
Data Scientist, THE job le plus sexy du XXIème siècle serait-il en train de perdre de sa superbe ? Après une période de grâce quasi-irréelle, le Data Scientist semble être de plus en plus défié dans l’entreprise. On lui reproche parfois son manque de connaissances métier et d’approche business. On lui reproche souvent son manque de communication et de mise à la portée des utilisateurs. Sans compter l’IT qui lui tombe régulièrement dessus car les modèles qu’il conçoit ne passent pas à l’échelle et ne sont pas industrialisables (nom de code MLOps).
Par ailleurs, il semble pris en étau entre deux autres fonctions data montantes. D’un côté, le Data Analyst, qui boosté à l’AutoML, vient concurrencer les Data Scientists sur le terrain des modèles les plus simples. Et d’un autre côté, le ML Engineer, qui vient le concurrencer sur l’industrialisation des modèles d’IA à l’échelle.
Alors, dans ce contexte, quel est l’avenir du métier de Data Scientist ? Est-il condamné à aller toujours plus loin dans son expertise en se spécialisant sur des applications de plus en plus complexes et pointues ? Est-il condamné à disparaître sur l’autel des fonctions tech étoiles filantes ?
Ce que l’on verra dans cet article :
- Data Scientist : Job le plus sexy ou job le moins bien défini du XXIème siècle ?
- La Data Science est un sport d’équipe
- Le Machine Learning Engineer est-il la nouvelle licorne des profils data ?
- Mais alors quel est l’avenir du métier de Data Scientist ?
Data Scientist : Job le plus sexy ou job le moins bien défini du XXIème siècle ?

Matinée Microsoft AI Apps
Data Scientist : et si c’était l’histoire d’un grand malentendu ? Le genre de malentendu qui fait tellement le buzz, qui fait tellement monter la chantilly, qui alimente tellement d’attentes dans l’entreprise qu’il en est à la fin totalement décevant. Car en data comme en cuisine, quand les attentes sont trop fortes, on a de fortes chances d’être déçu à l’arrivée.
Et en la matière, pour le Data Scientist, les attentes étaient tout simplement irréalistes. Le climax du buzz a été atteint lorsqu’en 2012 la prestigieuse revue HBR a publié un article au titre évocateur « Data Scientist, le job le plus sexy du XXIème siècle » et enfoncé le clou avec le sous-titre « Découvrez les personnes qui peuvent extraire des trésors à partir de données désordonnées et non structurées »… Rien que ça !
On demandait alors quatre champs de compétences au Data Scientist : maîtrise des mathématiques appliquées, savoir-faire en programmation et bases de données, connaissance du business et capacité à communiquer et à échanger avec les métiers. En résumé, une sorte de super-héros omniscient capable de développer des usages qui s’apparentent à de la magie.

Crédit : Marketing Distillery
Si le buzz a explosé dans les années 2010, ce métier ne date pourtant pas d’hier et tient d’une longue lignée. En effet, la discipline est née au XVIIIème siècle (avec les premières tables de mortalité utilisées par les assurances vie). Au cours du XXème siècle, la fonction a connu plusieurs dénominations telles que celles de statisticien, d’analyste statistique, d’analyste des données, de data miner voire de fouilleur de données… Et c’est donc dans les années 2010 que surgit le terme de Data Scientist.
Il accompagne l’explosion du big data, l’envol de l’apprentissage machine (Machine Learning) et l’avènement de l’apprentissage profond (Deep Learning). Et c’est ainsi que s’engouffrant dans la brèche, de nombreux professionnels de la data ont repeint leur profil LinkedIn avec un nouveau rôle de Data Scientist en l’espace de quelques mois. Au point que ce titre soit aujourd’hui le plus répandu des métiers de la data selon l’enquête « Le futur des métiers de la data vu par les grands groupes français » réalisée par Kantar Public pour la Mission Numérique Gouvernementale des Grands Groupes et rendue publique en juin 2021.
Mais d’ailleurs, quelle est l’origine du terme « Data Scientist » ? D.J. Patil, le co-auteur du fameux article HBR qui a tout déclenché a expliqué que le département RH de LinkedIn (qui était alors son employeur) souhaitait faire de l’ordre dans les très nombreuses fonctions qui comprenait le mot « data » sur le fameux réseau social professionnel. L’idée du terme Data Scientist s’est alors imposée lors d’une discussion avec un de ses amis qui travaillait chez Facebook. Il ne cherchait donc pas à définir une nouvelle profession mais bien à trouver un terme pour regrouper différents métiers.
Alors, vous voyez qu’on est réellement parti d’un grand malentendu ! Un mix d’emballement techno-médiatique et d’un grand regroupement de fonctions différentes. Finalement, cette phrase de « job le plus sexy du XXIème siècle » a certainement fait plus de mal que de bien à la profession. Notons pour l’histoire que cela n’a pas empêché notre ami D.J. Patil de connaître une brillante carrière, qui l’a menée jusque dans les couloirs de la Maison Blanche, où il a officié en tant que « U.S. Chief Data Scientist »… la grande classe !
La Data Science est un sport d’équipe
Au risque de décevoir, le Data Scientist n’est donc pas la personne providentielle qu’on croyait. Elle ne peut simplement pas l’être tant la tâche est importante, les technologies variées et les usages métiers ambitieux. En parallèle à cette prise de conscience, les sujets de la data et de l’IA gagnent en maturité dans les entreprises, ce qui entraîne une organisation et une distribution des fonctions et rôles beaucoup plus rationnelle. On comprend enfin qu’il ne faut pas tout attendre du Data Scientist mais qu’il faut plutôt monter une « Data Science Team ».
La Data Science Dream Team est ainsi à assembler avec de multiples profils qui interviennent à toutes les étapes des projets de Data Science et de développement des produits d’IA.
On peut notamment citer :
- le Data Engineer pour développer le pipeline de données,
- le Data Scientist pour créer les algorithmes,
- le Machine Learning Engineer pour industrialiser les solutions d’IA.
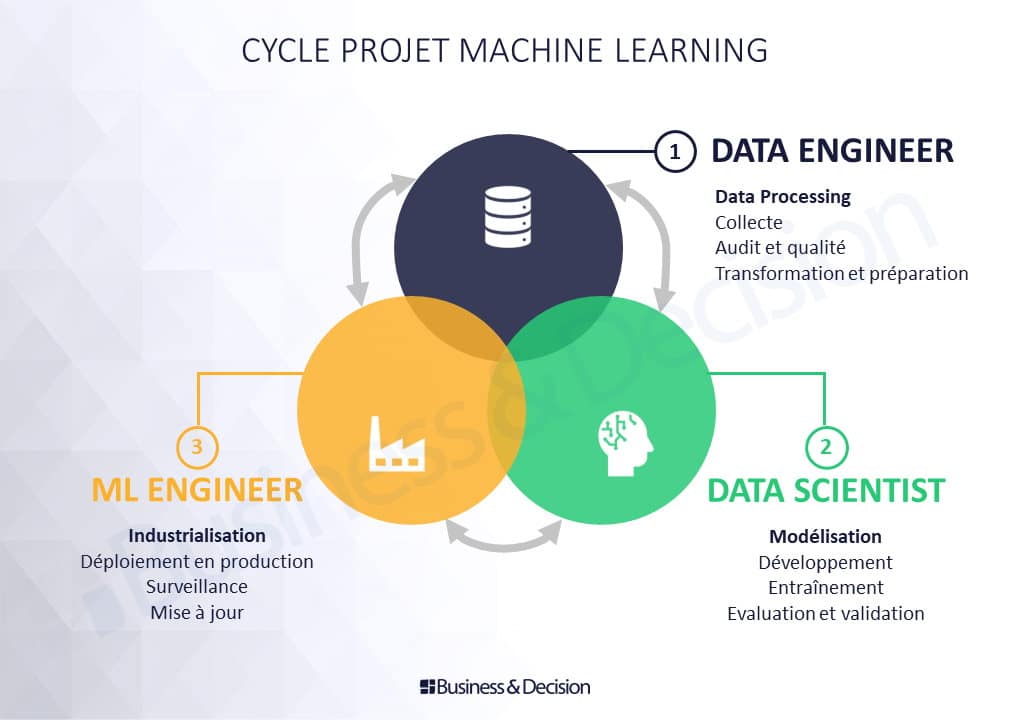
Crédit : Business & Decision
Bien sûr, dans la réalité d’un projet, le rôle de ces métiers n’est pas aussi clairement établi et bien découpé que dans le schéma « Cycle Projet Machine Learning » ci-dessus. Il n’est ainsi pas rare de constater que le Data Scientist participe fortement à l’ensemble des activités ou que le ML Engineer participe à la phase de validation de l’algorithme par exemple.
Il faut aussi citer le rôle des fonctions non spécifiques à la data mais tout aussi indispensables aux projets que sont celles des experts métier qui définissent les besoins, des Ops qui gèrent l’infrastructure et la production ainsi que des chefs de projet et Product Owners qui orchestrent les travaux. Arrêtons-là le compteur : je viens de vous citer sept fonctions… et je ne suis même pas exhaustif tant la diversité des intervenants sur les projets data et IA est devenue importante.
Pour un développement efficace, les produits se construisent avec des organisations en « squads », sortes d’équipes hyper autonomes concentrées sur un objectif commun qui réunissent toutes les fonctions nécessaires au développement rapide d’un cas d’usage.
Dopées aux méthodes agiles, ces squads regroupent souvent un expert métier, un Data Engineer, un Data Scientist et un Machine Learning Engineer, tous concentrés sur l’objectif de délivrer rapidement un cas d’usage à l’échelle. Avec une telle armada de compétences, les projets sont développés rapidement, de façon itérative et sont directement industrialisables.
Le Machine Learning Engineer est-il la nouvelle licorne des profils data ?
Voilà plusieurs fois que je cite ce très récent métier de la data qu’est le Machine Learning Engineer. Appelé ML Engineer par les intimes ou MLE par les pressés, c’est la fonction qui monte qui monte qui monte dans l’entreprise Data-centric… au risque de bientôt décevoir autant que le Data Scientist.
S’il est autant en vue, c’est que ce rôle répond avant tout à une nécessité suprême : celle de l’industrialisation et du passage à l’échelle des algorithmes d’IA. Car le constat est amer. Malgré la valeur qu’ils délivrent, très peu de projets de Machine Learning parviennent à aller au-delà du statut de POC/POV (Proof Of Concept / Proof Of Value) pour atteindre la production. Le coupable est tout trouvé : c’est la faute des Data Scientists (bien sûr !), qui sont accusés de concevoir des modèles incapables de passer l’épreuve du feu du passage à l’échelle. Leurs algorithmes semblent ainsi fonctionner parfaitement en Lab mais ne pas être taillés pour les conditions réelles de la production.
ML Engineer : la nouvelle fonction pour relever le défi du MLOps
Pour répondre à ce défi, l’entreprise s’invente un nouveau super-héros : le ML Engineer ! Ce dernier a pour rôle d’opérationnaliser les algorithmes, de permettre leur passage en production, de mettre en œuvre la boucle retour (aussi appelée feedback loop qui permet un apprentissage de l’algorithme en continu) et d’instaurer l’observabilité des IA en production pour s’assurer qu’elles délivrent le bon comportement et le bon niveau de performance sur les nouveaux cas rencontrés.
A nouveau poste, nouvelles pratiques. Avec le ML Engineer, c’est l’avènement du MLOps. Décliné du mouvement DevOps, le MLOps marque une nouvelle approche méthodologique basée sur l’agilité et le rapprochement de toutes les compétences nécessaires au projet en s’intéressant très tôt à l’opérationnalisation des développements pour la production.
Avec lui, vient toute une nouvelle armada technologique pour le CI/CD (Intégration et déploiement en continu), la gestion des versions et des configurations, la gestion des jeux de données, la conteneurisation des développements, l’exposition par API, l’observabilité des algorithmes en production, etc. Tout cela dans un contexte où les plateformes data et IA se construisent de plus en plus fréquemment dans le cloud.
Replay
MLOps, DataOps : brisez le plafond de verre de l’IA à l’échelle de l’entreprise
Lire la suiteDe fait, Data Scientist et ML Engineer sont en réalité tout à fait complémentaires. Ils forment avec le Data Engineer le trio infernal à assembler pour le développement technique des projets d’IA. Parmi ces trois professions, c’est d’ailleurs le profil qui est le moins dans la lumière, le Data Engineer, qui va devoir assurer la plus grosse partie des tâches.
Il n’y a pas de recette unique, mais de ma vision, les proportions idéales d’une équipe Data Science sont les suivantes en rythme de croisière : 3 Data Engineers et 0,5 ML Engineers pour 1 Data Scientist. Par exemple, si votre équipe compte 10 Data Scientists, prévoyez une trentaine de Data Engineers et 5 ML Engineers pour équilibrer les rôles et délivrer efficacement les projets.
Ces proportions générales peuvent bien sûr fortement varier selon la nature de vos projets ainsi que selon l’importance et la complexité des modèles à réaliser.
Mais alors quel est l’avenir du métier de Data Scientist ?
Voilà donc la situation… notre pauvre Data Scientist se retrouve finalement à porter toute la misère du monde de l’IA et a être accablé de tous les maux de l’entreprise qui se rêve Data-centric. Pourtant on le voit bien, ses épaules étaient bien chargées. Et les critiques qui lui sont adressées sont en réalité le résultat d’un cocktail mêlant un manque cruel de maturité du marché avec un niveau d’attente irraisonné tant sur les possibilités de l’IA que sur les compétences du Data Scientist.
Le Data Scientist doit se centrer pleinement sur son statut de scientifique de la donnée
Mick Levy
Tout le domaine de la donnée a fortement évolué et va continuer d’évoluer rapidement dans les années à venir. Si le Data Scientist doit trouver sa place dans un fonctionnement en équipe, son rôle va rester essentiel. En effet, il doit pleinement se centrer sur son statut de scientifique de la donnée. C’est littéralement le sens de sa fonction et il faut la replacer au cœur de son action. Ainsi, parmi les multiples intervenants sur les projets d’IA, il est bel et bien le seul à disposer d’un bagage mathématique aussi poussé. Grâce à cela, le codage des algorithmes complexes et l’élaboration des modèles vont rester sa chasse gardée.
Ces mêmes compétences scientifiques lui confèrent une expertise unique pour déployer une méthodologie rigoureuse et les bons outils pour prévenir les biais, déjouer les pièges algorithmiques ou encore contourner les problèmes de qualité des données.
La Data Science va encore gagner en maturité
Par ailleurs, la discipline va encore étendre son champ d’action tout en gagnant en maturité. On peut donc imaginer que la Data Science va elle-même proposer des voies de spécialisation. C’est ainsi que les approches de traitement des données structurées, du texte (NLP pour Natural Langage Processing) ou de l’image (computer vision) sont très différentes.
Certains Data Scientists ont d’ailleurs déjà fait le choix de se spécialiser sur l’un ou l’autre de ces domaines en revisitant leur titre au passage. De nouveaux métiers dérivés de celui de Data Scientist vont donc émerger en entraînant certainement une opposition entre ceux qui revendiqueront une spécialisation et ceux qui resteront partisans d’une pratique « généraliste » de la data science.
Ma fille, quand tu seras grande, tu seras Data Scientiste

Vous l’aurez compris, le Data Scientist a un avenir radieux devant lui. Le métier va continuer à gagner en maturité pour travailler plus que jamais en équipe, voire en écosystème. De multiples voies de spécialisations sont possibles alors que dans le même temps les champs d’application de la data science vont s’étendre à tous les secteurs et à toutes les fonctions de l’entreprise.
Au final, tout ce remue-ménage des fonctions de la data et de l’IA est un excellent signal. C’est la preuve que tout l’écosystème des données progresse et que la data science trouve de plus en plus de débouchés. La collaboration entre les différents intervenants est plus que jamais de mise pour réaliser des projets ambitieux et le Data Scientist va continuer à jouer un rôle incontournable pour la mise en œuvre de modèles dans les projets de Machine Learning et d’IA. Alors oui, ma fille, si tu le désires, je t’encouragerai à aller vers la fonction de Data Scientist.e… et mon fils aussi bien sûr ! Il y aura certainement de la place pour tout le monde dans ce métier d’avenir.
👉 Retrouvez toute notre actu en temps réel en nous suivant sur LinkedIn 👈














Commentaires (3)
Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.
De plus les matières à étudier pour ML Ops et les pipeline de données sont quasi les mêmes. ML Engineer ne serait donc qu’une autre appellation pour la fonction Data Engineer, avec la méthode ML Ops en plus …
A méditer !
Cette orthographe est-elle de la provoc' ou une incompréhension du terme anglais ?
C'est dommage car le contenu de l'article est par ailleurs fort intéressant.
Vous avez raison, nous sommes peut-être allés un peu loin ;) Nous venons de modifier le titre en conséquence.
Merci pour votre retour sur l'article :)