
Dans mon précédent article, nous nous sommes demandé quelles étaient les compétences idéales pour bien démarrer en Data Science. Aux jeunes qui veulent se lancer dans la Data Science, j’avais alors recommandé de commencer par une fonction de Data Engineering plutôt que Data Scientist directement. Aujourd’hui, je vous propose de voir quels sont les apprentissages et les formations à privilégier pour devenir Data Engineer.

Data Engineer : quelles formations privilégier ?
Le Data Engineer maîtrise parfaitement les écosystèmes Big Data comme Spark ou Hadoop et bien entendu leur programmation. Le Data Engineer va ainsi tout particulièrement assurer les rôles suivants :
- Rendre opérationnelle l’infrastructure Big Data
- Assurer l’ingestion et l’exposition des données dans ou depuis l’infrastructure
- Assurer la préparation et le recodage 1er niveau des données
- Programmer, automatiser et optimiser les algorithmes sur l’infrastructure cible
« Un Data Engineer est d’abord un informaticien »

Salon de la Data et de l’IA
Un Data Engineer est d’abord un informaticien. Les formations universitaires et d’écoles d’ingénieurs classiques en informatique, en Big Data et bien entendu en Data Engineering, sont donc bien adaptées à cette fonction.
Elles doivent si possible inclure une formation la plus poussée possible en langage Python et en langage Scala. Il ne faut pas oublier non plus la maitrise poussée du SQL et de ses « variantes » modernes NoSQL comme Hive, Impala ou Spark SQL.
Les enseignements techniques (nous ne parlons pas ici des « soft skills », lesquels feront l’objet d’un article ultérieur) devront s’organiser autour de plusieurs grands axes qui seront a minima le Big Data, le Cloud, les méthodes DevOps, et bien entendu l’Intelligence Artificielle.
Concernant le Big Data, les incontournables sont bien entendu Spark et Hadoop. Hadoop englobe tout l’écosystème dit « Zookeeper », et inclut des technologies comme Hive, Nifi, Oozie et Kafka. Bon nombre de ces technologies étant basées sur Java, c’est une bonne idée d’avoir de bonnes bases en Java pour mieux maitriser cet environnement, mais il n’est pas nécessaire d’être un développeur Java JEE pour devenir Data Engineer (et encore moins pour devenir Data Scientist).
Spark devient incontournable
En revanche, Spark est totalement incontournable. On peut l’aborder de deux manières, soit via Python par l’intermédiaire de PySpark, soit par l’intermédiaire du langage Scala. Les deux voies sont possibles, mais bien évidemment l’idéal est d’avoir les deux cordes à son arc.
Concernant l’aspect Cloud, et les éditeurs privés ne manquant pas, il faut faire des choix. L’important est de bien maîtriser les infrastructures Spark et Hadoop dans le (ou les) cloud(s) cible(s) que l’on choisit d’étudier. En effet, chaque cloud possède ses spécificités techniques, et en particulier des API pour l’intelligence Artificielle qui sont mises à disposition par l’éditeur et qu’il est préférable de bien connaître.
Mener un projet d’IA
Ceci nous amène naturellement vers l’Intelligence Artificielle (IA). Dans ce domaine, Python règne bien sûr en maître. Mais attention, au-delà de Python, il est nécessaire de maîtriser un certain nombre de librairies Python pour pouvoir mener à bien un projet complet. On peut citer seulement les librairies les plus importantes comme Numpy, Pandas, Mathplotlib, Scikit-learn, Mllib, etc. Il faut également maîtriser les gestionnaires de codes et les notebooks comme Git, GitHub, GitLab, Jupyter, Zeppelin, etc.
Réaliser un projet d’IA 100 % en Python est toujours possible, mais aucun client (interne ou externe) ne voudra vous l’acheter car il coûtera trop cher et sera trop difficile à maintenir.
Il faut donc également être capable de gérer les plateformes spécialisées en Intelligence artificielle du marché. Il y en a beaucoup et l’objet de cet article n’est pas d’en faire une liste exhaustive ni de vous en faire un comparatif. Je vous renvoie à cet effet par exemple sur les benchmarks 2019 du Gartner – Magic Quadrant concernant les plateformes de Data Science et de Machine Learning.
Formation technique et conduite de projet
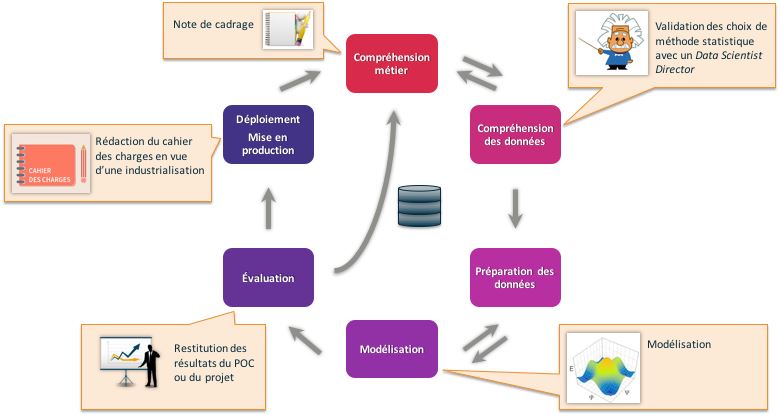
Au-delà des formations techniques dont je vous ai donné un bref aperçu plus haut. Il faut ajouter des formations sur les méthodes de conduite de projet. On citera notamment les méthodes DevOps et la méthode CRISP incontournable. La méthode Scrum doit aussi être comprise mais attention aux « mauvais mélanges » entre méthodes, en Data Science par exemple CRISP doit absolument être prioritaire sur Scrum. Pour supporter DevOps, les technologies docker et kubernetes présentent un intérêt certain.
C’est pourquoi, Business & Decision lance l’Ecole de la Data qui formera environ 40 Data Engineers en 2019 en deux promotions. Ces formations seront étoffées dès l’année prochaine en rajoutant notamment la fonction de Data Scientist.
L’idée sous-jacente de ce projet est de s’assurer que les jeunes talents qui nous rejoignent soient pleinement opérationnels après avoir suivi l’Ecole de la Data de Business & Decision. Le cursus dure trois mois, et est complémentaire de ce qui est vu en école d’ingénieurs et en université.













Commentaire (1)
Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.