
Spark est un framework open source de calcul distribué. Plus performant qu’hadoop, disponible avec trois langages principaux (Scala, Java, Python), il s’est rapidement taillé une place de choix au sein des projets Big Data pour le traitement massif de données aussi bien en batch qu’en streaming.
Depuis la version 2.0, Spark propose une nouvelle approche pour le streaming : Structured Streaming. Je vous propose de la découvrir ensemble ce qu’est Spark Streaming et comment cela fonctionne dans une série de 3 articles. Les deux premiers ont porté sur la gestion des données et maintenance des traitements, et sur la transformation des données aux tests unitaires ». Dans ce troisième et dernier article, nous allons aborder les tests de performance.
Comment tester les performances
Quand on pense « Tests de performance », on pense cluster de production.
Mais doit-on absolument tout tester sur un cluster de production ?
Le déploiement d’un programme Spark sur un cluster prend du temps et les contraintes en production sont souvent importantes. D’où l’idée d’estimer la performance de son traitement sur son environnement de développement local et de déployer son code en production uniquement pour des tests de validation, une fois que le code est déjà bien optimisé.
L’environnement de développement doit permettre d’estimer (dans la plupart des cas) les capacités de notre code relativement aux capacités de notre machine.
Mon environnement de développement sous Docker
Mes tests ont été réalisés sur nos dernières générations de machine : Windows HP G7 (8 cores logiques, 16 Go RAM).
Point important: disposer d’une version récente de Windows permettant de faire tourner Docker sous WSL2.
Comme on le voit, c’est une belle machine mais elle n’a néanmoins rien d’exceptionnelle aujourd’hui.
Pour simuler un environnement réel, on a besoin de Spark mais aussi des autres composants :
- kafka pour l’alimentation des données
- spark pour le calcul des indicateurs
- postgresql pour le stockage des indicateurs
Pour monitorer mon environnement, j’ai également rajouté :
- prometheus pour la récupération des métriques JMX des composants java (Spark, Kafka)
- grafana pour visualiser les métriques dans un beau dashboard
Tout cela est configuré dans un fichier yaml afin de générer des containers Docker via docker-compose.
Spark
Examinons maintenant la configuration du container spark.
spark-master:
image: swal4u/spark-master:v2.3.0.3
hostname: spark-master
container_name: spark-master
environment:
- TZ=Europe/Paris
command: ["/etc/master.sh", "-d","6G","3"]
ports:
- "4040:4040"
- "8080:8080"
- "8081:8081"
- "7072:7072"
volumes:
- ./conf/metrics.properties:/usr/local/spark/conf/metrics.properties
- .:/appOn utilise ici un cluster avec 3 cores et 6 Go de RAM.
On voit également que l’on modifie un fichier pour remonter les métriques JMX.
Voilà les principales modifications effectuées dans metrics.properties.
# Enable JmxSink for all instances by class name
*.sink.jmx.class=org.apache.spark.metrics.sink.JmxSink
# Enable JvmSource for instance master, worker, driver and executor
master.source.jvm.class=org.apache.spark.metrics.source.JvmSource
worker.source.jvm.class=org.apache.spark.metrics.source.JvmSource
driver.source.jvm.class=org.apache.spark.metrics.source.JvmSource
executor.source.jvm.class=org.apache.spark.metrics.source.JvmSourceOn ouvre également le port 7072 qui sera utilisé par prometheus pour récupérer les métriques.
Kafka
kafka:
image: confluentinc/cp-kafka:5.5.0
deploy:
resources:
limits:
cpus: '0.50'
memory: 512M
hostname: kafka
container_name: kafka
depends_on:
- zookeeper
ports:
- "29092:29092"
- "7071:7071"
volumes:
- ./kafka/prom-jmx-agent-config.yml:/usr/app/prom-jmx-agent-config.yml
- ./kafka/jmx_prometheus_javaagent-0.6.jar:/usr/app/jmx_prometheus_javaagent.jar
environment:
KAFKA_BROKER_ID: 1
KAFKA_ZOOKEEPER_CONNECT: 'zookeeper:2181'
KAFKA_LISTENER_SECURITY_PROTOCOL_MAP: PLAINTEXT:PLAINTEXT,PLAINTEXT_HOST:PLAINTEXT
KAFKA_ADVERTISED_LISTENERS: PLAINTEXT://kafka:9092,PLAINTEXT_HOST://localhost:29092
KAFKA_OFFSETS_TOPIC_REPLICATION_FACTOR: 1
KAFKA_GROUP_INITIAL_REBALANCE_DELAY_MS: 0
KAFKA_OPTS: -javaagent:/usr/app/jmx_prometheus_javaagent.jar=7071:/usr/app/prom-jmx-agent-config.ymlIci, c’est un peu différent. On copie un jar et un fichier de configuration via l’instruction de volume et on lance Kafka en rajoutant une option avec ces deux éléments.
On utilise ici le port 7071 pour transmettre les métriques JMX.
Pour aller plus loin, je vous invite à consulter deux articles intéressants sur le sujet Metrique Fire – Kafka monitoring using Kafka ou Cloud walker – Monitoring Kafka avec Prometheus.
Avec quelles données ?
Tester son code avec des données est toujours compliqué !
Pour le streaming, le challenge est encore plus élevé, en particulier lorsque l’on veut travailler sur l’aspect performance.
Pour que le test soit représentatif, il faut être capable de générer des données proches du réel, anonymisées, en mode flux. L’utilisation de données de production n’est pas pertinente car on ne maîtrise pas la volumétrie transmise.
Mise en place d’un générateur de données
Spark propose une source « rate » pour sa fonction readstream, permettant de générer des entiers consécutifs à une certaine fréquence. En s’appuyant sur cette fonction, on peut facilement générer des données aléatoires et même régler la vitesse de génération des dates pour avoir quelque chose de cohérent.
spark
.readStream
.format("rate")
.option("rowsPerSecond", numPerSecond)
.option("rampUpTime", 10)
.load()
.withColumn("msg", concat(
lit(test.part(1)),
lit("request_id"), col("value"),
lit("node"), col("value") % 8,
lit(test.part(3)),
(col("value"))/lit(numPerSecond),
lit(test.part(5)),
...Ce bout de code génère des parties fixes de notre string final via la méthode part qui récupère le début, le milieu et la fin de notre chaîne de caractères.
Au milieu, on a variabilisé certains éléments via l »utilisation de « value » générée par la source rate et l’usage de la fonction modulo (ex: %8).
A noter que nous utilisons (col(« value »))/lit(numPerSecond) comme timestamp.
Si nous réglons numPerSecond à 2000, cela signifie que le code génère 20000 lignes en 10s et que notre timestamp vaudra 20000/2000 soit 10s. On simule ainsi des données avec un horodatage cohérent.
Monitoring applicatif
Comme nous l’avons vu, la solution consiste à collecter sous Prometheus des métriques JMX disponibles nativement sur la plupart des composants Java et de les monitorer au travers d’un dashboard Grafana.
- Le paramétrage des métriques se fait via des fichiers de configuration.
- L’activation des métriques se fait lors du lancement des traitements.
Dashboard Grafana sous CDN
Voilà le résultat que l’on peut obtenir.
Si besoin, cliquer sur l’image pour l’agrandir.
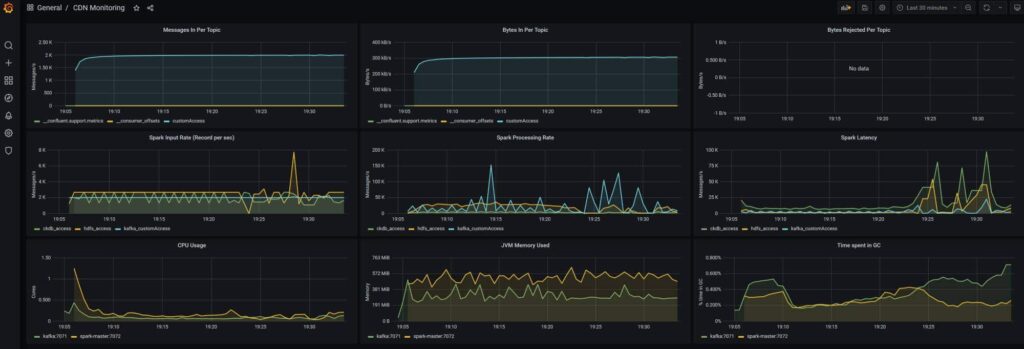
Gestion de la mémoire
Sous Spark, quand on rencontre des problèmes de performance, la solution de facilité consiste à augmenter les ressources du traitement.
C’est une approche court terme qui peut coûter cher car vous devrez à terme augmenter les ressources de votre cluster.
Les mauvaises performances peuvent avoir différentes sources :
- batch : mauvaise répartition des données sur le cluster
- streaming : kafka + garbage collector
Spark crée par défaut une tâche map de récupération des données par partition kafka.
- Si vous avez seulement 2 partitions Kafka, vous devriez utiliser 2 executors.
- Si vous avez beaucoup de données, vous pouvez augmenter les ressources par executor.
- Si vous avez trop de données, vous devez partionner davantage les données sur Kafka et adapter le nombre d’executors.
Garbage collector
Lors de nos tests, nous avons détecté un problème spécifique (allongement des durées des micro-batch au bout de x minutes). Après pas mal de recherches, nous avons identifié un souci au niveau du Garbage Collector.
Si besoin, cliquer sur l’image pour l’agrandir.
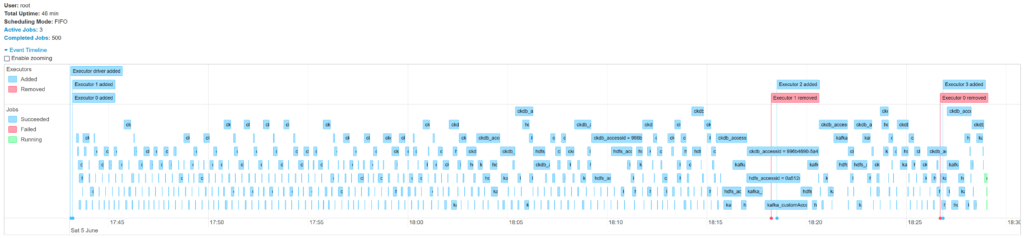
Paramétrage G1GC
G1GC est un garbage collector récent optimisé pour différents types de workload. Il n’est pas activé par défaut sur nos versions Java 8. (Garbage Collector par défaut à partir de Java 9)
G1GC propose de nombreuses options pour optimiser son fonctionnement. Il est nécessaire au préalable d’activer les logs afin de pouvoir analyser les résultats. Tout se passe au niveau du spark-submit.
--conf "spark.executor.extraJavaOptions=-XX:+UseG1GC -XX:+PrintFlagsFinal -XX:+PrintReferenceGC
-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy
-XX:+UnlockDiagnosticVMOptions -XX:+G1SummarizeConcMark" \Garbage Collector CMS
Un autre garbage collector mis en avant est le GC CMS (ConcMarkSweepGC).
Contrairement au G1GC, il est particulièrement adapté aux traitements de streaming car il nettoie la mémoire au fil de l’eau.
Les résultats de CMS ont été intéressants mais malgré tout un peu moins bon qu’avec G1GC. (latences plus importantes).
Optimisation G1GC
La première approche a consisté à optimiser l’usage de la mémoire.
--conf "spark.memory.storageFraction=0" // Pas besoin de memoire cache
--conf "spark.memory.fraction=0.8" // Réservation de 80% de la mémoire pour les besoins d'execution
--conf "spark.executor.extraJavaOptions=-XX:InitiatingHeapOccupancyPercent=35 // Déclencher le GC plus tôt
-XX:+DisableExplicitGC // Bonne pratique
-XX:+UseStringDeduplication // Bonne pratiqueOn retrouve ici de nombreux paramètres génériques à mettre en œuvre sur beaucoup de workloads.
Résultats obtenus
Résultats après 120 mn
Si besoin, cliquer sur l’image pour l’agrandir.
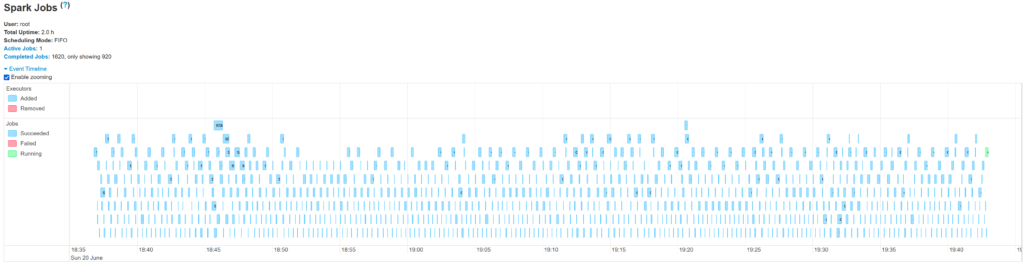
Caractéristiques: cluster local 2 cores 6 Go RAM
Données: 8000 msg/s
Monitoring après 120 mn
Si besoin, cliquer sur l’image pour l’agrandir.
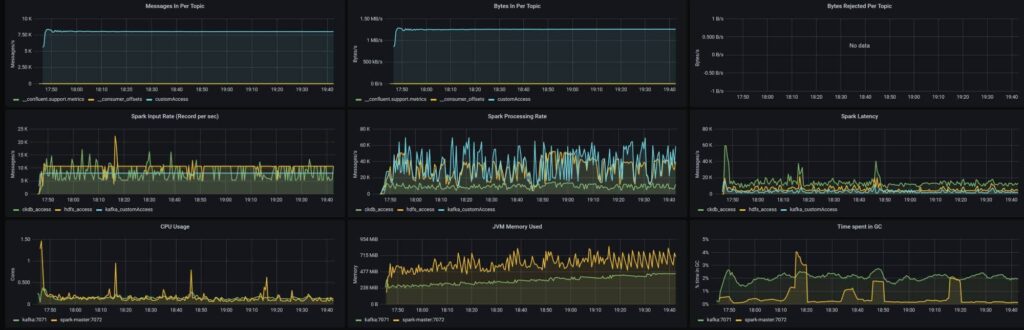
One more thing
Plutôt confiant avant de lancer les tests de performance sur le cluster de production, nous avons été très surpris de constater de nouveau des problèmes de stabilité dans notre traitement.
La faute venait du paramétrage par défaut des clusters Cloudera…
Allocation dynamique
Un cluster Yarn permet de faire de l’allocation dynamique d’executors. Cela signifie que le cluster évalue l’utilisation des executors et peut décider de rajouter ou de supprimer des executors suivant les besoins.
L’évaluation est basée sur le temps d’inactivité des executors et le nombre de tâches en attente.
Ce fonctionnement peut être problématique avec des traitements en streaming.
Cela peut se traduire par des executors qui sont supprimés puis recréés, mais avec un temps de mise en œuvre qui génère de la latence.
Pour désactiver ce fonctionnement par défaut sur un cluster Cloudera :
--conf "spark.dynamicAllocation.enabled=false"Voilà, nous arrivons ainsi à la fin de cette série sur Spark Structured Streaming. J’espère que ces 3 articles vous aurons éclairé sur ce sujet et vous dis à bientôt pour un nouvel article sur le Big Data.
👉 Retrouvez toute notre actu en temps réel en nous suivant sur LinkedIn 👈








![[Data Rider] Booster Mario Kart à l'IoT et à l'IA – Étape 3 : écoconduite et consommation électrique](https://fr.blog.businessdecision.com/wp-content/uploads/2024/08/data-rider-ecoconduite-1024x512-1.jpg)





Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.