
Snowflake, la plateforme d’hébergement de données dans le cloud est reconnue pour sa puissance, sa flexibilité et sa sécurité. Elle offre un large éventail de services pour stocker, analyser, partager des données, et permet désormais aux développeurs de coder directement en Python depuis son interface. On fait le point…
Snowflake s’appuie sur les principaux fournisseurs de services cloud tels que Amazon Web Services (AWS), Microsoft Azure et Google Cloud Platform (GCP), ce qui permet aux utilisateurs d’exploiter facilement des données provenant de ces différentes sources sans avoir à se soucier des problèmes de compatibilité ou de transfert de données.
Qu’il s’agisse de données structurées, semi-structurées ou non structurées, Snowflake offre une solution de stockage fiable. Son architecture permet de manipuler efficacement d’énormes volumes de données avec des performances élevées.
La flexibilité est également un de ces atouts majeurs, car l’outil permet aux utilisateurs d’ajuster rapidement leurs ressources de calcul et de stockage pour s’adapter à des charges de travail changeantes. De plus, l’éditeur propose une tarification basée sur la consommation, offrant aux utilisateurs la possibilité de ne payer que pour ce qu’ils utilisent réellement.
Snowflake accorde aussi une importance primordiale à la protection des données. La plateforme propose des fonctionnalités de sécurité avancées telles que le chiffrement des données de bout en bout, la gestion des accès basée sur les rôles et la conformité aux normes de sécurité les plus strictes.
Snowflake va même au-delà du simple stockage de données et s’efforce d’élargir ses fonctionnalités pour offrir une plateforme complète répondant aux besoins divers de ses utilisateurs. En développant une gamme étendue de services, Snowflake aspire à devenir la plateforme de choix pour les entreprises cherchant à exploiter pleinement le potentiel de leurs données.
Coder en Python depuis l’interface de Snowflake
Parmi ces fonctionnalités se trouve l’intégration de Python, un puissant langage de programmation répandu notamment dans le domaine de la data science. Cette synergie entre Python et Snowflake ouvre la porte à de nouvelles opportunités, offrant aux développeurs la possibilité de coder directement en Python depuis l’interface de Snowflake, permettant ainsi d’effectuer toutes les tâches, du stockage des données au développement, sur une seule et même plateforme.
Nous allons explorer cette nouvelle fonctionnalité, et voir en détail les possibilités qu’elle offre aux développeurs pour manipuler et analyser les données directement sur la plateforme Snowflake.
La synergie entre Python et Snowflake ouvre la porte à de nouvelles opportunités en offrant aux développeurs la possibilité de coder directement en Python depuis l’interface de Snowflake.
Snowpark pour l’exécution de code Python
Snowpark est l’environnement de développement intégré à Snowflake, qui fournit un cadre permettant l’exécution de code Python au sein de la plateforme. En d’autres termes, Snowpark est le nom du framework qui englobe tous les outils et services nécessaires pour utiliser Python avec Snowflake.
Initialement, Python n’est pas le seul langage de programmation intégré dans Snowpark. A l’origine, SQL fut le premier langage disponible pour traiter les données stockées sur Snowflake. Actuellement, d’autres langages comme Java sont aussi supportés par la plateforme.
Pour revenir à Python, Snowpark intègre la plupart des packages populaires de Python, ce qui signifie qu’il n’est pas nécessaire de les installer individuellement pour les utiliser. Contrairement à un environnement de développement classique, ces packages sont immédiatement disponibles à l’utilisation sur Snowpark, notamment des packages liés à la data science comme Pandas ou encore Scikit-Learn.
La construction d’UDF (User-Defined Functions) est possible avec Snowpark. Ce sont des fonctions Python qui peuvent par la suite être appelées dans des requêtes SQL.
Enfin, parmi les outils de Snowpark, il existe également un connecteur Python qui permet aux utilisateurs de travailler avec du code Python depuis leur propre environnement de développement local tout en étant connectés aux données stockées dans Snowflake, et en sauvegardant de nouvelles données directement sur cette plateforme si nécessaire.
Pour utiliser cette fonctionnalité, il suffit d’installer une extension Snowflake sur son IDE (environnement de développement intégré) et de se connecter avec ses identifiants. Cette option peut être particulièrement pratique pour ceux qui préfèrent travailler avec leur environnement de développement habituel. En revanche, elle soulève des questions quant à la sécurité des données qui ne seront alors plus sous la protection unique de Snowflake.
Utiliser les Worksheets pour faire le lien entre Snowflake et Python
Les worksheets de Snowflake, sont comme leur nom l’indique des feuilles de travail. En faisant le lien avec Python, un worksheet Python est le fichier qui permet d’exécuter le code, autrement dit c’est un script contenant du code Python. C’est à partir de l’interface de Snowflake qu’un worksheet peut être ouvert et c’est là que commence le travail du développeur Python.
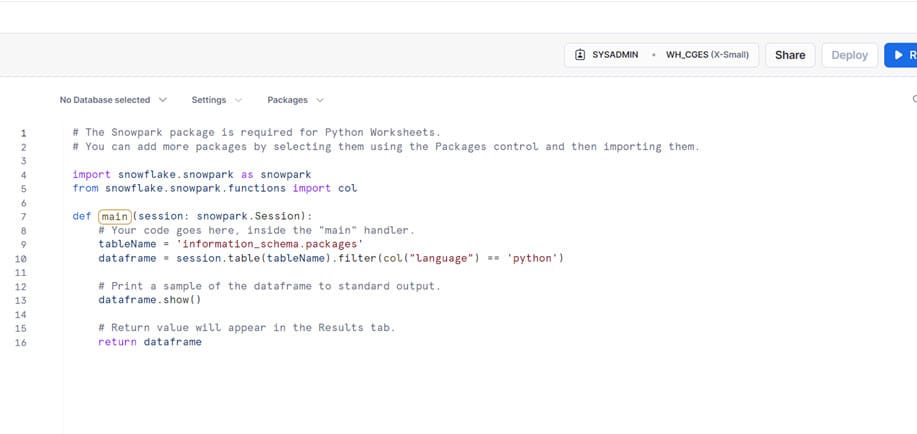
Pour exécuter un worksheet Python, il est nécessaire de sélectionner préalablement une base de données stockée sur Snowflake et de faire appel aux données de cette base dans une fonction principale Handler grâce à une session. Seule cette fonction est appelée lors de l’exécution du worksheet et est capable de retourner des résultats dans la console, comme une table par exemple.
C’est aussi dans un worksheet que l’on peut voir tous les packages disponibles et ceux que l’on souhaite sélectionner pour les utiliser.
Le bouton « deploy » permet également de déployer son code python en UDF, comme mentionné précédemment. Une fois en UDF, le code est prêt à l’emploi dans un worksheet SQL.
Enfin, un élément important entre en jeu pour l’exécution d’un worksheet : le choix du warehouse. Un warehouse va permettre l’exécution des opérations sur les données stockées, et il peut être configuré avec différentes puissances en fonction des besoins allant de XS à 6XL et avec une option supplémentaire « snowpark-optimized » pour les lourdes opérations à réaliser.
Utiliser Python dans un contexte de Snowpark : attention, défi !
Python est un langage très populaire avec une grande communauté active permettant de bénéficier d’une abondance de documentation et de forums d’entraide. Cette richesse de ressources facilite grandement le processus de développement de code, et offre aux programmeurs un support pour résoudre rapidement les problèmes et apprendre à utiliser de nouvelles fonctions.
Bien que Python soit un langage très populaire, son utilisation dans le contexte de Snowpark, le framework de développement de Snowflake, présente certaines particularités. En effet, Snowpark introduit des API et des fonctionnalités spécifiques à Snowflake, qui ne sont pas toujours bien documentées ou familières aux développeurs Python. La documentation et les ressources pour Snowpark sont actuellement moins riches et étendues, amenant les utilisateurs débutants à explorer, expérimenter par eux-mêmes, ce qui peut rendre le démarrage un peu fastidieux. Néanmoins, la communauté Snowflake est en croissance constante et les ressources s’améliorent progressivement, et permet de plus en plus de soutien aux développeurs qui souhaitent tirer parti de la puissance de Snowpark avec Python.
Replay
Optimiser, gérer et contrôler ses coûts avec la Plateforme Data Cloud Snowflake
Lire la suiteExpérimentation avec un cas d’usage
Pour explorer les possibilités qu’offre Snowflake dans le domaine de la data science, un scénario a été expérimenté. Son objectif : prédire le chiffre d’affaires d’une entreprise en se basant sur de nombreuses factures de produits vendus, stockées au format PDF sur Snowflake.
Parmi les challenges à relever en utilisant du code Python via Snowflake, la première étape consiste à transformer ces données non structurées en données structurées. Contrairement aux données structurées, les données non structurées telles que les PDF ne peuvent pas être directement stockées sous forme de table. Elles sont stockées dans un emplacement spécial de Snowflake appelé « stage ».
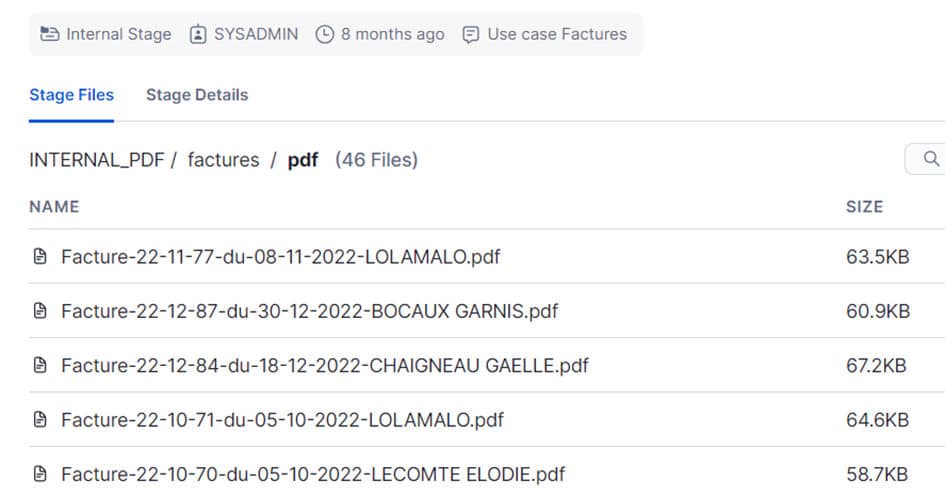
Pour chaque document stocké dans le stage, une URL est attribuée. C’est à partir de cette URL qu’il est possible d’accéder au document. Comme mentionné précédemment, une connexion aux données doit être établie dans la fonction principale du worksheet Python. Pour notre cas d’usage, cette connexion n’est pas établie avec une table mais avec les PDF en utilisant une fonction sécurisée spéciale qui accède à chaque PDF grâce à son URL. Une fois que chaque PDF est accessible depuis le worksheet, l’une des nombreuses bibliothèques Python peut être utilisée pour extraire du texte d’un PDF et stocker automatiquement les données pertinentes dans une table.
Une fois la table stockée sur Snowflake, il est possible d’exploiter les données. Une fois de plus, pour accéder aux données, il faut établir une connexion entre le worksheet et la table. Pour exploiter cette table, 2 possibilités s’offrent à l’utilisateur : manipuler les données sous forme d’objet dataframe classique tel que Pandas, ou utiliser les « spark dataframe » proposés par Snowflake.
Chacun de ces types de dataframes présente des avantages et des inconvénients : le choix est à faire en fonction des préférences de l’utilisateur. Les Spark DataFrames utilisent les capacités de parallélisme de Snowpark, ce qui les rendent plus rapides à la manipulation de données. Néanmoins, ils manquent de ressources documentaires contrairement à Pandas, largement répandu dans la communauté des data scientistes.
Ensuite, si l’on souhaite visualiser graphiquement ces données, les packages spécialisés de Python comme Matplotlib ne sont pas pris en charge en sortie dans la console. La visualisation graphique des données n’est faisable que dans son environnement de développement local. Toutefois, il reste possible d’obtenir des graphiques sans code Python grâce à la fonctionnalité Dashboard de Snowflake, en utilisant du code SQL. Par exemple, pour ce cas d’utilisation, le top 10 des meilleurs produits en termes de chiffre d’affaires peut être affiché à partir d’une requête générant un graphique.
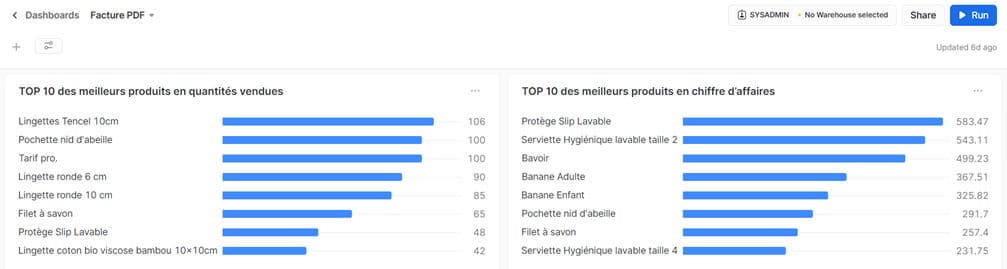
Pour revenir à l’objectif principal du cas d’usage, la prédiction du chiffre d’affaires a été effectuée en fonction du mois de l’année en utilisant la bibliothèque scikit-learn de Python, largement reconnue par la communauté des data scientistes pour sa vaste gamme d’algorithmes de Machine Learning. Cette bibliothèque est disponible et utilisable sur Snowflake sans contrainte particulière. Une fois la connexion établie avec les données de la table, la construction du modèle est réalisable.
Il convient de noter que pour ce cas d’utilisation, la puissance de calcul requise n’était pas significative, une puissance modeste était amplement suffisante. Cependant, dès lors que la quantité de données devient importante, il est recommandé de passer à une taille de wharehouse supérieure afin de réduire le temps d’exécution.
Enfin, concernant le déploiement et la gestion du modèle, Snowflake n’est pas encore pleinement équipé pour offrir une efficacité optimale aux utilisateurs. L’API Snowpark Model Registry est en cours de déploiement et ouvre de nouvelles perspectives prometteuses pour la réalisation de projets de data science de bout en bout.
Un outil prometteur pour gérer la data de bout en bout
En conclusion, Snowflake représente un outil prometteur, en adoptant une approche axée sur l’innovation, et cherche à répondre aux besoins changeants de ses utilisateurs grâce à l’introduction de fonctionnalités avancées pour gérer la data de bout en bout.
Cependant, à l’heure actuelle, de nombreuses options ne sont pas accessibles à tous, étant en phase de « private preview » ou encore en cours de développement. Lorsque toutes les fonctionnalités liées à la data science seront disponibles, l’outil gagnera en reconnaissance parmi les autres outils de ce domaine.
Pour l’instant, des lacunes persistent, notamment en termes de documentation et d’assistance pour des tâches spécifiques telles que le MLOPS par exemple. De plus, l’environnement de développement en ligne sur Snowflake n’est pas encore entièrement adapté à une programmation efficace, ce qui rend préférable l’utilisation de son propre environnement local connecté aux données sur le cloud de Snowflake, mais qui peut alors compromettre la sécurité des données.
Ces défis sont des opportunités d’amélioration pour Snowflake afin de répondre pleinement aux besoins complexes de la communauté des data scientists. A suivre… 😉


![[Data Rider] REX Collecte de données IoT – Étape 1 : Initier la collecte](https://fr.blog.businessdecision.com/wp-content/uploads/2025/05/data-rider-rex-collecte-donnees-1024x512-1.jpg)











Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.