
L’exploitation de tout le potentiel de vos projets Big Data nécessite une bonne documentation de vos données. Les principes DataOps favorise la mise en place d’une démarche appropriée, essentielle pour mener efficacement tous les projets qui vont en découler et donner de la valeur aux données de votre entreprise.
Spécificités des projets Big Data
Une architecture Big Data moderne doit permettre :
- des restitutions s’appuyant sur un large spectre de données (décisionnel 3.0)
- des analyses avancées mettant en œuvre des algorithmes statistiques, du machine learning, de l’intelligence artificielle (Data Science)
- de construire des applications opérationnelles orientées data comme par exemple une vision 360 des entreprises ou un moteur de recommandation pour un site marchand
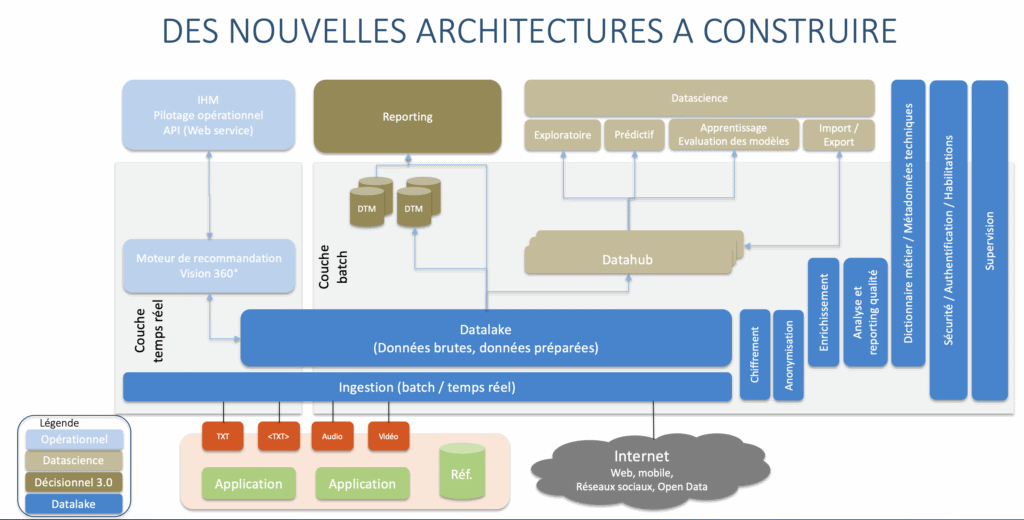
Pour atteindre cet objectif, les données de l’entreprise sont centralisées au sein d’un datalake destiné à servir les différents usages (architecture data centric). Avec l’engouement des métiers pour ce nouvel outil, le datalake peut rapidement prendre de l’ampleur : nous connaissons ainsi une entreprise qui héberge plus de 400 databases et près de 70 000 tables au sein de son datalake.
Comment s’y retrouver dans ce lac de données ?
Tout d’abord, en s’appuyant sur une documentation exhaustive qui cartographie les données existantes :
- nom
- description
- règle de gestion
- données sources nécessaires au calcul de la donnée
- données à caractère personnel pour le RGPD
- etc.
L’expérience montre par ailleurs que cette documentation doit être réalisée pendant la construction du projet Big Data sous peine de n’être jamais finalisée.
On peut alors se demander quelles sont les solutions disponibles sur le marché pour nous aider dans cette démarche DataOps ?
Solutions de cartographie des données
Les outils de modélisation
Les outils de modélisation comme PowerDesigner peuvent être utilisés pour cartographier les données dans une certaine mesure via un champ de description. Ils ne permettent pas en revanche de documenter les données de manière complète. Ce sont des outils très techniques qui ne permettent pas le partage de la documentation vers les métiers.
Leur principal intérêt est de pouvoir générer un modèle visuel représentant les liens fonctionnels entre nos tables. Nous n’avons rien trouvé de mieux pour faire comprendre un modèle à des utilisateurs avancés.
Le deuxième intérêt est de pouvoir, a priori, générer le modèle avec la description des données directement dans le système cible. Mais le support de Hive et plus encore des bases noSql sont encore limités.
A date, les entreprises utilisent de moins en moins ces solutions de dataviz ou leur préfèrent des solutions plus limitées mais gratuites comme Valentina Studio.
Les outils agiles
Les projets Big Data sont souvent menés en adoptant une méthode agile. La solution Confluence permet ainsi de décrire facilement des user story (récit utilisateur), mais est ce une bonne solution pour documenter un projet data ? Assurément non. Je vois deux freins principaux à cela :
- la solution est orientée usage (approche verticale pour un groupe d’utilisateurs) et ne se prête pas à la description de tables (approche transverse car une table peut servir différents usages).
- l’interface web est un frein à la saisie de masse sur des projets Big Data (Nous avons réalisé dernièrement un projet comportant près de 5 000 données différentes).
Les outils de cartographie
La solution semble simple. Pour cartographier les données d’un projet, rien de mieux qu’un outil de cartographie ! 🙂
L’outil qui monte en ce moment s’appelle Data Galaxy.
Data Galaxy est une solution web. Il y a toujours un frein à la saisie, mais elle propose un assistant pour importer massivement des données à partir d’un fichier .csv que l’on génèrera manuellement à partir d’un outil de modélisation par exemple.
Le point fort de la solution est sans conteste le partage de la documentation auprès des utilisateurs. Il est possible de faire des recherches dans les données, de réaliser des analyses d’impact, de collaborer entre utilisateurs pour indiquer à un administrateur de corriger, par exemple, une description erronée.
Data Galaxy sera excellent pour partager la documentation des données, une fois le projet terminé. En revanche, son aide sera limitée pendant la réalisation du projet du fait des limitations de la saisie.
Présentation de iSpecs
Suite au constat qu’aucune solution de base de données n’était réellement satisfaisante, nous avons eu l’idée de développer notre propre solution, afin d’optimiser le processus de DataOps.
Contrairement aux autres solutions, iSpecs (pour industrialisation des Spécifications) a été conçu pour nous aider à spécifier des projets Data d’envergure. La fonctionnalité principale de cet outil est en effet de contrôler la cohérence globale des spécifications. Mais comme vous le verrez, elle peut faire bien plus.
Un template Excel pour faciliter la saisie
Comme nous l’avons vu avec les solutions du marché, les interfaces web ne se prêtent pas trop à la saisie de masse. Nous avons donc opté pour un bon vieux fichier Excel disponible dans toutes les entreprises. Excel présente à nos yeux de nombreux avantages :
- tout le monde sait l’utiliser
- fonctionnalité puissante de copier / coller
- possibilité d’étendre une colonne en dupliquant la valeur d’une cellule
- volet pour faciliter la visualisation
- etc. (pas la peine de vous faire un cours sur le sujet)
Afin de rester le plus ouvert possible, nous nous sommes gardés de mettre des macros.
Nous avons seulement développé un template Excel très simple avec quelques onglets comprenant uniquement des fonctionnalités de base d’Excel :
- protection des cellules pour éviter les modifications malencontreuses
- liste de choix pour certaines colonnes
Il y aura un classeur par table. Cela facilite le travail collaboratif en permettant à plusieurs personnes de travailler en parallèle sur des fichiers différents.
Chaque classeur contient plusieurs onglets. Les deux premiers onglets servent à spécifier la table, les onglets suivants permettent de décrire un cas de test. Un cas de test contient les jeux de données en entrée, nécessaire pour alimenter notre table et le résultat attendu. Le cas de test permet de s’assurer au travers d’exemples qu’il n’y a pas d’ambiguïté dans les formats de données. Par ailleurs, ils peuvent servir de manière opérationnelle à tester notre chaîne de traitement en phase de développement.
Voilà à quoi ressemble notre fameux template :
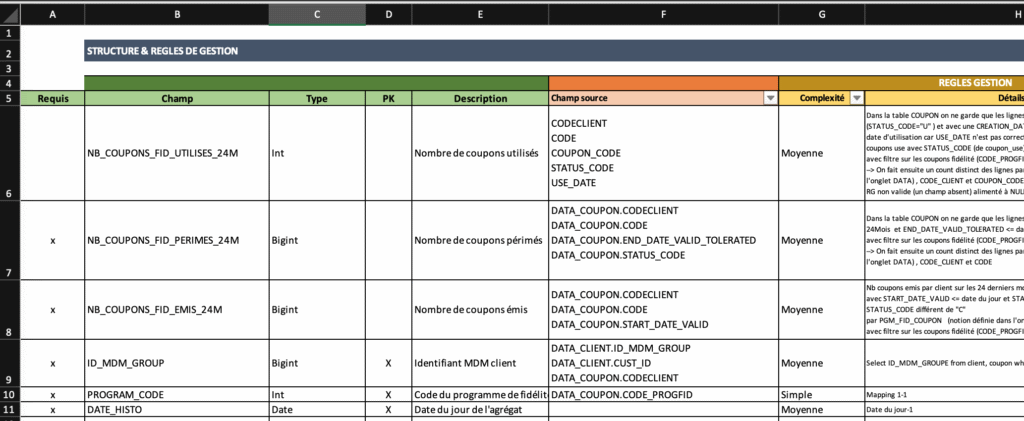
A noter que certaines cellules peuvent être multi-lignes.
Une application pour analyser et contrôler les spécifications
Que faire de tous ces fichiers de données maintenant ? Nous avons développé une application web en python. Pour le stockage des données, nous utilisons MongoDB.
Cette application est très simple à utiliser. On dépose les fichiers de spécifications dans un répertoire. Puis, on lance l’application. Et enfin, on clique sur « Load data » et le tour est joué.
Lors de l’intégration, nous en profitons pour formater les données et normaliser ainsi l’affichage ultérieur. Les cellules multi-lignes sont gérées comme des tableaux.
Voici une vue de l’application une fois les données chargées :
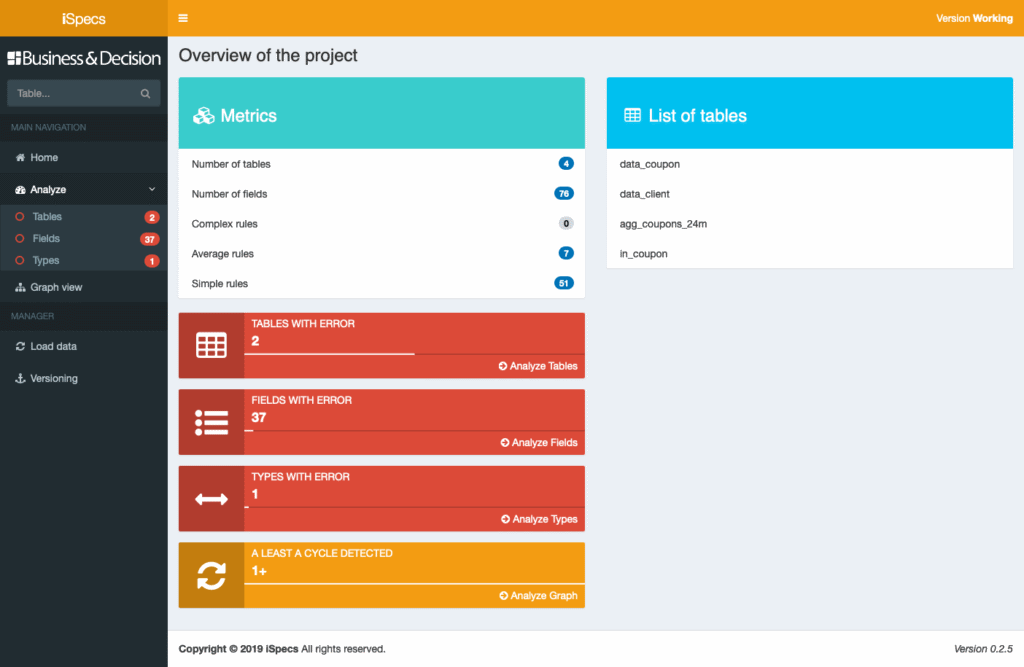
L’application présente les métriques du projet (nombre de tables, de champs, nombre de règles par complexité).
On visualise aussi directement les erreurs dans notre projet. Sur cet exemple, on a 2 tables en erreurs ce qui signifie que certains champs sont calculés à partir des données de deux tables qui n’existent pas.
En cliquant sur le lien, on visualise directement les tables manquantes et les champs que l’on ne peut pas alimenter.
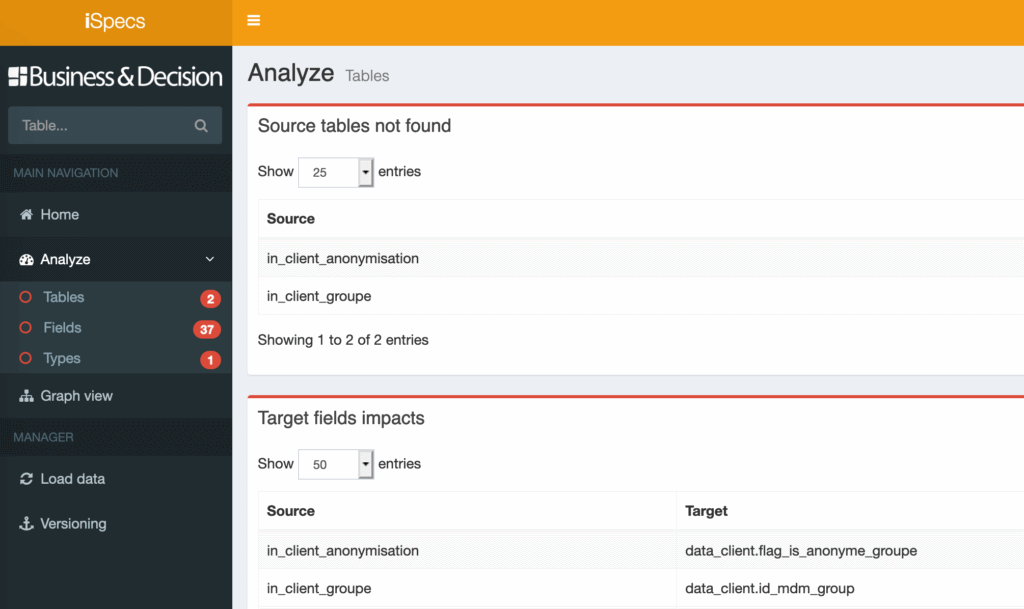
Il suffit maintenant de corriger les erreurs dans le ou les fichier(s) source(s). Dès que cela est terminé, on recharge les données afin de s’assurer que les erreurs ont disparu.
Un contrôle similaire est réalisé directement au niveau des champs. Enfin, pour les champs sans transformation (mapping 1-1), on s’assure que le type est inchangé entre l’entrée et la sortie.
Les spécifications peuvent être versionnées de manière très simple. L’intérêt principal est de pouvoir travailler en mode agile sur plusieurs versions en parallèle.
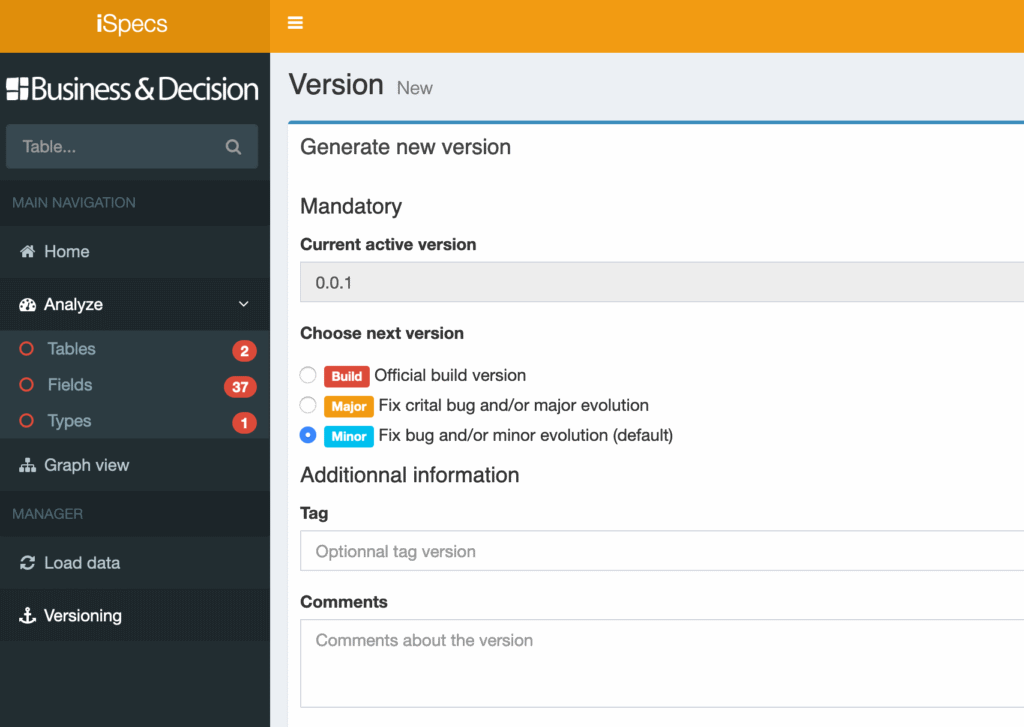
La génération automatique d’une documentation
L’application web permet de naviguer dans les tables et de visualiser les données. Un module de recherche facilite l’accès direct à l’information.
L’application génère aussi un dictionnaire de données complet au format Excel pour faciliter le partage avec le plus grand nombre d’utilisateurs sans problématique de licence.
Pour une solution plus évoluée, il serait envisageable de coupler iSpecs avec Data Galaxy ou Confluence afin de profiter des possibilités de partage et de collaboration des documents de bases de données.
Et plus encore
L’application iSpecs ne se contente pas de générer un dictionnaire pour les utilisateurs.
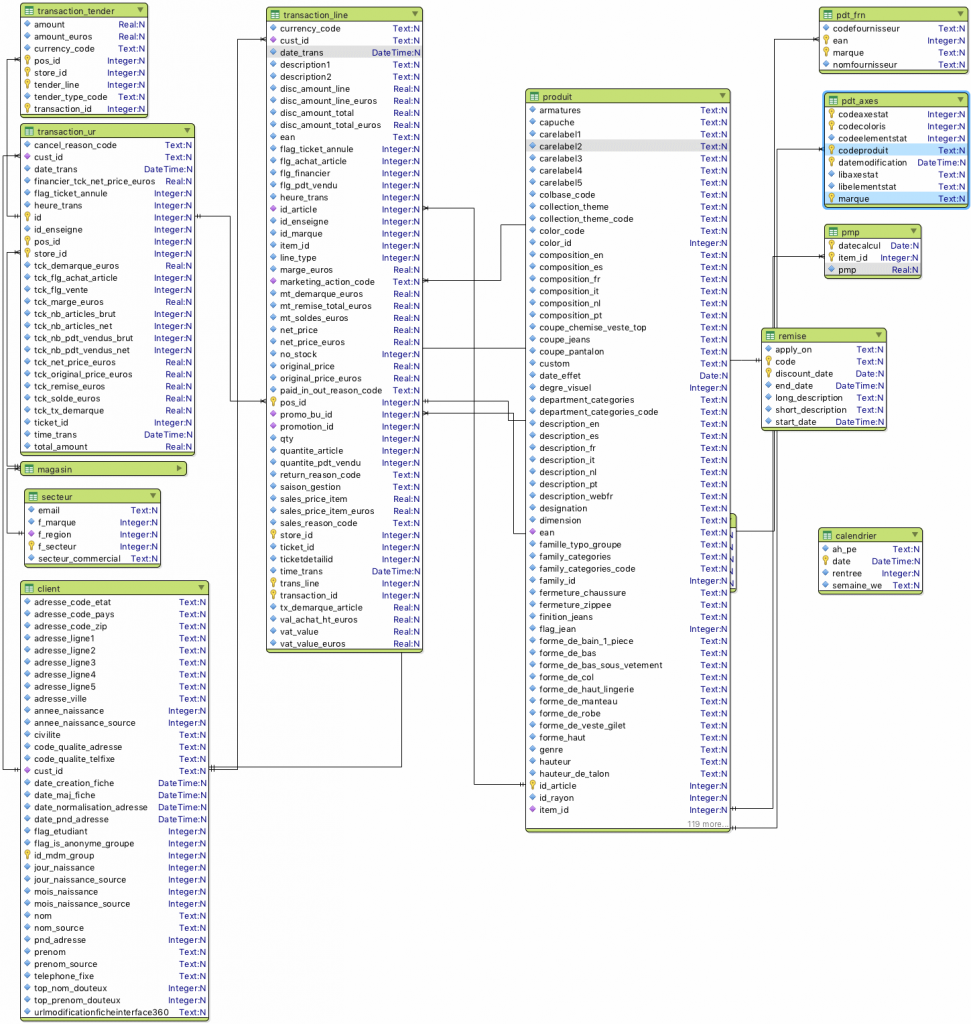
Elle génère les ordres de création des tables (ddl) afin d’automatiser la création de tables Hive (ces ddl sont également utilisées par notre solution iTests pour automatiser les tests avec Spark).
L’application génère également des ddl au format Valentina Studio afin de pouvoir restituer une vue graphique du modèle de données.
Enfin, l’application iSpecs est capable de faire de l’analyse d’impact en déterminant les liens d’alimentation entre tables. Le premier objectif de ce module est de pouvoir détecter des boucles éventuelles au sein des graphes, ce qui serait une erreur dans la conception (cela peut se produire sur des projets complexes avec de nombreuses tables. Et la détection de ces problèmes n’est pas si simple).
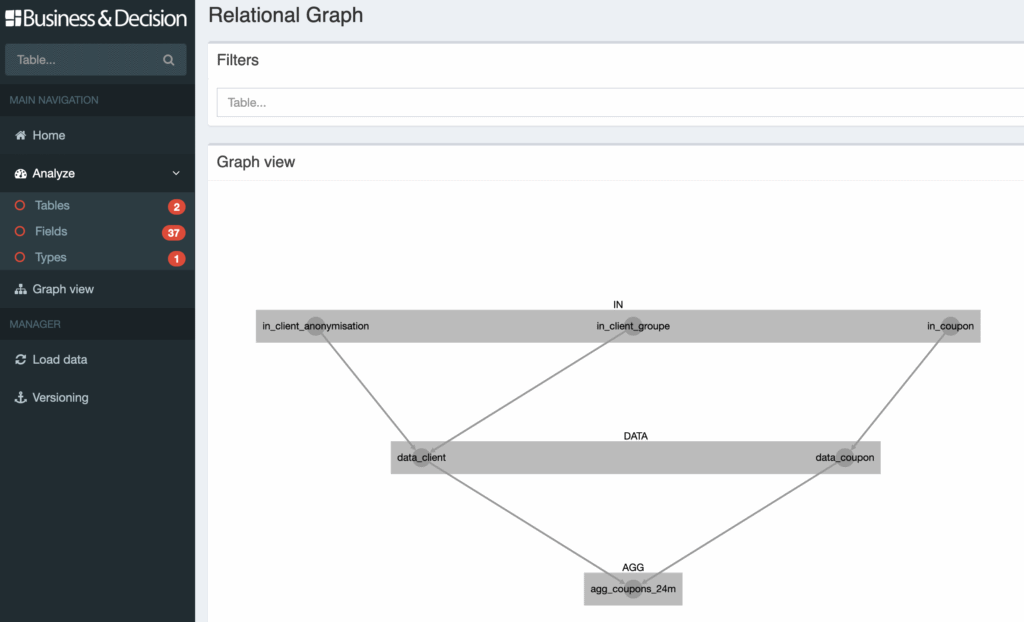
C’est un module sur lequel nous travaillons encore. Outre l’analyse d’impact, nous devrions être capable sous peu de générer un plan d’ordonnancement complet des traitements, simplement à partir des spécifications.
Une voie vers l’intégration continue
Comme vous le voyez, iSpecs ne se résume pas à la génération d’une documentation. C’est un véritable outil pour vous aider à construire votre projet Big Data.
Il a été pensé pour augmenter la cohérence globale des spécifications. Il automatise de nombreuses opérations ce qui permet de l’utiliser dans un contexte agile sans surcharger le coût de réalisation des spécifications.
Associé à notre application iTests et du DataOps, c’est un moyen formidable de mettre un premier pied dans le monde de l’intégration continue.
Cet outil est utilisé sur tous les projets Big Data de Business & Decision.
Contactez-nous pour en savoir plus ou pour avoir une démonstration.
👉 Retrouvez toute notre actu en temps réel en nous suivant sur LinkedIn 👈


![[Data Rider] REX Collecte de données IoT – Étape 1 : Initier la collecte](https://fr.blog.businessdecision.com/wp-content/uploads/2025/05/data-rider-rex-collecte-donnees-1024x512-1.jpg)











Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.