
Vous souhaitez utiliser le MLOps dans votre projet d’intelligence artificielle, sans consacrer trop du temps au développement, ou sans avoir les compétences nécessaires en codage ? Rassurez-vous, nul besoin d’être un ténor du code pour s’assurer que vos modèles en production sont toujours cohérents avec les données actualisées…
Il est possible d’utiliser des techniques de MLOps dans des logiciels éditeurs comme Dataiku. En effet, Dataiku DSS permet de gérer efficacement le cycle de vie des modèles de Machine Learning en production. Avant de détailler l’utilisation des différents processus MLOps dans l’outil, il est important de comprendre comment fonctionne la création d’un modèle de Machine Learning dans Dataiku.
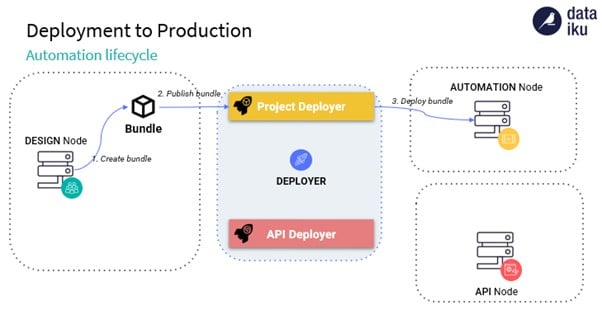
Le Machine Learning dans Dataiku
Dans la partie Lab de l’outil, il est possible de créer différents modèles de prédiction en simultané. L’outil va conserver les paramètres optimisant les mesures choisies (dans l’exemple la mesure que l’on cherche à optimiser est l’aire sous la courbe ROC). Pour chaque type de modèle, les mesures ROC AUC sont comparées pour nous permettre de choisir le modèle le plus performant.
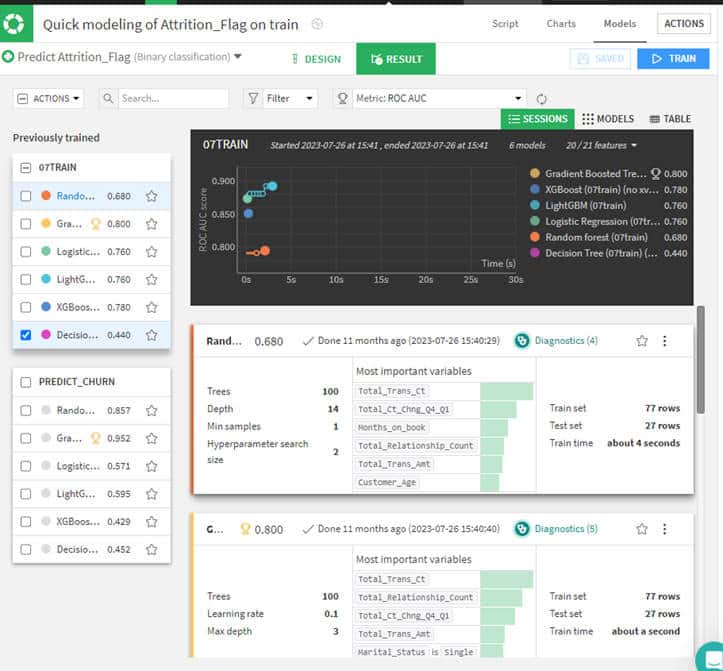
Comment s’assurer que notre modèle est toujours performant au fil du temps ?
Toute personne sensibilisée au Machine Learning sait que le modèle qu’il a construit à un instant T, risque de voir sa performance diminuer au fil du temps.
Prenons un exemple concret :
En mars 2023, Anna-Lise entraine un modèle qui permet de détecter le risque d’attrition d’un client pour une banque. Le modèle donne la bonne prédiction dans 88% des cas, il est mis en production afin de permettre aux équipes dédiées d’identifier les clients susceptibles de fermer leur compte bancaire. Courant janvier 2024, Anna reçoit des mails provenant du service clientèle, l’informant que son modèle n’identifie plus les départs de client de manière fiable. Résultats : les équipes concentrent leurs efforts sur des clients fidèles et de nombreuses clôtures de compte n’ont pu être évitées. Mais pourquoi le modèle n’est plus aussi fiable ?
Analyser les dérives des données d’entrée
Un des biais parmi les plus courants est dû à l’évolution des données en entrée. Le modèle étant entrainé en mars 2023, apprend sur des données antérieures. Il détermine que si un client a moins de 30 ans, un revenu mensuel de moins de 1500 euros et est célibataire, il a plus de chance d’être à l’écoute du marché. Cependant ces caractéristiques ne sont plus forcément déterminantes en 2024. Aujourd’hui ce client a potentiellement sa situation matrimoniale qui a évolué ou reçu une promotion et pourtant toujours susceptible de partir. Ainsi, en ré-entrainant son modèle sur des données de 2023, Anna se rend compte que les critères les plus déterminant ne sont plus l’âge ou le salaire, mais la ville et le nombre de dépenses enregistrées au cours des 3 derniers mois. Il s’agit là d’une vulgarisation, le problème est bien évidemment plus complexe que cela.
Cette situation d’urgence aurait pu être évitée grâce au monitoring du modèle en production. Dans Dataiku, il est possible de contrôler la performance du modèle grâce à la recipe « evaluate » et de stocker les mesures dans un « evaluation store ».
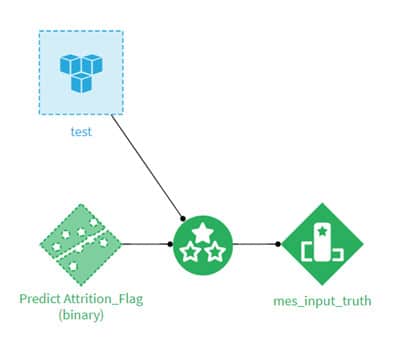
Analyser la dérive des données d’entrée
On peut dans un premier temps analyser la dérive des données d’entrée même si celles-ci ne sont pas labellisées. Ainsi, lorsqu’Anna va recevoir les données du mois en cours, il n’est pas encore possible de savoir si le client est parti ou non, elle ne connaît donc pas la réalité terrain. Pourtant, grâce à des tests statistiques, Dataiku va détecter si les données à prédire sont bien représentées par les données d’entrainement du modèle.
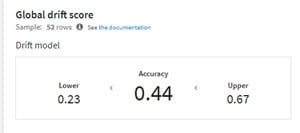
Le graphique ci-dessous représente l’estimation de la densité de probabilité pour une classe de prédiction donnée lors de l’évaluation du dataset test et du dataset d’entrainement. Des estimations de densité de probabilité visuellement différentes indiquent une forte dérive des données. Ici, on voit que les courbes ne sont pas très différentes visuellement.
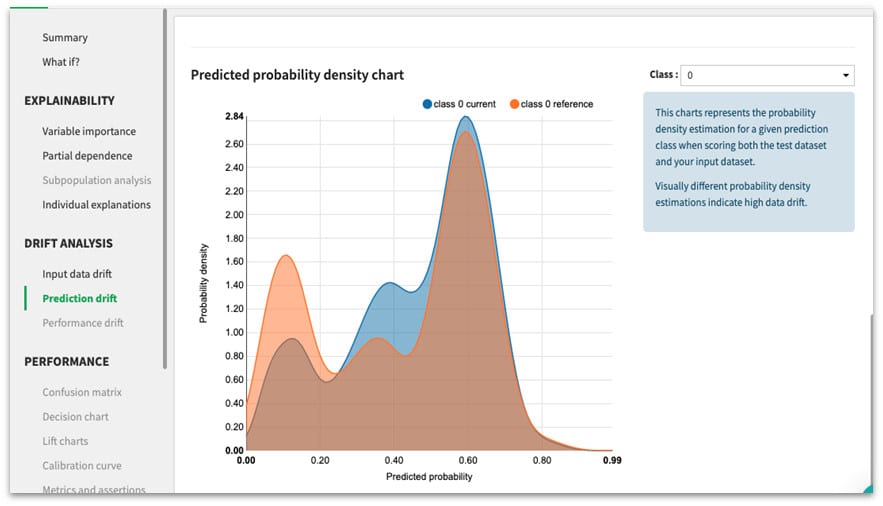
Dataiku teste l’hypothèse de la dérive des données d’entrée grâce à un classifieur de type random forest et un test binomial. Ici, la probabilité de dérive des données est inférieure à 0.5, L’outil nous indique donc qu’il n’y a pas de dérive majeure des données au global.
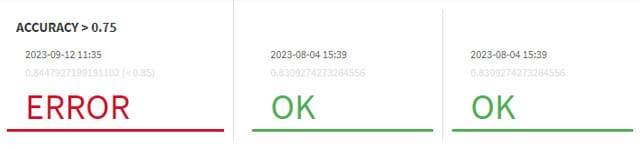
Pour surveiller la dérive des données à chaque nouvelle mise à jour de données, il est possible de mettre en place des contrôles (appelés « checks » dans DSS). Ils vont nous permettent de nous alerter et, potentiellement, de déclencher des actions en cas de warning ou d’erreur.
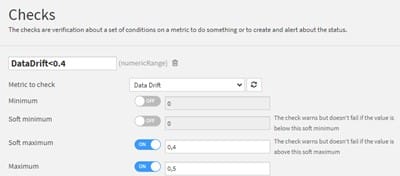
Sur l’image nous avons créé un contrôle qui renverra :
- OK si la mesure « Data Drift » est inférieure à 0.4
- Warning si la mesure est comprise entre 0.4 et 0.5
- Error si la mesure est supérieure à 0.5
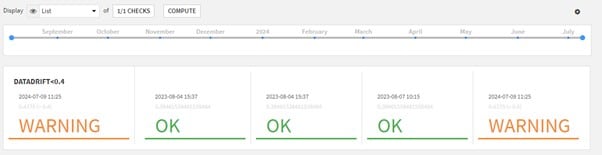
On peut visualiser ce contrôle grâce à la vue en mosaïque dans le model evaluation store.
Analyser la dérive du modèle
Lorsque nous avons des données labellisées, nous pouvons analyser directement la dérive des mesures de performance du modèle.
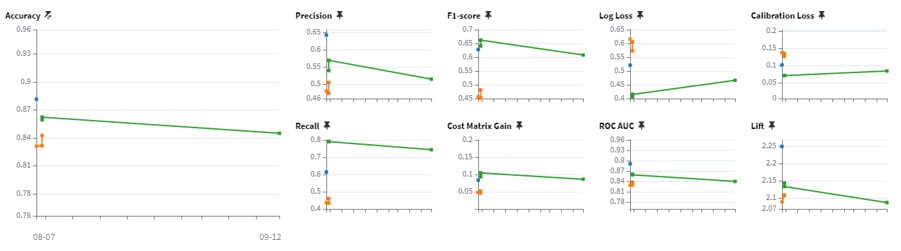
L’image ci-dessus représente l’évolution des mesures de performance du modèle au fil du temps. Chaque courbe représente une version déployée du modèle de prédiction. Si l’on constate une trop grosse dégradation des performances, cela signifie alors que le modèle doit être ré-entraîné. De la même manière que précédemment, il est possible de mettre en place des contrôles pour nous alerter lorsque ces mesures dépassent un certain seuil.
Automatisation de ces taches
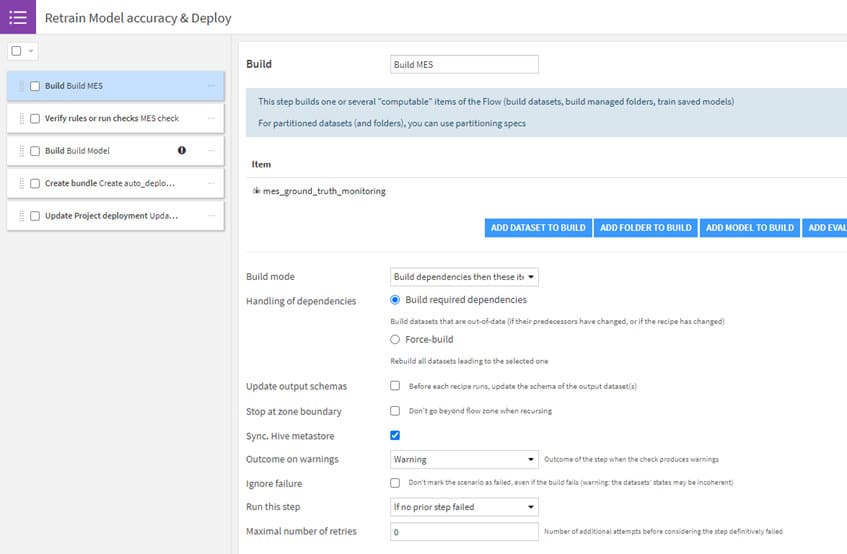
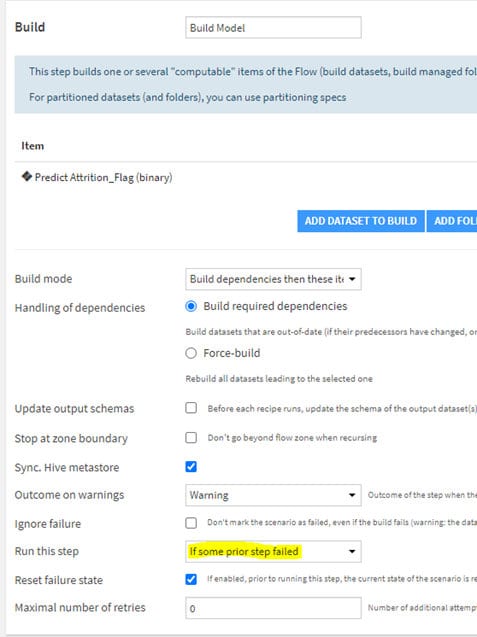
Bien évidemment, il n’est pas nécessaire que notre Data Scientist ouvre l’outil tous les jours pour contrôler les performances et lancer le ré-entraînement du modèle. Il est possible d’automatiser le monitoring grâce aux scénarios.
🔎 « Mais dis-moi Jamy, qu’est-ce qu’un scénario ? »
Il s’agit d’un ensemble d’actions à réaliser avec une ou plusieurs conditions pour l’exécuter. Dataiku DSS lance automatiquement les scénarios dont les conditions sont satisfaites.
Un scénario regroupe 3 concepts :
• Les « steps » ou le script : ce sont les actions qui seront lancées lorsque le scénario sera exécuté.
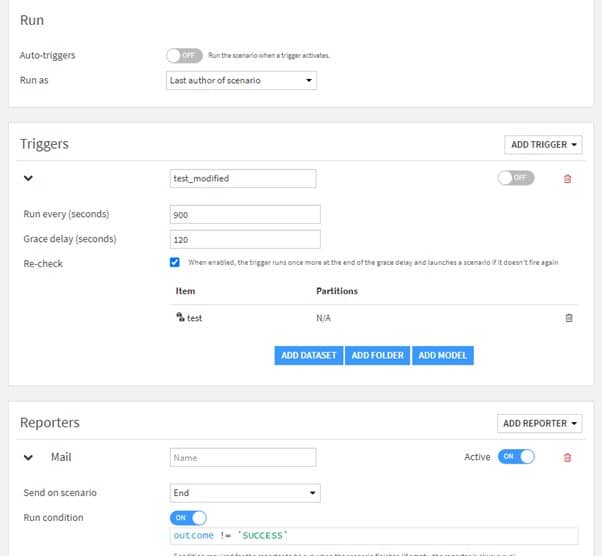
• Les « triggers » qui sont les déclencheurs. C’est ce qui va lancer le scénario. Il peut s’agir de conditions temporelles (tous les lundis par ex), d’une mise à jour de dataset, etc.
• Les « reporters » (facultatifs) qui sont des rapports. Ils peuvent être envoyés au début ou à la fin de l’exécution d’un scénario. Cela peut être un mail, ou un message dans un canal Teams par exemple.
Concernant le cas d’usage bancaire, Anna-Lise peut alors automatiser le monitoring de ses modèles de la manière suivante :
- Un premier scénario qui tourne tous les jours : il va permettre de récupérer les prédictions du modèle en production sur les nouvelles données et de construire les modèles évaluation store (mesures et contrôles associés).
- Un deuxième scénario qui se déclenchera lorsque les mesures de performances du modèle (construites dans le premier scénario) ne seront plus satisfaisantes (check en erreur). Ce scénario ré-entrainera alors le modèle en intégrant les dernières données labellisées. Si le nouveau modèle est plus performant, alors il sera mis en production.
En résumé : quel est l’intérêt du MLOps ?
- Versionner les modèles (Industrialiser)
- Suivre la performance du/des modèles en production (Robustesse)
- Disposer d’un process industriel dans le déploiement des modèles (Maitrise)
Pourquoi utiliser un outil éditeur pour faire du MLOps ?
Il est intéressant de se tourner vers un outil éditeur type Dataiku si :
- Votre équipe est plutôt habituée à implémenter à travers des composants déjà préconfigurés.
- Vous souhaitez vous appuyer sur des modèles existants.
- Vous disposez d’une équipe Data Science réduite.
Cette solution présente de nombreux avantages :
- Même si DSS a son propre moteur de calcul, il peut utiliser le moteur d’exécution de votre environnement (sql, Spark, etc.) et sait choisir le moteur de calcul le plus efficient.
- DSS s’occupe de toute la plomberie (connexion entre les différents environnements de travail, déploiement, etc.). Cela permet de se concentrer sur la partie fonctionnelle du projet.
- Gain de temps dans la création et comparaison de modèles.
- Possibilité de créer des mesures et contrôles personnalisés ou utilisation de mesures préconfigurées.
- Déploiement de modèle sur l’API Node ou de projet sur l’Automation Node de manière rapide.
👉 Retrouvez toute notre actu en temps réel en nous suivant sur LinkedIn 👈


![[Data Rider] REX Collecte de données IoT – Étape 1 : Initier la collecte](https://fr.blog.businessdecision.com/wp-content/uploads/2025/05/data-rider-rex-collecte-donnees-1024x512-1.jpg)











Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.