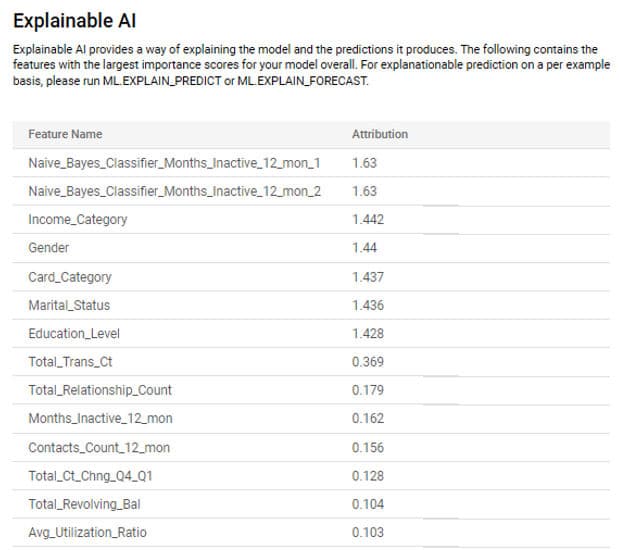
Là encore, l’expertise des data scientists s’impose pour comprendre la différence entre les 2 modèles.
Import des modèles dans le registry de Vertex AI
Vertex AI étant « Le » laboratoire IA, il parait normal de pouvoir retrouver les modèles entrainés depuis BigQuery dans la partie Vertex AI. Ce n’est le cas par défaut mais le paramètre « model_registry=vertex_ai » exporte le modèle dans la registry de Vertex AI (s’il est positionné lors de la première création).
Retours d’expérience BigQueryML (limitations, avantages inconvénients)
Là aussi, l’objectif est atteint. BigQuery rend très souple l’analyse des données, l’entrainement et l’évaluation modèles.
Que les data scientists se rassurent, il est toujours possible de réaliser le travail d’exploration et d’analyse grâce aux outils habituels python, panda etc. à travers des notebooks Google Colab ou Jupyter. BigQuery DataFrames permet d’accéder directement aux tables BigQuery.
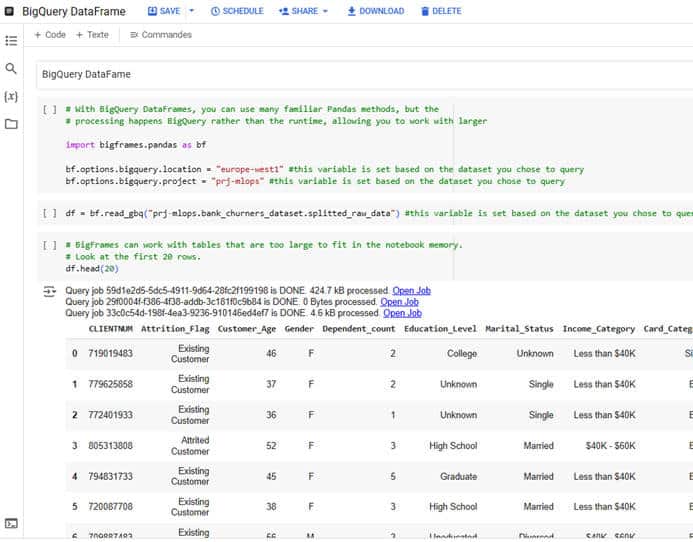
Nous avons utilisé les Notebooks Colab intégrés à BigQuery. Pour l’utiliser, il doit être connecté un runtime créer dans Vertex AI.
Cet exemple montre comment charger les données de notre jeu de test depuis BigQuery vers un objet de type pandas.
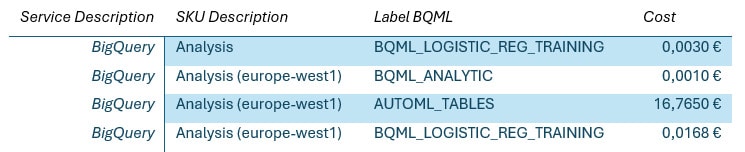
En termes de coût, le passage à BigQuery est riche en enseignements.
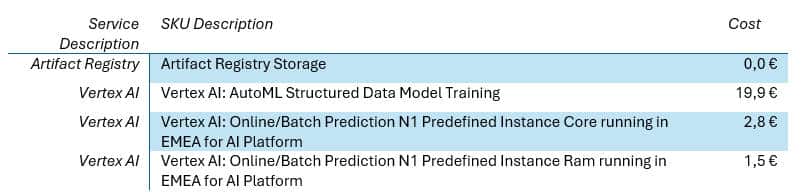
- L’entrainement du modèle AUTOML_CLASSIFIER est long comparé au modèle LOGISTIC_REG et donc il nous a coûté environ 17€ pour le premier contre < 1€ pour le second.
- Le pricing BigQuery ML (pour les modèles testés) fonctionne vraiment en Pay as you Go. Nous ne sommes pas facturés pour l’hébergement des modèles déployés (quelques euros par heure sur Vertex AI selon le gabarit choisi) mais uniquement sur les prédictions réalisées (BQML_ANALYTIC).
On peut noter enfin que dans l’export du compte de facturation les SKU pour Vertex AI détaillent bien les coûts (voir coûts AutoML) alors que pour BigQuery nous ne voyons que le SKU « Analysis ». Nous avons exploité le label « bigquery.googleapis.com/bqml » (reste à savoir s’il est réellement pérenne dans le temps).
Nous avons désormais une bonne vue sur quelques principes d’entrainement de modèles sur notre jeu de données. Nous n’avons pas abordé les modèles personnalisés mais nous pouvons d’ores et déjà nous intéresser au passage en production.
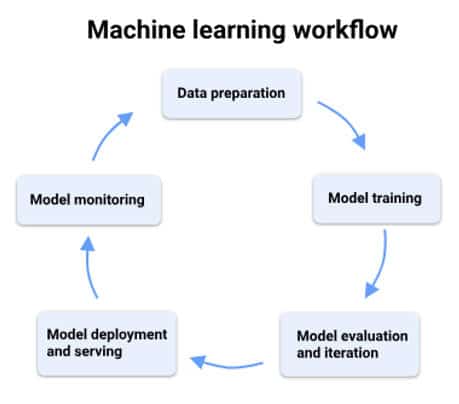
En partant du besoin jusqu’à la mise en production nous avons le worklow ML (« Data preparation », « Model training », « Model training », « Model evaluation and iteration », « Model deployment and serving », « Model monitoring »).
C’est autant de jeux de données, de paramètres, d’artéfacts, de résultats d’expérimentation qu’il s’agit de versionner pour sécuriser la mise en production. Nous entrons dans le domaine du MLOps (Machine learning operations)
Suite au prochain épisode… 😉


![[Data Rider] REX Collecte de données IoT – Étape 1 : Initier la collecte](https://fr.blog.businessdecision.com/wp-content/uploads/2025/05/data-rider-rex-collecte-donnees-1024x512-1.jpg)











Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.