
La méthode CRISP (initialement connue comme CRISP-DM) a été au départ développée par IBM dans les années 60 pour réaliser les projets Datamining. Elle reste aujourd’hui la seule méthode utilisable efficacement pour tous les projets Data Science.
Méthode CRISP : mode d’emploi
La méthode CRISP se décompose en 6 étapes allant de la compréhension du problème métier au déploiement et la mise en production.
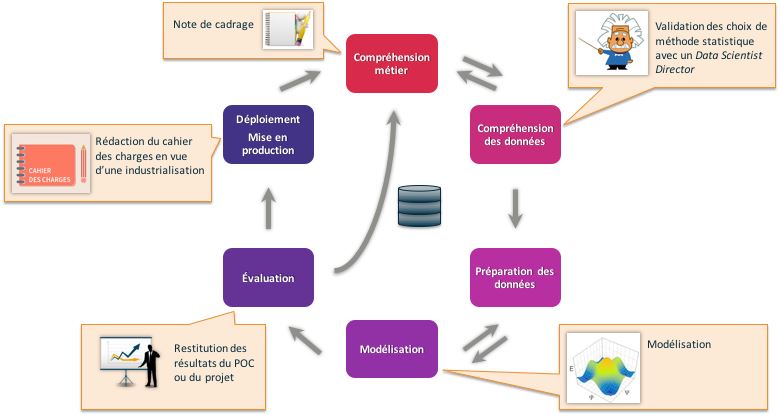
1. La compréhension du problème métier
La première étape consiste à bien comprendre les éléments métiers et problématiques que la Data Science vise à résoudre ou à améliorer.
2. La compréhension des données
Cette phase vise à déterminer précisément les données à analyser, à identifier la qualité des données disponibles et à faire le lien entre les données et leur signification d’un point de vue métier. La Data Science étant basée sur les données seules, les problèmes métiers relatifs à des données existantes, qu’elles soient internes ou externes, peuvent ainsi être résolus par la Data Science.
3. La construction du Data Hub
Cette phase de préparation des données regroupe les activités liées à la construction de l’ensemble précis des données à analyser, faite à partir des données brutes. Elle inclut ainsi le classement des données en fonction de critères choisis, le nettoyage des données, et surtout leur recodage pour les rendre compatibles avec les algorithmes qui seront utilisés.
La paramétricité des données numériques et leur recodage en données catégorielles sont extrêmement importantes et à réaliser avec soin afin d’éviter que les algorithmes utilisés donnent des résultats faux dans la phase suivante. Toutes ces données doivent en effet être centralisées dans une base de données structurée et qui porte le nom de Data Hub.
4. La modélisation
C’est la phase de Data Science proprement dite. La modélisation comprend le choix, le paramétrage et le test de différents algorithmes ainsi que leur enchaînement, qui constitue un modèle. Ce processus est d’abord descriptif pour générer de la connaissance, en expliquant pourquoi les choses se sont passées. Il devient ensuite prédictif en expliquant ce qu’il va se passer, puis prescriptif en permettant d’optimiser une situation future.
5. L’évaluation
L’évaluation vise à vérifier le(s) modèle(s) ou les connaissances obtenues afin de s’assurer qu’ils répondent aux objectifs formulés au début du processus. Elle contribue aussi à la décision de déploiement du modèle ou, si besoin est, à son amélioration. A ce stade, on teste notamment la robustesse et la précision des modèles obtenus.
6. Le déploiement
Il s’agit de l’étape finale du processus. Elle consiste en une mise en production pour les utilisateurs finaux des modèles obtenus. Son objectif : mettre la connaissance obtenue par la modélisation, dans une forme adaptée, et l’intégrer au processus de prise de décision.
Le déploiement peut ainsi aller, selon les objectifs, de la simple génération d’un rapport décrivant les connaissances obtenues jusqu’à la mise en place d’une application, permettant l’utilisation du modèle obtenu, pour la prédiction de valeurs inconnues d’un élément d’intérêt.
Une démarche agile et itérative
Cette méthode est agile et itérative, c’est-à-dire que chaque itération apporte de la connaissance métier supplémentaire qui permet de mieux aborder l’itération suivante. C’est d’ailleurs pour cette raison que, même si nous la vendons comme un projet, la Data Science est plus une démarche globale qu’un simple projet.
La méthode CRISP a été officiellement adoptée par Business & Decision et son utilisation constitue donc un facteur déterminant à la réussite des projets Data Science.
👉 Retrouvez toute notre actu en temps réel en nous suivant sur LinkedIn 👈


![[Data Rider] REX Collecte de données IoT – Étape 1 : Initier la collecte](https://fr.blog.businessdecision.com/wp-content/uploads/2025/05/data-rider-rex-collecte-donnees-1024x512-1.jpg)











Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.