
Dans l’article Il était une fois le SQL sous Hadoop, je décrivais le foisonnement de solutions existantes pour travailler en SQL en environnement Big Data Hadoop. Plus d’un an s’est écoulé. L’occasion pour moi de vous dresser un premier bilan et d’établir les tops et les flops.
Les Tops
Impala
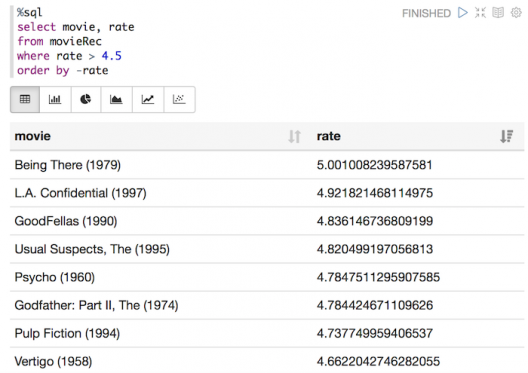
Ne tournons pas autour du pot : le vrai Top du SQL sous Hadoop, c’est Impala. J’ai eu l’occasion de le tester grandeur nature pour l’un de nos clients. L’objectif était de sortir un tableau de bord très complexe présentant des indicateurs agrégés s’appuyant sur un historique de données de plus d’un an.
Sans rentrer dans les détails, il n’a jamais été possible de produire ce tableau de bord via des technologies décisionnelles classiques. Autant vous dire que notre client a été plus qu’impressionné quand on a pu lui sortir ce tableau, et encore plus quand on lui a dit que cela avait pris seulement 3 minutes !
Impala dispose de ses propres daemons : il ne passe pas par Map Reduce, ce qui permet ainsi d’accélérer les traitements. Par ailleurs, Cloudera propose de configurer son cluster Hadoop en réservant des ressources à Impala. Avec cette approche, pas besoin de créer des clusters spécialisés suivant la nature des traitements. Le cluster conservera un très bon niveau de performance pour les requêtes interactives Impala tout en faisant tourner en parallèle des traitements lourds Map Reduce.
Est-ce que demain toutes les requêtes BI tourneront sur un cluster Hadoop avec comme moteur Impala ? Pour ma part, je ne m’y risquerais pas encore. Nous manquons encore de recul notamment sur la gestion d’un grand nombre d’utilisateurs concurrents. Mais cette frontière entre BI et Big Data va devenir de plus en plus ténue dans les prochains mois.

Je préfère privilégier aujourd’hui encore des systèmes hybrides en conservant les systèmes BI sur leurs fondamentaux en limitant l’historique de données (et en limitant les coûts associés), et en laissant à Hadoop le soin de traiter les requêtes complexes sur des historiques profonds. Cela renforce aussi l’idée d’utiliser le datalake comme ODS des futurs systèmes décisionnels puisque ce datalake servira de point central pour alimenter la BI traditionnelle et la BI sous Hadoop.
Hive
Et oui Hive 🙂
Même si Hive reste en retrait en termes de performance, il n’en reste pas moins un outil incontournable dans de nombreuses situations.
J’ai pu le tester sur un projet réglementaire consistant à analyser des logs d’accès web. Associé à Flume pour l’intégration des logs (jusqu’à 100 000 lignes /min), Hive traite les logs et offre un accès en temps réel sur les résultats. Et si on a besoin de plus de performance, on a toujours la possibilité de générer des tables d’agrégat.
Les traitements hive ont une empreinte moins forte sur le cluster. Selon les besoins projets, cela permettra de paralléliser davantage de traitements.
L’autre intérêt de Hive est d’offrir une interface d’accès pratique à tous les outils externes. D’où l’idée de profiter de Hive pour faire du Spark. La fonctionnalité s’appelle Hive on Spark : l’idée est de remplacer le moteur Map Reduce par Spark dans les traitements Hive. Nous l’avons testé en mode expérimentale avec un certain intérêt. Cloudera vient d’officialiser sa sortie dans la dernière version 5.7.
Les flops
Drill
Que s’est-il passé pendant un an sur Drill ? Pour le savoir, j’ai été contraint d’aller faire un tour sur le site de mapR. J’ai trouvé une très belle infographie sur le développement de l’outil :

Cliquez sur l’image
Car sur le terrain, je n’ai pas eu l’occasion de le tester. Drill est victime de l’isolement de mapR sur le marché des distributions en France. Les clients préfèrent privilégier les leaders du marché Cloudera et Hortonworks, ou les éditeurs traditionnels comme Oracle (via Big Data Appliance) et IBM (BigInsights).
Tez
Tez, c’était le pari de l’extrême compatibilité avec Hive face à la rupture initiée par Impala. Tez est en train de perdre son pari. Le gain de performance par rapport à Hive est important mais bien en deça de ce que propose Impala. Plus grave, les performances ne semblent pas suffisantes pour envisager à terme un accès en mode interactif aux utilisateurs.
Il me semble qu’Hortonworks va devoir revoir sa copie sur ce point.
Et Spark ?
Il y a un an, j’avais dit tout le bien de Spark et de sa déclinaison Spark SQL. Qu’en est-il aujourd’hui ?
A dire vrai, les performances de Spark et Impala ne sont pas très éloignées. Les deux outils travaillent en mémoire. Mais la philosophie des deux solutions est selon moi très différente.
Impala a vocation à servir des utilisateurs finaux au travers de requêtes exécutés directement dans Hue ou via une solution de BI traditionnelle. Comme nous l’avons vu, Impala est généralement paramétré avec des ressources dédiées afin d’assurer aux utilisateurs de bonnes performances.
Spark de son côté est plutôt destiné aux data ingénieurs ou aux data scientists. Ces utilisateurs particuliers peuvent certes lancer des requêtes interactives mais aussi des traitements plus lourds. Yarn gère de manière intelligente l’allocation des ressources entre des traitements concurrents de type Map Reduce et Spark. Cela garantit ainsi que des traitements de type batch (map reduce) continueront de tourner malgré une activité soutenue sur Spark (et inversement).
Dans ce contexte, Spark SQL est un moyen simple d’accéder aux données. Il prend tout son sens avec un outil comme Zeppelin qui va permettre au sein d’un notebook d’écrire du code pour traiter les données mais aussi de visualiser les résultats.
J’en profite pour dire que Zeppelin fera sûrement l’objet d’un article dédié très prochainement.
Hortonworks n’a peut-être pas dit son dernier mot…
Difficile de tirer des conclusions définitives. Si Cloudera avec Impala a trouvé son positionnement, Hortonworks n’a peut-être pas dit son dernier mot.
N’oublions pas non plus les éditeurs traditionnels (IBM, Oracle, Teradata, Microsoft) qui misent tous sur la fédération de requêtes à savoir la capacité d’interroger hadoop et une base de données de manière transparente.
Si vous avez de votre côté des retours d’expérience intéressants sur ces technologies SQL sous Hadoop, n’hésitez pas à les partager avec nous sur ce blog.
👉 Retrouvez toute notre actu en temps réel en nous suivant sur LinkedIn 👈














Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.