
Dans cet article, nous allons aborder la question du monitoring technique et opérationnel d’une plateforme Big Data Hadoop, sous Hortonworks (HDP) ou Cloudera (CDH), et désormais avec Cloudera Data Platform (CDP) ou des alternatives sous Kubernetes. Le sujet étant vaste, nous avons réparti l’effort dans 2 articles. Ce premier article va permettre d’introduire le sujet, le périmètre et les grands principes. Le second article rentrera dans les différentes étapes du processus de la supervision opérationnelle.
L’utilisation d’une stack Hadoop pour le traitement des données
Pour vos projets ayant du Volume (> au Tera de données), ou un besoin de Vélocité (streaming) ou encore de la Variété dans les données une plateforme Hadoop est pertinente.
Cependant, ces plateformes sont complexes car elles utilisent de nombreux outils. La supervision peut vite devenir un cauchemar.
💡 Stack : empilement d’outils ou de données pour Hadoop. Il s’agit de l’écosystème complet de tous les outils qui gravitent autour d’Hadoop pour avoir une plateforme fonctionnelle.
Dans une infrastructure Hadoop, on retrouvera des machines physiques ou virtuelles pour porter les services à faire tourner. Au-dessus, on trouvera bien évidemment les services de la distribution Hadoop installée, mais également d’autres services additionnels nécessaires aux besoins de chaque projet. On peut par exemple utiliser un ordonnanceur différent de celui fournit, avoir une base de données relationnelle ou Timeseries, ou encore ajouter du Kafka.
Ensuite, on va faire tourner nos programmes pour traiter les données (Map Reduce, Spark, Hive, …), mais aussi utiliser les applications de la stack Hadoop et les autres services installés.
Pour terminer, on retrouvera les données en elles-mêmes qui pourront être stockées sur Kafka, HDFS, hBase, etc.
Tutoriel
Spark Structured Streaming : de la gestion des données à la maintenance des traitements
Lire la suiteDans notre rôle d’intégrateur, nous sommes bien évidemment responsables du traitement des données, de l’usage des applications et des données. L’hébergeur de la solution est quant à lui responsable des 2 couches inférieures.

Repérer rapidement les problèmes d’exécution au sein d’une distribution Hadoop
Nativement, dans toute distribution Hadoop, il y a un outil de supervision des services (exemple : Ambari). Malheureusement, cette supervision est très technique et limitée.
Premièrement, elle ne supervise que les services intégrés dans la distribution. Les outils complémentaires en sont donc exclus.
Deuxièmement, cette supervision ne remonte que des erreurs purement liées au service. Si le service est vraiment KO, on le saura. Même si le service est souvent indiqué comme fonctionnel, il arrive que les traitements de données soient indiqués comme comprenant des erreurs.
La difficulté alors est de savoir si ce problème provient du traitement des données ou bien d’un ou plusieurs services applicatifs. En effet, un traitement de données va s’appuyer sur plusieurs services. Chaque service peut fonctionner correctement unitairement, mais les liens entre les services peuvent, eux, ne pas fonctionner.
Une bonne relation entre hébergeur et intégrateur est indispensable pour creuser ensemble la root qui est à l’origine de l’incident et corriger le problème. Autrement, le risque est que chaque partie se renvoie la faute.
Même lorsque l’entente est bonne, l’analyse de l’incident peut être chronophage. Et l’idéal est bien évidemment de repérer le plus rapidement possible un problème sur la plateforme.
Pour maximiser la satisfaction des utilisateurs, il est donc nécessaire de détecter nous-même l’incident avant que l’utilisateur ne s’en rende compte. On peut communiquer ainsi en avance de phase sur le problème et sa prise en compte. Et comme on l’a identifié tôt, la durée de l’incident est fortement réduite.
Pour sécuriser ce genre de plateforme Hadoop, nous avons ainsi créé une solution de supervision opérationnel (à la fois technique et fonctionnel), couplée à une solution d’alerting.
Périmètre de la supervision opérationnelle
Notre solution de monitoring recouvre bien évidemment toute les couches de la responsabilité de l’intégrateur, mais également une partie des services Hadoop et des services additionnels du côté de l’hébergeur. Ainsi, l’analyse est plus aisée en cas d’incident car nous pouvons alors étudier en autonomie sur un périmètre plus large que notre responsabilité.
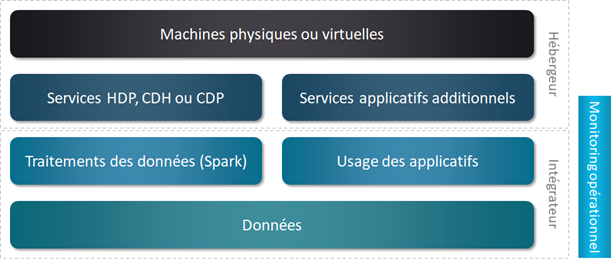
Souvent l’intégrateur a un accès à Ambari ou Cloudera Manager qui lui permet de suivre les services de la distribution Hadoop. C’est donc déjà une première manière de suivre la partie Hébergeur. L’objectif avec notre solution (qui sera détaillée dans le second article dédié à ce sujet) est d’aller plus loin et de pouvoir aussi suivre les services applicatifs additionnels.
Cas d’application
Pour illustrer mes propos dans les 2 articles, nous allons imaginer une chaîne de traitement de données de logs de machines de routage. Les données sont déposées par différentes sources sur un SFTP. L’utilisation de Nifi, logiciel libre de gestion de flux de données, va permettre de traiter ces fichiers et envoyer chaque ligne en message dans un topic Kafka.
Les données vont ensuite être enrichies par des référentiels et des calculs d’indicateurs en temps réel via Spark et remis à disposition d’un nouveau topic Kafka. Ce topic pourra être utilisé par plusieurs prestataires externes, et un second traitement Spark alimentera en Streaming un index Elastic.
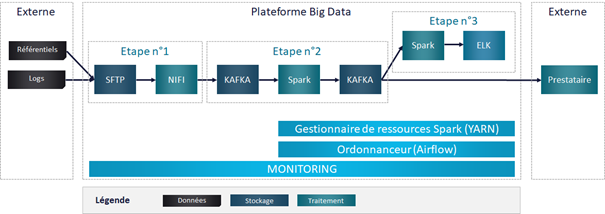
Pour faciliter l’analyse et les références dans cet article, nous avons découpé la chaîne d’alimentation en 3 étapes.
Supervision opérationnelle : les grands principes
Dans cette section, je vais aborder plusieurs notions générales liées à la supervision opérationnelle. Ces notions seront à articuler avec les différentes étapes décrites dans le second article.
Sondes dans la chaîne de traitement
Pour superviser une plateforme, il est nécessaire de collecter de la donnée technique sur le fonctionnement des services, des programmes et des données. Pour ce faire, on va poser des sondes. On peut distinguer 2 types de sondes.
La sonde interne qui consiste à adapter le traitement existant pour faire sortir des données additionnelles nécessaires au monitoring. Le temps du traitement peut augmenter, et on rend dépendant le traitement et son monitoring. Cette solution est à éviter quand cela est possible.
La sonde externe qui consiste à récupérer des données déjà disponibles (logs, métriques JMX, données stockées) pour en extraire l’information nécessaire au monitoring. C’est bien évidemment la solution à privilégier.
Il est nécessaire de placer des sondes aux différentes étapes de la chaîne de traitement pour rapidement identifier la source du problème. Il est également possible de combiner plusieurs sondes pour une même étape.
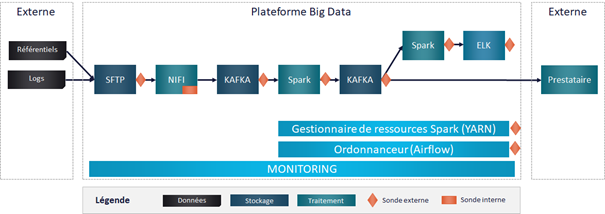
Dans notre projet, nous écoutons les logs sur SFTP pour détecter l’arrivée des nouveaux fichiers. Ensuite, Nifi compte le nombre de lignes par fichier au moment de les pousser dans Kafka. Nifi écrit directement dans la base SQL ces informations. Pour monitorer Kafka et Spark nous utilisons les métriques JMX (voir prochain article). Nous avons également un traitement Spark additionnel pour monitorer le Kafka en sortie. Et pour ELK nous faisons des appels à l’API.
Suivi de la donnée
Pour faciliter le suivi de la donnée et donc la supervision, il est préférable de penser la donnée dès la conception. C’est toujours possible ensuite, mais bien plus chronophage.
Identifiant
Il faut garder ou créer un identifiant unique par fichier (ou encore mieux par message ou ligne de données) tout au long de la chaîne de traitement. Dans le cadre du fichier, pensez à le récupérer lors de la lecture, à lui adjoindre un timestamp si le nom n’est pas unique, et à faire transiter cette information de bout en bout. Certes, cette information prend de la place supplémentaire (sur une plateforme Hadoop on n’est pas à quelques octets près), mais elle vous sera très précieuse pour la recette et pour le troubleshooting.
Pour avoir un identifiant unique par ligne de donnée, il suffit d’avoir le nom du fichier + l’identifiant de la ligne du fichier ou un autre identifiant unique généré. Ainsi, à chaque point de passage, vous pourrez identifier précisément les lignes perdues, exclues, doublonnées, etc.
Dans notre exemple avec Kafka, nous avons un identifiant unique par message d’un topic à disposition. Il suffit de concaténer la partition et l’offset du topic avec un séparateur (<partition>_<topic>). Afin de faciliter le suivi bout en bout, nous rajoutons également le nom du fichier source.
Grâce à cet identifiant unique, en cas d’anomalie dans un système cible, vous pourrez facilement retrouver votre donnée source pour analyse. Et vous pourrez même la retrouver à chaque étape de votre chaîne de traitement.
Timestamp
Pensez à stocker un timestamp ou une datetime à l’arrivée de la donnée sur votre plateforme. A chaque point de passage, sauvegardez aussi la date du traitement. Vous n’avez pas besoin de l’historique de chaque étape sur la ligne de données, il vous suffit de garder systématiquement le point d’entrée, et le dernier point de passage.
A partir de ces 2 informations, vous pourrez facilement calculer le délai de mise à disposition de votre donnée. Vous pourrez ainsi identifier quelle étape est la plus chronophage pour l’optimiser, ou détecter une dégradation des performances à un endroit précis.
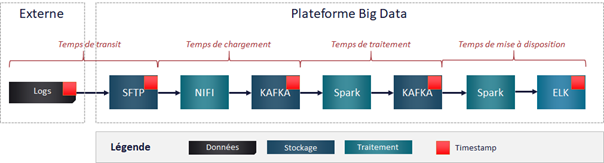
Dans notre exemple, nous gardons la date et l’heure d’arrivée du fichier sur le SFTP. Nous avons également à disposition le timestamp de génération de la log. Grâce à Kafka, chaque message est timestampé. On sait donc précisément le temps de traitement de chaque étape de la chaine.
Tags techniques
Pour faciliter le suivi humain, on ne monitore pas la donnée ligne par ligne. On agrège les informations pour les rendre plus lisibles. Ainsi, il peut être intéressant de rajouter des champs supplémentaires pour tagguer techniquement nos données. Nous pourrons ensuite utiliser ces tags comme dimensions dans nos agrégations. On peut avoir des hiérarchies entre les données afin d’avoir plusieurs niveaux de lecture.
Nous recevons des fichiers de plusieurs machines sources. L’information de la machine remonte au niveau de collecte, mais également la notion de pool (regroupement de machines), et aussi la zone géographique (regroupement de pools). Ainsi, nous regroupons plusieurs machines dans nos indicateurs visuels. Pour autant, nous avons toujours l’information de détails pour identifier quelle machine pose un problème.
Flag de test
Vous pouvez prévoir un champ dédié dans vos données pour les taguer comme étant soit des vraies données, soit des données de test. Ce système permet d’injecter en production des données dans la chaîne de traitement, et de vérifier le résultat en sortie. Le résultat attendu est connu.
Vous pouvez donc facilement automatiser des Tests de Non-Régression et de Conformité sur la Production pour garantir son bon fonctionnement. C’est un véritable contrôle de bout en bout. Il faut cependant bien le spécifier pour que les applications cibles exclus ces données si celles-ci sont mises à disposition. Vous pouvez aussi écrire ces données dans une sortie spécifique en fin de chaîne de traitement.
Dans notre exemple, les données de test sont alimentées dans un topic Kafka dédié. Ainsi, les prestataires peuvent y accéder uniquement si nécessaire. Au niveau de l’écriture dans ELK, les données ont été séparés dans des index distincts pour éviter toute confusion par les utilisateurs métier.
Méthodes pour mettre en place la supervision opérationnelle
Étape par étape
Pour mettre en place ce genre de supervision, il faut le faire étape par étape. On commence par collecter les données d’une application. Puis, on les analyse. Enfin, on crée quelques graphiques pour bien les visualiser et les comprendre.
Avec un petit historique, on peut identifier les métriques et les seuils pertinents pour une alerte. On peut ensuite mettre en place une ou deux alertes. Une fois que cela est fait, on peut recommencer à collecter de nouvelles données. Le cycle recommence.
Test & Learn
Il est important de bien tester les alertes sur une durée suffisante. On les teste en interne, on ajuste les seuils, on recommence les tests. Quand on est satisfait (alerte pertinente), alors on peut ouvrir l’envoi des alertes à toutes les personnes concernées.
Le monitoring est un projet fil rouge. On doit s’assurer que les alertes configurer sont toujours pertinentes. Si ce n’est plus le cas, alors il faut les ajuster ou les supprimer.
Utiliser les alertes avec parcimonie
Si les règles d’alertes génèrent trop d’emails, elles ne seront plus regardées. Les alertes ne doivent donc se déclencher que ponctuellement si l’on veut qu’elles aient de la valeur.
Si vous êtes noyés sous les alertes, le mieux sera alors de les revoir et surtout d’en revoir les seuils. Peut-être y a-t-il des alertes qui sont corrélées ? Si la plateforme tombe, vous êtes noyés sous les alertes parce que 10 règles différentes vont se déclencher. Dans ce cas, il faut corriger l’incident en cours, puis prendre du recul et challenger de nouveau les règles d’alertes.
On peut également créer des super incidents qui regroupent un ou plusieurs incidents. Seuls les super incidents génèrent des alertes envoyées par email. Il reste cependant possible de voir les incidents dans l’outil de monitoring.
Ressources dédiées pour la supervision
Il est important d’avoir des ressources dédiées pour la supervision. Le monitoring va prendre des ressources sur votre plateforme, mais il ne doit pas prendre de la place sur vos ressources gérant les traitements de Production.
Ainsi, sur YARN vous pouvez cloisonner vos ressources avec les queues. Pour la base de données SQL, prévoir une database dédiée, voire une instance dédiée au monitoring. Pour les droits, pensez à bien avoir un utilisateur dédié au monitoring qui pourra aller lire dans différents projets, mais sans pouvoir écrire.
La supervision doit être pensée comme un projet à part entière sur votre plateforme Hadoop. Vous maîtrisez ainsi ses ressources, son stockage, ses droits et son coût.
Vous connaissez désormais avec ce premier articles les bases pour la mise en place d’un monitoring opérationnel de votre plateforme Big Data. Dans le prochain, nous entrerons dans le détail des étapes de la supervision. Si vous voulez en savoir plus dès maintenant, n’hésitez pas à me contacter.
👉 Retrouvez toute notre actu en temps réel en nous suivant sur LinkedIn 👈


![[Data Rider] REX Collecte de données IoT – Étape 1 : Initier la collecte](https://fr.blog.businessdecision.com/wp-content/uploads/2025/05/data-rider-rex-collecte-donnees-1024x512-1.jpg)











Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.