
Dans ce nouvel article dédié à la question du monitoring technique et opérationnel d’une plateforme Big Data Hadoop, sous Horton Works (HDP) ou Cloudera (CDH), et désormais avec Cloudera Data Platform (CDP) ou des alternatives sous Kubernetes, nous allons entrer dans le détail des différentes étapes du processus de la supervision opérationnelle. Cette seconde partie est la suite d’un premier opus consacré aux bases pour mettre en place un monitoring opérationnel que je vous invite à lire également si ce n’est pas encore fait.
Supervision opérationnelle : 5 étapes distinctes
Nous avons découpé notre processus en 5 étapes distinctes. Je vais vous présenter chaque étape dans une section dédiée. Le schéma ci-dessous synthétise visuellement ce qui va être détaillé dans l’article.
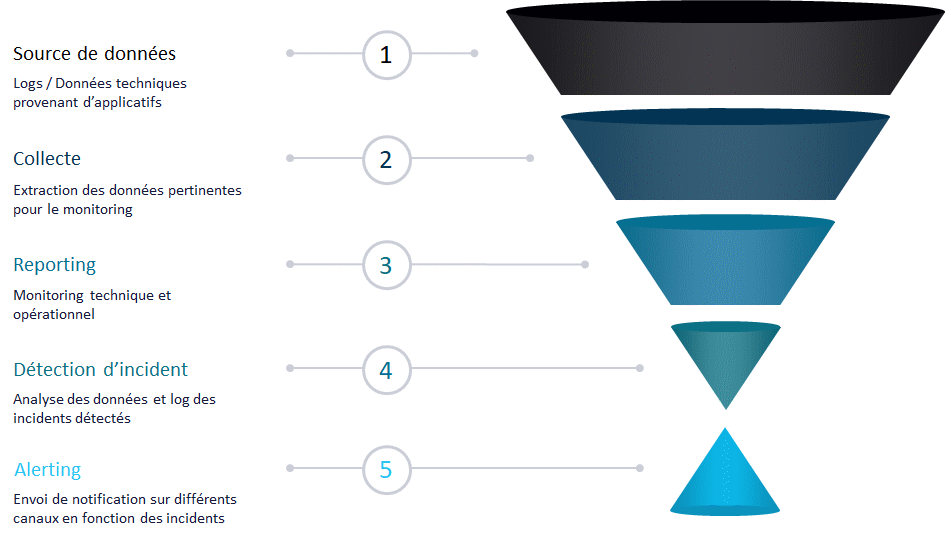
Comme en BI classique, nous avons une masse d’information en entrée qu’il faudra identifier, puis collecter. Ensuite, nous allons raffiner ces données pour en extraire de l’information, la restituer et l’exploiter pour déterminer de nouvelles données. Pour finir, nous allons diffuser l’information pertinente sur différents canaux et vers différents acteurs.
Étape 1 : Recenser les sources de données
Il est nécessaire de recenser les différentes sources de données disponibles sur votre plateforme, mais aussi de les prioriser. Collecter tout ce qui existe prend du temps et des ressources, il est donc préférable d’y aller petit à petit selon les besoins identifiés.
Ainsi, il est nécessaire de recenser les différentes sources (applications, traitements, etc.), les données associées disponibles (logs, JMX, API, base de données, fichiers, etc.), et également la pertinence et la complexité de la collecte. Vous pourrez ensuite prioriser facilement la collecte de vos sources de données pour le monitoring. Un projet de supervision rentre pleinement dans une démarche agile.
La partie identification des sources n’étant pas spécifique, nous allons passer directement à l’étape de collecte où l’environnement Big Data (et sa multitude de technologies) aura plus de sens.
Étape 2 : Collecter les données
Pour collecter les données, plusieurs possibilités s’offrent à vous selon le type (logs, JMX, API, base de données, fichiers, etc.). Nous allons creuser plus en détails ces différents types. Auparavant, faisons un focus sur le stockage de notre collecte de données.
Le stockage
En effet, il est nécessaire de centraliser nos données de monitoring dans un seul endroit (2 endroits maximum). Pour faciliter le monitoring, il est important d’éviter d’éparpiller les données. L’étape de collecte vise justement à stocker à un endroit toutes ces données pertinentes.
En revanche, le monitoring n’a pas vocation à stocker un volume très important de données. Une base de données relationnelles, comme PostgreSQL, fera parfaitement l’affaire. Toutes les technologies de collecte pourront facilement y déverser leurs données. Cette base est le point de convergence du monitoring. On y stockera également les alertes générées. Dans cette base, je vous conseille de créer une database dédiée au monitoring, puis des tables pour chaque source de collecte.
On peut éventuellement stocker les données dans 2 outils distincts si on récupère des métriques JMX (expliquées plus bas). Dans ce cas, une base comme Prometheus sera conseillée.
Logs
Si vous avez déjà la suite ELK (Elasticsearch, Logstash et Kibana) sur votre plateforme, vous pouvez vous servir de Logstash pour parser (ou parcourir) vos logs et extraire l’information pertinente pour votre monitoring.
Sinon, vous pouvez utiliser n’importe quel langage de scripting pour parser et extraire les informations des logs. Dans notre dernier projet, nous avons utilisé du Shell, mais nous aurions pu utiliser du Python.
Il est nécessaire de bien analyser la structure de vos fichiers de logs pour en extraire uniquement les informations pertinentes. Ce travail peut être plus ou moins compliqué selon les logs générés. Une fois la donnée extraite, vous pourrez l’écrire facilement dans votre de base de données.
Vous pouvez bien évidemment utiliser Spark pour parser vos logs mais attention aux ressources additionnelles sur votre cluster. Si du scripting est suffisant, il vaut mieux le privilégier.
Dans notre cas, nous avons parsé les logs d’Airflow v1 en Shell. Depuis que nous sommes passés sur Airflow v2, nous utilisons désormais l’API.
JMX (Java Management eXtensions)
Il s’agit d’un standard Java définissant des classes et une architecture à respecter pour faire du monitoring. Grâce à l’architecture JMX, il est possible de contrôler les ressources utilisant une JVM (Java Virtual Machine). Ainsi, de nombreux programmes ont été développés en Java (ou Scala) et mettent donc à disposition des métriques JMX (Kafka, YARN, Oozie, Spark, etc.).
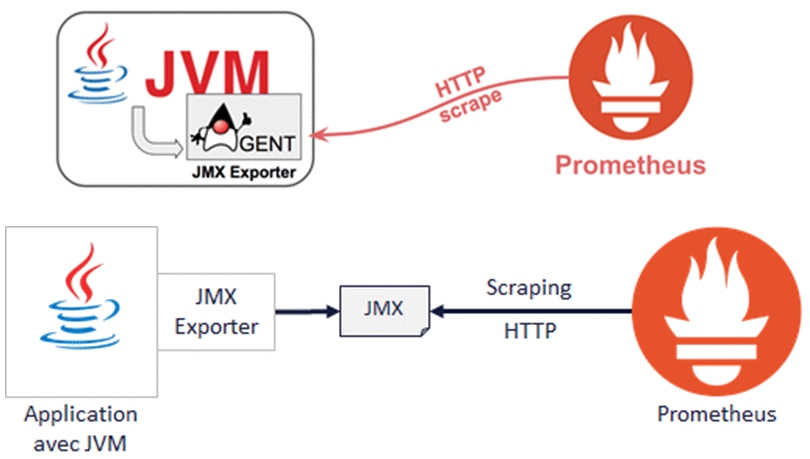
Si vous avez du JMX, je recommande l’installation d’une base Prometheus qui est parfaitement adaptée au stockage et à la collecte de ces données. Dans ce cas, vous aurez effectivement 2 bases de données pour votre monitoring.
La bonne nouvelle, c’est que la solution de reporting que je vais proposer ensuite sait très bien lire dans Prometheus et dans n’importe quelle base SQL. Ainsi, vous pourrez avoir des dashboards qui vont lire dans ces 2 bases de données. C’est totalement transparent pour l’utilisateur.
Pour le développeur, il y aura quelques impacts puisque ce ne sera pas du SQL pour requêter dans Prometheus mais du PromQL. Pas d’inquiétude, les bases du PromQL s’apprennent rapidement.
Sur notre projet, nous récupérons les métriques JMX venant de Spark, Kafka et Yarn. Nous pouvons ainsi surveiller la santé de nos traitements Spark, détecter une variation anormale de débit sur Kafka, ou encore une queue YARN avec un usage à 100% trop long.
API & Bases de données
Comme pour les logs, vous pouvez utiliser un langage de scripting pour interroger l’API ou requêter dans une base de données.
Attention à ne pas interroger trop souvent ces systèmes pour ne pas les mettre en risque de bon fonctionnement. Par exemple, pour récupérer le statut de santé d’un service, faire un appel API toutes les secondes n’a pas de sens. Un appel toutes les 5 à 15 minutes est généralement suffisant.
Sur notre projet, nous réalisons des appels API pour suivre l’ordonnancement Airflow (durée d’exécution et tâches en erreur), et pour vérifier la présence de données récentes dans ELK, mais également pour suivre l’état d’ELK (santé du cluster et temps de réponse des requêtes).
Fichiers
Il est possible de devoir traiter des fichiers sur HDFS (Parquet, ORC, etc.) pour extraire de l’information. Dans ce cas, vous pouvez réaliser un traitement Spark qui viendra relire ces fichiers, en extraire ce qui est important pour vous et enregistrer le résultat dans votre BDD de collecte.
Attention toutefois à la volumétrie collectée. Il peut être pertinent de collecter une agrégation des données du fichier et non chaque ligne unitairement. HDFS est prévu pour stocker une volumétrie très importante, mais pas votre BDD relationnelle. On reste sur de la supervision, donc à un niveau moins fin de la donnée.
Si vous voulez simplement suivre la date ou la taille des fichiers générés sur HDFS, du scripting sera suffisant.
Pour gérer les rejets de notre application, nous allons les écrire en CSV sur HDFS. Notre traitement de collecte va simplement prendre le timestamp et le nombre de ligne des fichiers générés. Nous savons ainsi visualiser sur une timeline les rejets générés.
Traitements Spark
Pour certains indicateurs, il peut être nécessaire de retraiter un topic Kafka, ou des fichiers (PARQUET, ORC, …) non manipulable en Shell. Dans ce cas, Spark peut être la solution à votre besoin. Soit en surchargeant votre traitement existant si vous n’avez pas de contrainte forte de performance. Soit en réalisant un traitement annexe dédié au monitoring et qui fonctionnera de façon asynchrone avec votre traitement principal.
Attention à limiter les jobs Spark qui vont consommer des ressources supplémentaires sur votre cluster, et à les affecter à une queue YARN dédiée.
Dans notre projet, nous lisons le topic Kafka en fin de chaîne pour analyser la qualité des données, et pour calculer le MTTS (Mean Time To Service), c’est-à-dire le temps moyen de mise à disposition des données. On calcule ainsi la différence entre le timestamp du message dans Kafka et le timestamp du log. Nous obtenons ainsi le temps de traitement de chaque ligne de données. On garde ensuite le MTTS moyen par tranche de 5 minutes, et le 95ième percentile. C’est-à-dire le temps maximum de mise à disposition pour 95% des logs (pour exclure les quelques cas extrêmes).
Distinguer l’étape de collecte et de détection d’incident
Il est primordial de bien collecter la donnée dans la base de données avant de générer une alerte, et non de générer l’alerte au moment de la collecte. Cette organisation permet plus de flexibilité ultérieure pour les incidents et l’alerting. Voyons un exemple de cas rencontrés où nous avons voulu prendre un raccourci à tort.
Alerting sur champ obligatoire
Pour contrôler la qualité des données, nous devions analyser chaque ligne de données et vérifier sur quelques champs obligatoires qu’ils sont bien renseignés. Côté métier, il y avait l’assurance que ces champs étaient toujours valorisés sauf rare exception.
Nous sommes partis sur la logique 1 ligne en erreur = 1 incident (car rare).
Au lieu de collecter la ligne en erreur, puis de générer l’alerte, nous avons simplifié le processus en générant directement l’alerte.
Résultat : les erreurs sont effectivement rares, mais lorsque cela arrive, ce sont parfois des centaines de lignes en erreur, engendrant donc une centaines d’alertes.
Bonne pratique: il faut donc collecter les lignes en erreur dans une table dédiée, puis créer un seul incident qui indique le nombre de lignes en erreur. Le monitoring doit ensuite permettre de voir le détail des lignes en erreur.
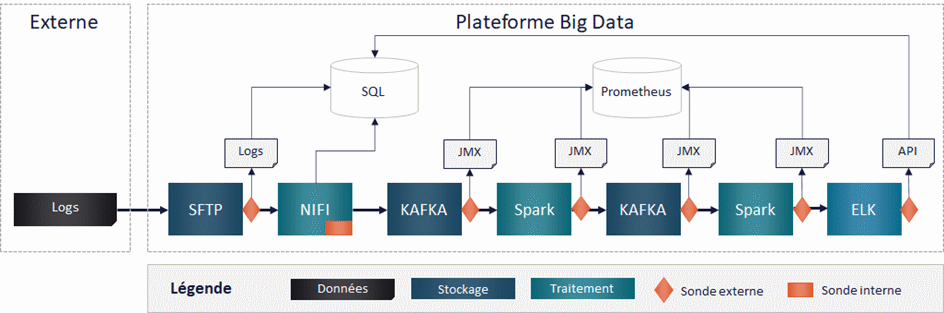
Illustration
Pour faire le lien avec notre exemple, présenté dans le premier article, voici les types de données collectées et les bases de données associées.
Étape 3 : Un reporting pour restituer visuellement les données
Cette étape permet de restituer visuellement les données précédemment collectées. Le reporting donne un sens à la donnée collectée.
Il est fortement conseillé de choisir un outil de reporting unique afin de centraliser dans un seul endroit tous les dashboards de supervision. En effet, sur une plateforme Hadoop on a souvent un nombre important de projets. Ils doivent tous suivre la même démarche de supervision et être suivi dans le même outil. On peut ainsi avoir une vue transverse centralisée de toute la plateforme.
Grafana convient tout à fait à ce besoin. En effet, cet outil permet de centraliser notre suivi, mais également de cloisonner les dashboards dans différentes organisations si l’on ne veut pas que tout le monde puisse accéder à tous les reportings. De plus, Grafana est un outil de reporting pensé pour le monitoring. Il se connecte à toutes les bases SQL, mais aussi aux bases TimeSeries comme Prometheus !
Grafana est open source, mais propose si besoin un support (payant). L’outil peut s’installer On Premise ou s’utiliser directement sur le Cloud.
Avec toutes les données collectées, il faut désormais définir les axes et graphiques de restitution les plus pertinents. On peut les regrouper dans des dashboards thématiques pour organiser le monitoring.
Le schéma ci-dessous synthétise notre vision de l’organisation des dashboards.
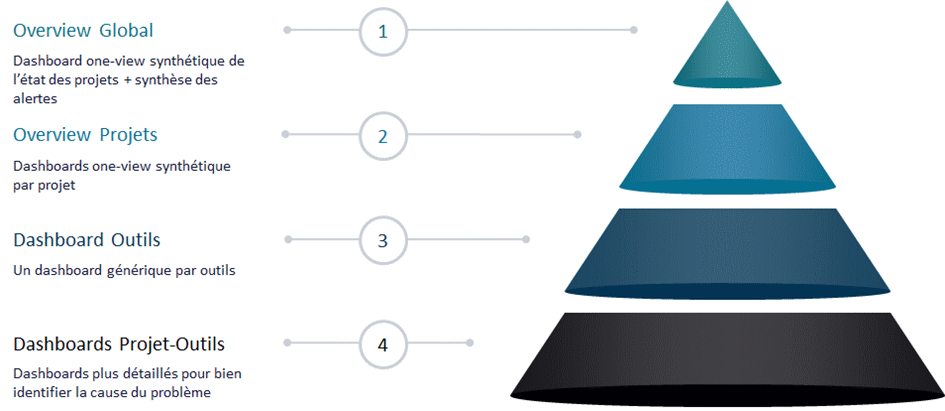
Les dashboards créés dans le reporting doivent permettre d’expliquer les incidents survenus sur la plateforme et d’aider à leur résolution rapide. Il est donc pertinent de faire le lien entre un incident et son dashboard explicatif. C’est d’ailleurs généralement l’analyse du reporting qui permet de définir la règle de détection d’un incident.
Étape 4 : Détecter les incidents
La détection d’incident est l’étape qui ajoute de l’intelligence à toute cette masse de données. A partir de toutes les informations collectées, on vient les combiner et en extraire une nouvelle information plus opérationnelle.
En suivant le reporting créé et lors d’incidents ou anomalies constatés, il faut déterminer quelles informations techniques vont nous permettre de détecter le problème. Dans l’idéal, il faut aussi étudier les données avant l’incident pour essayer de le détecter avant même qu’il arrive. Plus on détectera tôt l’incident, plus on pourra être pro-actif pour limiter l’interruption de service ou on pourra mettre résoudre les problèmes sous-jacents avant un incident plus critique de la plateforme.
Attention tout de même à bien régler les seuils des incidents pour ne pas créer non plus d’incidents à tort. Trop d’incidents à tort va avoir tendance à noyer les vrais incidents et à rendre leur traitement moins efficace. A l’inverse, il est indispensable de détecter un vrai incident.
Le conseil : prioriser les incidents
Afin de prioriser les incidents, on peut leur adjoindre un niveau de criticité (MINEUR, MAJEUR, CRITIQUE). Nous verrons par la suite qu’il y a la détection d’un incident, mais aussi l’alerting associé. La distinction des deux est importante pour démultiplier les possibilités.
Ainsi, détecter un incident, c’est surtout mettre un sens sur un ensemble de données. C’est prendre de la hauteur sur ce qu’il se passe sur la plateforme et le synthétiser dans une ligne de données à un instant T. Il est d’ailleurs possible de créer des super incidents. Ce sont des incidents de plus haut niveau qui permettent de synthétiser l’état de la plateforme et d’informer de manière plus macro des utilisateurs métiers.
Par exemple, dans mes incidents de bas niveau, je détecte quand un Job Spark est en FAILED pour chacun de mes traitements. A chaque plantage, le traitement génère donc un incident MINEUR que je ne vais pas alerter. Je définis un super incident qui m’indique dès que plus de 2 traitements sont en erreurs actuellement sur la plateforme. Ce super incident a une date de début et une date de fin. Je ne serais donc alerté que deux fois : à la détection du problème et à sa résolution (au lieu d’être alerté pour chaque plantage).
Étape 5 : Alerting pour définir les canaux d’alerte
L’alerting est une étape cruciale du monitoring car elle permet de ne pas avoir à rester les yeux river sur les dashboards à longueur de journée. Il est nécessaire de bien identifier qui doit recevoir quelle alerte et sur quel canal ce sera le plus pertinent.
Généralement, dans les canaux d’alerte, on trouvera le mail. C’est pratique, tout le monde peut le recevoir, le faire suivre. Cependant, attention à l’avalanche d’alertes qui peut noyer votre boîte mail. Si vous avez également des alertes qui sonnent tous les jours, l’utilisateur risque de ne plus y prêter attention. L’alerte email doit donc être privilégier pour les incidents critiques qui arrivent logiquement rarement.
Pour limiter la noyade de l’utilisateur sous les alertes, le plus simple est de faire un seul mail qui regroupe toutes les alertes des 5 dernières minutes, et de les faire ressortir par niveau de criticité et avec des codes couleur.
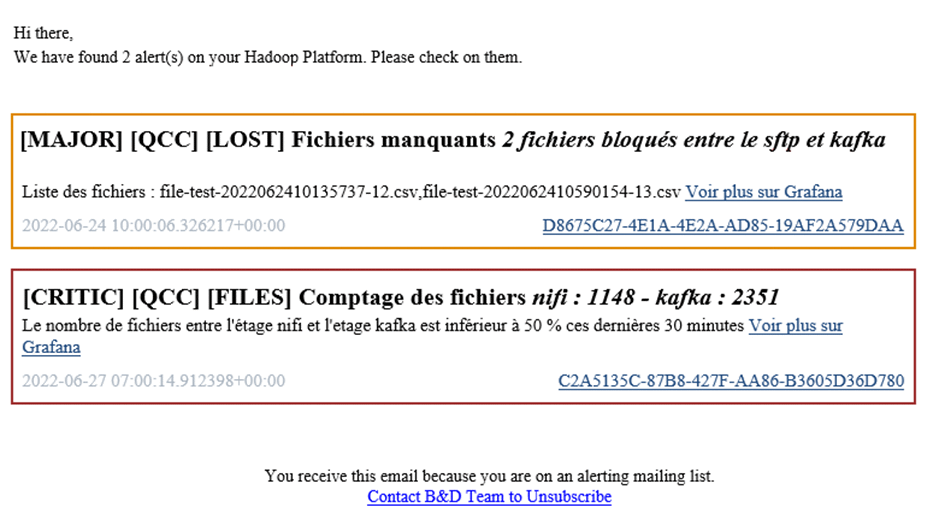
On peut aussi utiliser un service de messagerie instantanée (Mattermost, Teams, …) pour envoyer les alertes. On peut séparer les alertes sur différents canaux selon les destinataires avec un découpage orienté équipe métier ou bien orienté flux fonctionnel (Produits, Ventes, Achats, etc.). Dans une messagerie instantanée, on peut envoyer plus d’alertes.
Le conseil : faire ressortir les alertes par niveau de criticité
Le risque de noyade est toujours présent, mais est restreint dans une zone dédiée. Pour limiter la confusion et ne pas passer à côté des alertes les plus importantes, il faut bien penser à faire ressortir les alertes par niveau de criticité. La messagerie fait également office de sauvegarde et donne la timeline des alertes pour faciliter l’analyse a posteriori de l’incident.

Les alertes peuvent également être poussées dans n’importe quel outil proposant une API. C’est très utile si vous avez un outil groupe qui centralise la supervision de tous vos applicatifs.
Comme indiqué dans la section précédente, on peut aussi gérer des alertes ouvrantes et fermantes. Ainsi, au lieu de recevoir un message à chaque fois que le même incident est détecté, on peut en recevoir une seule au démarrage de l’incident, puis une autre à sa clôture. Votre messagerie sera soulagée, et vous aurez directement l’information de la fin de l’incident. Ce fonctionnement nécessite de créer des incidents de haut niveau (super incident ou master incident) se basant sur des incidents de plus bas niveau. Ainsi, on alertera par email que pour les masters incidents.
Alerter c’est rassurant. Mais que se passe-t-il si l’alerting ne fonctionne plus ? Si le lien entre votre plateforme et votre messagerie est rompu, les incidents peuvent s’enchainer sans que vous soyez au courant. Pour se faire, il est possible de sécuriser en envoyer une alerte « KeepAlive », c’est-à-dire une alerte récurrente toutes les 5 minutes. L’incident est levé si l’alerte n’arrive plus à destination.
Accélérateur pour votre plateforme Hadoop
Ces deux articles vous ont donné les bases pour la mise en place d’une supervision opérationnelle de votre plateforme Big Data.
Chez Business & Decision, nous avons créé une solution générique, facilement réutilisable et adaptable à n’importe quel environnement Hadoop. Nous pouvons donc vous accompagner pour accélérer la mise en place de cette supervision sur votre plateforme Big Data.
👉 Retrouvez toute notre actu en temps réel en nous suivant sur LinkedIn 👈














Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.