
Dans le cadre d’une migration/standardisation d’un patrimoine applicatif de Cloudera v6 vers Cloudera Data Platform v7, et au vu du nombre de projets (~70) écrits en Spark-Scala ou PySpark-Python à porter, nous avons choisi de développer un programme pour automatiser une partie des transformations : changement des noms des tables, des chemins HDFS, nom de projet,… Dans cet article, nous allons vous en dire un peu plus sur son fonctionnement. Il pourrait peut-être vous servir pour votre prochaine migration.
Dictionnaires de données (tronc commun)
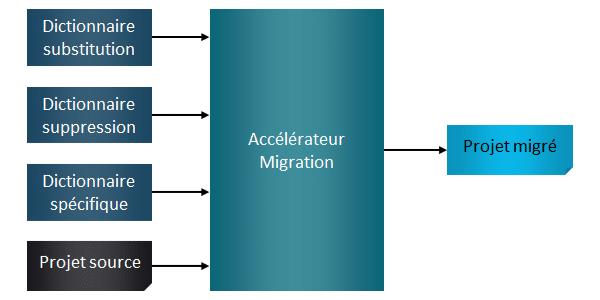
Tout d’abord, nous avons identifié des substitutions communes à tous les projets, ce qui nous a permis de définir plusieurs dictionnaires de données (collections de métadonnées), conformément aux nouveaux standards dictés par un client du domaine courrier et colis. Nous avons ainsi plusieurs dictionnaires à disposition pour gérer ces changements :
- Remplacer des chemins linux commun
- Remplacer des valeurs ou noms de variables faisant référence à l’ancienne plateforme
- Supprimer des valeurs ou variables qui n’ont plus de sens (nettoyage)
Les changements apportés par les dictionnaires de données sont simples, mais ils permettent de gagner en temps et en qualité sur la migration. Ils ont aussi le mérite d’être transverses à tous les projets devant être migrés.
Le principal travail réalisé sur cette étape se trouve donc dans la constitution de ces dictionnaires de données.
Fichier d’instruction (spécifique par projet)
Certains changements sont spécifiques aux différents projets. Par exemple, les chemins HDFS (Hadoop Distributed File System), le nom des tables ou encore les noms de scripts d’alimentation. Ces détails sont fournis par le client au travers de fichiers d’instructions (Excel), propres à chaque projet. Ces spécifications peuvent évidemment être utilisées pour un portage manuel, mais comme la donnée est structurée, cela permet d’en tirer profit pour automatiser les transformations.
Nous avons donc adapté notre programme de migration pour prendre en compte ce fichier d’instruction. Cela nous permet alors de générer un nouveau dictionnaire de données spécifique à chaque projet. La qualité de rédaction et la structuration de ce fichier sont cruciales car elles conditionnent le contenu du dictionnaire de données de sortie.
Projet source à migrer
Ainsi, en entrée de notre outil de migration, nous avons des dictionnaires de données communs à tous les projets, le fichier d’instruction (dictionnaire spécifique) du projet, et bien évidemment le code source du projet d’origine.
Une fois l’exécution du programme de migration terminée, nous nous retrouvons avec un nouveau dossier de sortie contenant le programme migré du projet.
Actions manuelles à plus forte valeur ajoutée
Pour terminer la migration, il peut rester des actions manuelles à réaliser : regroupement/découpage de traitements ordonnancés, refactorisation, suppression de code mort… Ces actions restantes demanderont plus de réflexion, et auront donc plus de valeur ajoutée.
Une migration technique pure ne nécessiterait théoriquement aucune étape manuelle. Mais bien souvent, on profite d’une migration pour remettre aux normes certains projets, refactoriser certains traitements, utiliser de nouvelles fonctions ou faire de l’optimisation.
Ainsi, le code est amendé au cas par cas, sans nécessiter de réécriture globale.
Afin de vérifier que le portage réalise bien toujours les mêmes transformations, nous vous conseillons de réaliser des TNR (Test de Non-Régression) directement après les étapes de migration automatique. Les actions à plus forte valeur ajoutée, même si elles sont légitimes, sont plus risquées car elles peuvent introduire des divergences de comportement. En cas d’écarts, il sera donc plus compliqué de déterminer l’origine du problème. Une première validation permet de taguer votre nouveau projet comme migré avec succès, et donc d’avoir un point de référence.
Tutoriel
Spark Structured Streaming : de la gestion des données à la maintenance des traitements
Lire la suiteTNR (Test de Non-Régression)
Comme indiqué précédemment, après avoir réalisé la migration, il est nécessaire de la valider avec des Tests de Non-Régression. Là encore, nous avons des accélérateurs disponibles pour cette phase du projet. Nous avons deux outils distincts pouvant s’adapter facilement à tous les contextes.
Ces accélérateurs permettent d’automatiser une bonne partie des tests pour s’assurer que le programme porté donne le même résultat que le programme d’origine pour le même périmètre de données. Si ces accélérateurs de TNR vous intéressent, n’hésitez pas à me l’indiquer en commentaire, et je pourrais écrire un article dédié sur le sujet.
Accélérateur de migration : les axes d’amélioration
L’accélérateur de migration nous a permis de gagner du temps, et de garantir une excellente qualité des projets livrés. Mais nous souhaitons aller encore plus loin et continuer à l’enrichir pour obtenir un check-up/audit du code existant et du code migré afin d’avoir des métriques sur les types de fichiers présents, les fonctions les plus utilisées, une redondance de code, des contrôles de qualité.
Ainsi, même si un projet a déjà été migré, nous pourrions le repasser pour identifier les changements à apporter pour correspondre aux nouvelles normes. Avec bien sûr la migration automatique de ce qui peut l’être, mais également l’identification des actions nécessitant une action manuelle.
Autre axe d’amélioration, la possibilité de définir un référentiel des projets à migrer afin de pouvoir récupérer automatiquement les projets sources (depuis GitLab par exemple), et appliquer ensuite leur migration. Ce référentiel contiendrait également le type de projet pour pouvoir gérer plusieurs fichiers d’instructions différents si c’était le cas. Nous développerons dans ce cas plusieurs adapteurs pour générer le dictionnaire spécifique selon le type du projet.
Optimiser la phase de migration
L’utilisation de cet accélérateur nous a permis de gagner du temps dans la phase de migration. Sur les projets assez standard de migration, le gain peut être de 50 à 75% sur la migration. S’il y a plus que de la migration et donc beaucoup de manuel, il peut être de 15 à 50%.
Les règles de migration et le format des fichiers d’instruction ayant évolué plusieurs fois au cours du temps, cela a constitué un frein majeur à la migration. Ainsi, les premiers projets migrés n’étaient plus sur les mêmes normes que les suivants. Pour éviter de démarrer avec des écarts de normes, nous avons donc repris les anciens projets pour les adapter.
Lors de cette mission, le remplacement technique en lui-même était simple, mais la disparité des projets existants (langages, normes de développement très différents) a fait que les actions manuelles ont constitué la plus grosse partie de la migration.
Pour précision, notre outil de migration est utilisé dans le cadre de ce projet sur du code Spark-Scala et PySpark, mais il peut s’adapter à n’importe quel programme utilisant du code. L’accélérateur a une base de code fixe, qui est ensuite adaptable à chaque contexte projet pour répondre aux besoins spécifiques. Ce n’est donc pas une solution magique qui s’utilise en un clic sur un nouveau projet. Cependant, c’est aussi sa force puisqu’il peut s’adapter précisément à chaque besoin. Notre rôle est donc justement de l’adapter pour rendre plus efficace votre migration.
✍️ Cet article a été co-écrit avec Timothée Aupetit.














Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.