
Quand on travaille dans le secteur des nouvelles technologies (souvent abstraites et complexes), ce n’est pas toujours simple d’expliquer le travail que nous réalisons ou encore le fonctionnement d’un programme. Je me suis donc prêté à un exercice de vulgarisation sur Apache Kafka avec comme objectif de pouvoir le faire comprendre à mes grands-parents.
J’aime bien utiliser les analogies de manière générale pour expliquer une chose abstraite et ainsi l’associer à quelque chose de concret et connu de tous. J’ai déjà utilisé les analogies de manière efficace sur plusieurs projets pour expliquer une situation à des clients ou à d’autres consultants. Même en étant du métier, comprendre le fonctionnement de tous ces outils complexes n’est pas toujours évident.
Dans cet article, je vais donc vous proposer plusieurs analogies pour vous expliquer le fonctionnement de Kafka. Pour des raisons de vulgarisation, certains points spécifiques seront simplifiés ou ignorés dans cet article. L’objectif visé est de permettre de comprendre le fonctionnement global de Kafka.
Le raisonnement par analogie est un merveilleux outil de travail.
François Michelin
Définition d’Apache Kafka
Lorsque l’on ne connait pas un outil informatique, on a souvent le réflexe d’en chercher une définition en ligne. Bien souvent, on arrive sur la définition de Wikipédia :
Apache Kafka est un projet à code source ouvert d’agent de messages développé par l’Apache Software Foundation et écrit en Scala. Le projet vise à fournir un système unifié, en temps réel à latence faible pour la manipulation de flux de données. Sa conception est fortement influencée par les journaux de transactions. (Wikipédia – https://fr.m.wikipedia.org/wiki/Apache_Kafka)
Cette première définition ne nous avance cependant pas beaucoup pour comprendre véritablement ce qu’est Kafka. En effet, elle fait référence à d’autres termes techniques, qui feront eux-mêmes aussi référence à d’autres termes techniques.
Je vous propose donc ma révision de la définition Wikipédia, une version simplifiée, avant de rentrer dans le vif du sujet :
Apache Kafka est un programme informatique, dont les lignes de code sont publiquement disponibles, gérant une multitude de boites aux lettres high-tech. Les messages peuvent être déposés et lus en temps-réel dans l’ordre d’arrivée (premier déposé, premier lu).
Analogie de la boite aux lettres
Kafka est un agent de messages, mais pour mieux comprendre son fonctionnement, imaginons ensemble qu’il s’agit d’un ensemble de plusieurs boîtes aux lettres.
Une histoire de voyage du courrier
Dans le jargon de Kafka, une boîte aux lettres s’appelle un topic.
Ainsi, comme dans la vraie vie, n’importe quelle personne connaissant l’adresse d’une boîte aux lettres donnée peut y déposer du courrier. On appelle message tout ce qui est déposé ou récupéré dans un topic Kafka.
Dans Kafka, ce ne sont pas des facteurs qui déposent le courrier mais des programmes informatiques nommés produceur. Et ce ne sont pas les habitants d’une maison ou d’un immeuble qui vont relever les messages, mais des consumer.
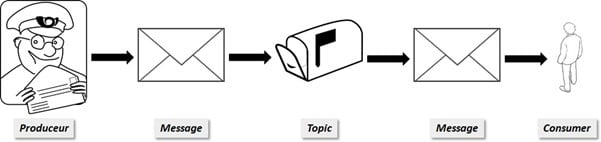
Nos facteurs informatiques (produceur) ajoutent donc des courriers (message) dans notre boîte aux lettres (topic). Les lettres s’empilent progressivement au fil du temps. D’autres programmes informatiques (consumer) vont ensuite venir lire les différents messages déposés.
Le facteur est-il passé ?
Pour faciliter le suivi du courrier, un tampon est ajouté avec la date et l’heure (timestamp) au moment du dépôt dans la boîte aux lettres. Un numéro unique de suivi est également inscrit. Le premier courrier obtient le nombre 1. Ensuite, on attribue au nouveau courrier la valeur du courrier précédent + 1. On appelle ce numéro un offset.

Le fonctionnement ressemble très fortement au tampon de prise en charge d’un courrier par La Poste qui est ajouté sur le timbre. L’ajout d’un numéro unique se rapproche d’un numéro de suivi d’un colis, ou d’une lettre suivie. La principale différence réside sur le moment où sont renseignées ces informations. Ce n’est pas la prise en charge par La Poste, mais bien le moment du dépôt dans la boîte aux lettres qui compte. Si l’offset du topic s’est incrémenté, c’est que le facteur est passé !
Une histoire de file d’attente
Notre topic est disponible sur le réseau informatique de l’entreprise. Tout programme pouvant y accéder peut lire les messages qu’il contient. Toute personne connaissant l’adresse et ayant une clé peut y accéder. Mais personne ne peut réellement prendre le courrier.
La boîte aux lettres vous lira d’abord le premier message qu’elle a reçu. Puis le deuxième, et ainsi de suite. On dépile les courriers dans l’ordre dans lequel ils ont été déposés. C’est la mécanique d’une queue ou file d’attente. On parle de FIFO : premier arrivé, premier servi (First In, First Out). La date (timestamp) de dépôt de chaque message sera également communiquée, tout comme son numéro unique.
Tutoriel
Spark Structured Streaming : de la gestion des données à la maintenance des traitements
Lire la suiteImaginons un tel fonctionnement sur notre boîte à lettres de maison. Nous ne pourrions pas récupérer notre courrier, mais un écran nous afficherait le contenu de chaque message. Toute personne passant devant la boîte pourrait ainsi venir lire les messages. Le premier message affiché serait le plus ancien. Et on pourrait passer d’un message à l’autre en remontant un par un les messages du plus ancien au plus récent.
Évidemment, tout le monde ne peut pas réellement accéder aux données de tous les topics. Il y a des options de sécurité pour limiter les accès. Il est important de bien comprendre que l’on peut avoir plusieurs Produceur et plusieurs Consumer indépendants pour un même topic, et que les messages sont lus dans l’ordre d’arrivée.
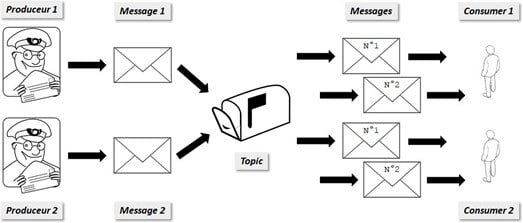
Une histoire de marque-page
On peut en réalité lire les courriers de cette boîte aux lettres de 3 façons différentes :
- Soit depuis le premier message (earliest). C’est ce que nous avons vu comme fonctionnement jusqu’à maintenant.
- Soit après le dernier message (latest). C’est-à-dire uniquement les nouveaux messages ajoutés depuis maintenant. Ces messages seront lus également par ordre d’arrivée. Imaginons une boîte aux lettres de quartier contenant tous les courriers de l’association du quartier. Il s’agit de courrier relatif à des évènements organisés par l’association. Si je suis nouveau dans le quartier, je ne souhaite lire que les nouveaux messages. Les évènements passés ne m’intéressent pas.
- Les messages entre 2 numéros uniques (specific offset) c’est à dire dont on connaît le numéro unique d’un courrier et pour lequel on demande de le relire, ou bien de relire les 10 courriers suivants (on donne alors 2 offsets précis). Pour pouvoir réaliser cela, il faut connaître l’historique de la boite aux lettres. Ce mode est plutôt utilisé pour venir relire des anciens messages qu’on aurait oublié. On peut l’utiliser pour rattraper des données après un incident.
Kafka ne nous indique pas automatiquement les nouveaux courriers reçus. C’est au consumer d’interroger le topic régulièrement pour récupérer les nouveautés. Kafka peut garder en mémoire l’offset du dernier message lu pour repartir automatiquement de cette position à la lecture suivante. C’est comme un marque- page dans un livre. Ce fonctionnement s’utilise si on lit les messages avec l’option earliest ou latest. En effet, cette option est utilisée pour savoir comment démarrer la lecture des messages, mais ensuite, les messages seront dépilés dans l’ordre d’arrivée. Ainsi, on ne repart pas à chaque lecture depuis le début du topic.
Il est aussi possible de sauvegarder de son côté l’offset du dernier message lu. C’est comme si nous écrivions sur un papier la dernière page lue de notre livre.
Quand nous voulons en reprendre la lecture, nous recherchons la bonne page afin de ne pas tout recommencer depuis le début. Pour des articles ou des livres scientifiques, nous pouvons noter des intervalles de pages ou de lignes intéressantes sur un sujet. Dans ce cas, nous savons exactement où trouver l’information que nous recherchons. C’est exactement le comme le mode specific offset dans lequel nous précisons un offset de début et un offset de fin.Une histoire de durée de vie et de clonage
Si on gardait tous les courriers reçus depuis toujours la boîte aux lettres serait vite remplie. Ainsi, une durée de vie (rétention) est définie pour chaque boîte aux lettres. Les courriers trop anciens sont donc détruits, même si personne n’a eu le temps de les lire.
Dans le cas où le nombre de messages est très important, une seule boite aux lettres ne suffira pas. Il est alors possible de regrouper plusieurs boîtes aux lettres comme étant une seule. C’est la même adresse pour toutes les boîtes, comme dans un hall d’immeuble. Chaque courrier va ainsi être mis dans une seule boîte aux lettres. Et il faudra ensuite consulter l’ensemble des boîtes aux lettres pour avoir la totalité des courriers.
Ce concept de plusieurs boîtes mutualisées est associé à la notion de partition dans Kafka. Heureusement, pour le consumer c’est transparent, il ne voit toujours qu’une seule boite aux lettres. Il peut tout de même savoir de quelle partition provient le message.
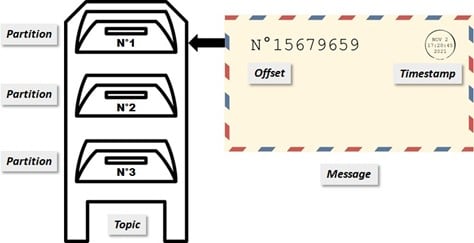
Ainsi, le numéro unique d’un message n’est plus seulement son offset, mais sa partition + son offset. En effet, chaque partition aura son propre compteur de messages et nous retrouverons donc les mêmes offsets dans chaque partition.
Chaque offset partira de 1 et s’incrémentera à l’arrivée de chaque message. Ensuite, les messages reçus seront distribués équitablement entre les 3 partitions.
Les systèmes comme Kafka fonctionnent généralement sur plusieurs machines pour répartir la charge et permettre d’être scalable, c’est à dire évolutif en termes de capacité de stockage et de traitement.
Ainsi, un broker est une machine de Kafka contenant une partie du topic : un sous- ensemble de partitions.
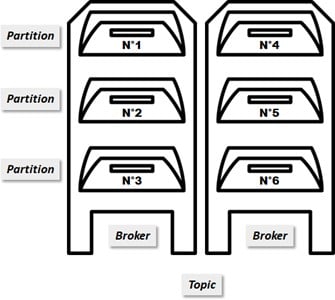
Pour des raisons de sécurité et de disponibilité, chaque partition (et ses messages) peut être clonée. On définit ainsi un facteur de réplication pour le topic. En général, on répartit nos différentes partitions clonées sur plusieurs brokers pour sécuriser nos messages.
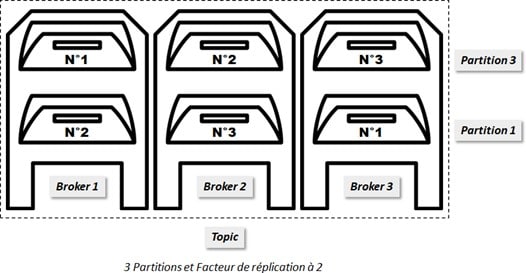
C’est comme si on faisait des photocopies de chaque message arrivant dans les boîtes aux lettres. Chaque boîte a des boîtes miroirs associées. Ainsi nous stockons le message et des copies dans des emplacements différents. De cette façon, si une colonne de boîtes aux lettres est en travaux ou vandalisée, nous pourrons toujours lire tous les messages en allant voir une boîte miroir.
Pour nos produceurs et nos consumers ce découpage en plusieurs partitions et brokers est plutôt transparent. Ce qui est visible, c’est la boîte aux lettres principale donc le topic. Et c’est Kafka qui va répartir les messages de manière équilibrée entre les différentes partitions.
Analogie du livreur de colis
Dans les systèmes de gestion de messages distribués, comme Kafka, il existe plusieurs niveaux de garantie de service :
- Aucune garantie de livraison du message
- Livraison du message une fois au mieux
- Livraison du message au moins une fois
- Livraison du message une et une seule fois
Imaginons que nous transposions cette garantie de service d’un message à nos commandes en ligne, et plus particulièrement au livreur qui amène notre colis.
Cas 1 : aucune garantie de livraison du colis
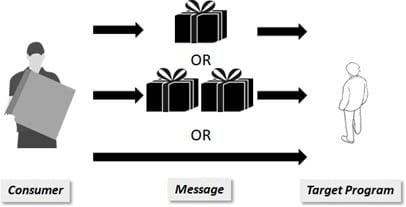
Dans ce premier cas, il n’y a aucune garantie après notre commande que nous recevions notre colis. Nous pourrions le recevoir, ne rien recevoir, mais nous pourrions aussi en recevoir plusieurs exemplaires. C’est un peu comme si on jouait à la loterie.
Avec un service de livraison pareil, il y a peu de chance que quelqu’un tente de commander chez eux.
Cas 2 : livraison du colis une fois au mieux
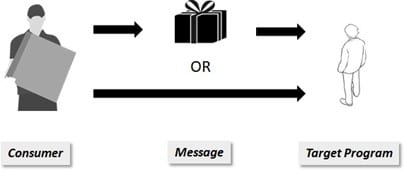
Ce niveau de service est encore un peu hasardeux. Soit je reçois mon colis, soit je ne le reçois pas. Mais je dois m’assurer que si le livreur sonne chez moi avec un colis, alors ce sera non seulement le bon colis, mais aussi que je n’aurais pas reçu ma commande en plusieurs exemplaires.
Ce niveau de livraison est moins instable que le premier, mais j’ai quand même le risque de ne jamais voir mon colis. On pourra dire que cette méthode est plus écologique car elle évite que je me fasse livrer plus que nécessaire.
Cas 3 : Livraison du colis au moins une fois
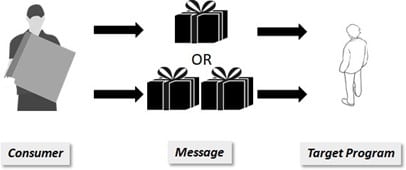
Le niveau de service augmente, je suis sûr et certains que je vais recevoir mon colis. Par contre, je pourrais en recevoir plusieurs exemplaires. C’est mauvais pour la planète, mais je suis certain d’avoir mon colis. Il va donc falloir que je vérifie mon colis à la réception, et que je le redonne au livreur si je l’ai déjà. Si c’est un objet pour lequel avoir plusieurs exemplaires n’est pas gênant, alors je garde tout ce que je reçois.
Cas 4 : Livraison du colis une et une seule fois
C’est le niveau de service par excellence. Je suis sûr et certain de recevoir mon colis, et je suis sûr d’avoir un seul exemplaire unique.
Bien évidemment, un tel niveau de service a un coût plus élevé car le livreur doit vérifier en amont que ma commande est bonne, et on doit contrôler qu’il m’a bien livré le colis une fois, et qu’il ne va pas m’être livré une seconde fois.
C’est le niveau de service vers lequel tout système de livraison tend à aller, mais c’est un Graal jamais atteint.
Quid du niveau de service de Kafka ?
Comme dans la vie réelle et les livraisons des colis, chaque entreprise va suivre votre commande et va tout faire pour livrer votre produit chez vous.
En commandant sur internet, nous avons (normalement) la garantie de recevoir notre colis, mais de temps en temps, nous pouvons avoir des surprises : le colis n’arrive jamais ou très tardivement, ou bien encore, on le reçoit 2 fois.
Un système de livraison parfait et sans erreur serait très complexe et coûteux.
C’est également pour cette raison, qu’en informatique, c’est généralement la garantie « Livraison du message au moins une fois » (cas 3) qui est utilisée. Les cas de doublons sont en réalité très rares, et on au moins la garantie de ne pas perdre de messages. On tend vers un message reçu une et une seule fois mais ce n’est pas garantie à 100%.
Selon les projets, on peut considérer comme acceptable d’avoir exceptionnellement un doublon. Par exemple, si on est sur un projet IOT, et qu’on suit la valeur d’un capteur de température, recevoir 2 fois l’information, qu’à 15h35 il faisait 19.5°, n’est pas gênant.
A contrario, si l’on est sur un projet bancaire qui suit les opérations réalisées sur les comptes, traiter 2 fois un débit de 550€ va avoir beaucoup d’impacts.
Ainsi, selon les projets, il faudra mettre en place ou non des sécurités supplémentaires au niveau du Consumer Kafka pour vérifier si la donnée a déjà été reçue.
J’espère que ces analogies vous ont permis de mieux comprendre le fonctionnement des systèmes de messages distribués comme Kafka. Ces systèmes sont au cœur des nouvelles architectures orientées micro-service, temps-réel et IOT. Comprendre leur mode de fonctionnement est indispensable pour comprendre les SI d’aujourd’hui et de demain.
La bonne nouvelle, c’est que les grands principes expliqués pour le fonctionnement de Kafka sont similaires sur d’autres technologies comme Google Pub/Sub ou encore RabbitMQ.
👉 Retrouvez toute notre actu en temps réel en nous suivant sur LinkedIn 👈


![[Data Rider] REX Collecte de données IoT – Étape 1 : Initier la collecte](https://fr.blog.businessdecision.com/wp-content/uploads/2025/05/data-rider-rex-collecte-donnees-1024x512-1.jpg)











Commentaires (4)
Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.
Par ailleurs, je ne suis pas grand-mère encore. ;-)