
Vous avez sûrement lu de nombreux articles sur Hadoop et vous souhaitez maintenant vous familiariser avec. Mais comment faire pour apprivoiser cette nouvelle technologie ? L’approche recommandée consiste à installer une machine virtualisée fournie clé en main par les principaux éditeurs de distribution.

Une autre approche, plus technique, consiste à installer soi-même Hadoop sur une seule machine (cluster à 1 noeud) afin de bien comprendre ce qui ce cache derrière ces technologies.
Et pour vous aider, ça tombe bien, j’ai rédigé un tutoriel qui devrait vous permettre de franchir le pas. C’est parti !
Introduction et références du tutoriel Hadoop
Je dispose d’un Macbook pro sous Mavericks. Pour des questions de simplicité et pour ne pas perturber mon travail courant, j’ai choisi de faire tourner Hadoop sur une machine virtualisée avec VirtualBox (version 4.3.10).
Pour le système d’exploitation, j’ai retenu Centos (version 6.5 64 bits) qui correspond à la version libre de Red Hat. J’ai choisi la version « minimale » car je n’ai pas besoin d’interface graphique : l’administration et la gestion de Hadoop se fera en mode « remote » à partir de ma machine hôte à savoir mon mac.
Ce tutoriel s’est largement inspiré d’un article excellent de Michael Noll.
Mais aussi de la documentation officielle Apache.
Paramétrage du réseau
Ce que l’on veut, c’est que la machine invitée (Centos) puisse accéder au net pour simplifier l’installation des paquets Linux tout en étant accessible par la machine hôte (OSX) en remote pour de l’administration. On veut également pouvoir accéder aux interfaces web des différents services proposés nativement par Hadoop.
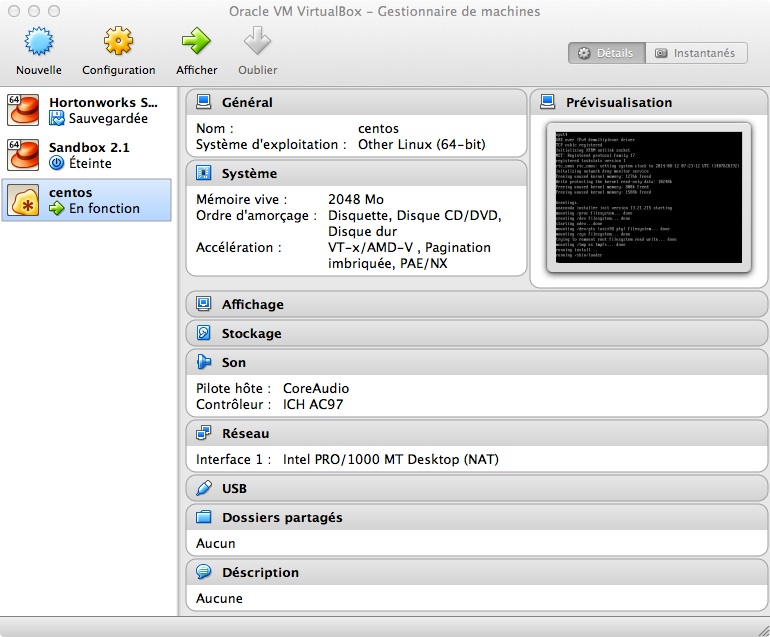
Pour se faire, nous allons configurer un réseau virtuel NAT au niveau de notre machine virtuelle.
Comme pour un poste physique, un réseau NAT assure une translation d’adresse ip entre l’adresse externe et l’adresse de la machine. Cela fait que la machine n’est plus accessible de l’extérieur. Et cela assure donc une meilleure sécurité.
Dans notre cas, c’est un peu plus gênant car le serveur invité ne sera plus visible de l’hôte. Heureusement nous pouvons contourner ce problème par une redirection des ports.
Cela se paramètre au niveau de la configuration réseau de la machine virtuelle.
On va indiquer à la machine hôte (127.0.0.1) que tous les flux sur le port 2222 devront être redirigés sur le port 22 (le port ssh par défaut) de notre machine invitée.
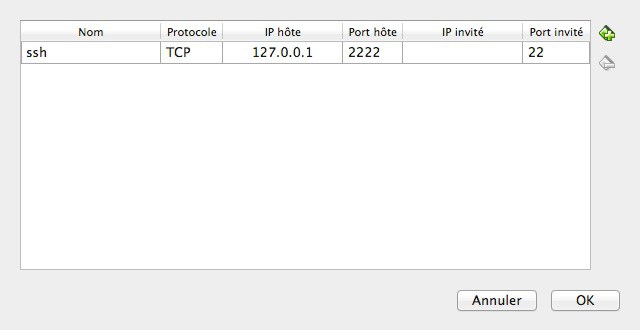
De cette manière, nous disposons d’une machine invitée qui pourra accéder au réseau externe et qui pourra communiquer avec sa machine hôte via ces redirections sur des ports spécifiques.
Une fois Centos installé, on va pouvoir s’occuper de la connexion à partir de la machine hôte.
Poursuivons ce tutoriel avec le paramétrage de la machine hôte…
Paramétrage accès à partir de la machine hôte
On a déjà redirigé le port 2222 mais ça ne suffit pas. L’installation « minimal » de Centos est vraiment minimale. L’interface eth0 n’est pas montée par défaut.
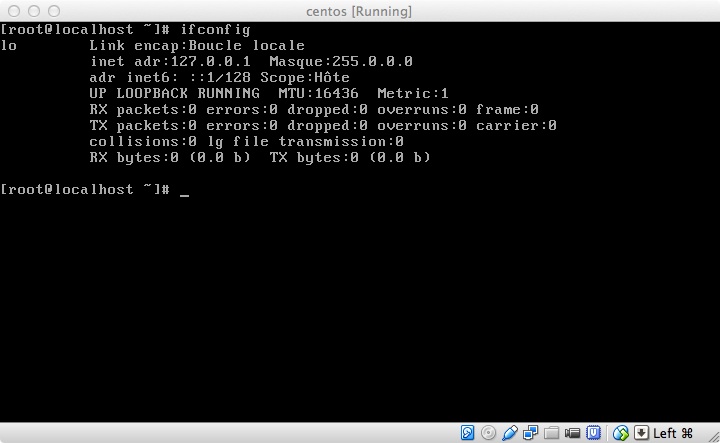
La commande ifconfig ne montre en effet que seule la boucle locale est active.
On va donc modifier le fichier de paramétrage
vi /etc/sysconfig/network-scripts/ifcfg-eth0
et passer ONBOOT à yes.
On sauvegarde. Puis on redémarre les services avec la commande :
service network restart
ifconfig pour vérifier:
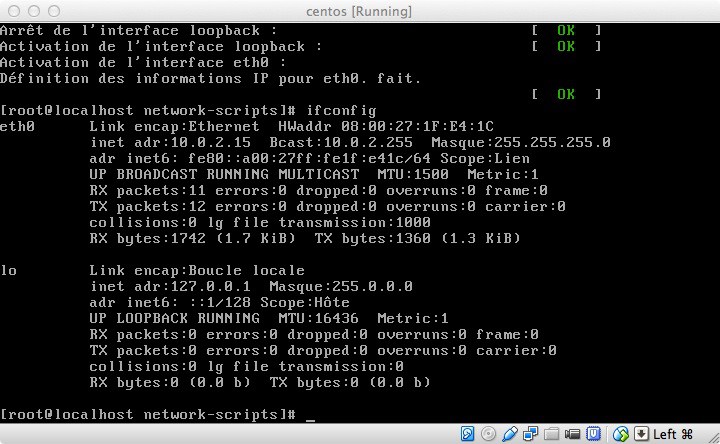
C’est mieux !
Du coup, je peux maintenant me connecter à partir de Terminal sous Mac pour accéder à ma machine Centos.
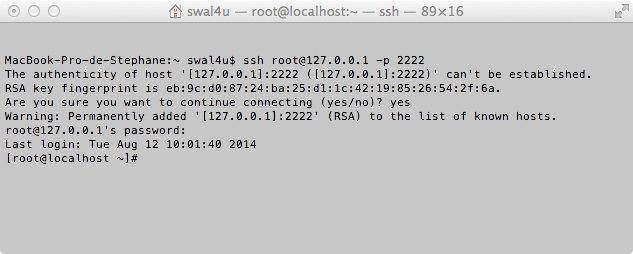
Si la connexion est refusée, cela peut provenir du fait que l’adresse ip 127.0.0.1 est peut-être déjà associée à une clé RSA différente correspondant à un serveur différent.
Le plus simple est de supprimer sur l’hôte le fichier stockant ces clés avec la commande :
rm /Users/userx/.ssh/known_hosts (à adapter en fonction de votre système hôte)
Configuration du ssh sur centos
Hadoop nécessite SSH pour fonctionner.
On installe les outils SSH client sur la machine Centos.
yum install openssh-clients
Puis on crée un groupe « hadoop »
groupadd hadoop
On crée ensuite notre utilisateur « hduser ».
useradd -g hadoop hduser
On va ensuite se connecter sous hduser et générer la clé publique de l’utilisateur qui permettra de s’authentifier de manière transparente sans ressaisir son mot de passe.
su – hduser
ssh-keygen -t rsa -P « »
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
Désactivation de l’IPV6
L’IPV6 pose des problèmes. Il est conseillé de le désactiver.
Pour se faire on modifie le fichier sysctl.conf.
vi /etc/sysctl.conf
Et on rajoute ces lignes en fin de document
# disable ipv6
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
Réglage de l’heure
S’il y a bien une chose que je trouve pénible sous VirtualBox, c’est que mes VM ne sont jamais à l’heure par défaut, ce qui n’est pas le cas sous VmWare. Heureusement, il y a une solution. (NB: en testant le tutoriel sur Yosemite et la dernière version de VirtualBox, je n’ai pas eu à régler l’heure).
On peut commencer par régler la date du système avec la commande :
Date –s HH :MM
Le problème, c’est qu’à chaque fois, l’heure se dérègle.
Ce que l’on veut, c’est en fait que l’heure de l’invité se cale sur l’heure de l’hôte.
Pour cela, il suffit de lancer la commande suivante :
sudo hwclock –hctosys
puis d’éteindre la VM
Exécuter sur l’hôte la commande suivante
VBoxManage modifyvm <nom VM> –biossystemtimeoffset -0
Et lorsque l’on relance, la VM est enfin à l’heure !
Installation de java
Pour avoir la liste des versions java.
J’ai retenu la version oracle 1.7.0_21.
On télécharge le fichier rpm sur le site d’oracle : jdk-7u21-linux-x64.rpm
On le transfère sur centos
scp -P 2222 jdk* root@127.0.0.1:/usr/local
puis on l’installe avec la commande suivante:
rpm –Uvh jdk-7u21-linux-x64.rpm
et voilà java installé.
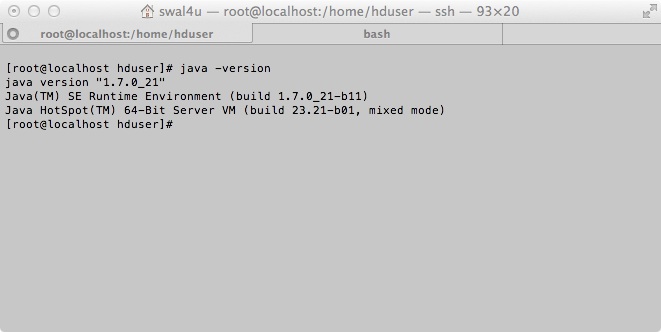
On peut vérifier l’installation avec la commande:
java -version
Installation Hadoop
Télécharger Hadoop sur le site Apache.
Puis le copier sur /usr/local
On va ensuite décompresser l’archive:
cd /usr/local
tar xvf hadoop-2.4.1.tar
On renomme le répertoire pour plus de simplicité:
mv hadoop-2.4.1 hadoop
On affecte ensuite les droits à notre utilisateur hduser:
chown -R hduser:hadoop hadoop
Paramétrage du fichier .bashrc (hduser)
Rajouter les lignes suivantes à la fin fu fichier $HOME/.bashrc
# Set Hadoop-related environment variables
export HADOOP_HOME=/usr/local/hadoop
# Set JAVA_HOME (we will also configure JAVA_HOME directly for Hadoop later on)
export JAVA_HOME=/usr/java/latest
# Some convenient aliases and functions for running Hadoop-related commands
unalias fs &> /dev/null
alias fs="hadoop fs"
#unalias hls &> /dev/null
alias hls="fs -ls"
# If you have LZO compression enabled in your Hadoop cluster and
# compress job outputs with LZOP (not covered in this tutorial):
# Conveniently inspect an LZOP compressed file from the command
# line; run via:
#
# $ lzohead /hdfs/path/to/lzop/compressed/file.lzo
#
# Requires installed 'lzop' command.
#
#lzohead () {
# hadoop fs -cat $1 | lzop -dc | head -1000 | less
#}
# Add Hadoop bin/ directory to PATH
export PATH=$PATH:$HADOOP_HOME/bin
Rebooter la machine
Finalisation du paramétrage Hadoop
Création d’un répertoire temporaire pour Hadoop
mkdir -p /app/hadoop/tmp
chown hduser:hadoop /app/hadoop/tmp
chmod 750 /app/hadoop/tmp
Les fichiers de paramétrage se trouve à l’emplacement suivant: /usr/local/hadoop/etc/hadoop
Paramétrage core-site.xml
Copier les lignes suivantes entre les balises de configurations.
<property> <name>hadoop.tmp.dir</name> <value>/app/hadoop/tmp</value> <description>A base for other temporary directories.</description> </property> <property> <name>fs.default.name</name> <value>hdfs://localhost:9000</value> <description>The name of the default file system. A URI whose scheme and authority determine the FileSystem implementation. The uri's scheme determines the config property (fs.SCHEME.impl) naming the FileSystem implementation class. The uri's authority is used to determine the host, port, etc. for a filesystem.</description> </property>
Paramétrage hdfs-site.xml
Copier les lignes suivantes entre les balises de configurations.
<property> <name>dfs.replication</name> <value>1</value> <description>Default block replication. The actual number of replications can be specified when the file is created. The default is used if replication is not specified in create time. </description> </property>
Paramétrage mapred-site.xml
Au préalable : cp mapred-site.xml.template mapred-site.xml
Puis copier les lignes suivantes entre les balises de configurations
<property> <name>mapred.job.tracker</name> <value>localhost:9001</value> </property>
Formatage du NameNode
Sous hduser:
hadoop namenode –format
Démarrage de Hadoop
cd /usr/local/hadoop
sbin/start-dfs.sh
Réglage du firewall
Le firewall est activé par défaut sur centos. On va donc le désactiver afin de pourvoir tester la connexion via l’interface http.
service iptables stop
Vérification de l’installation
On peut maintenant accéder à l’interface web Hadoop à partir de la machine hôte sur 127.0.0.1:50070
Merci pour la lecture de ce tutoriel !
edit: Pierre a signalé dans les commentaires un problème d’accès à l’interface web hadoop et a trouvé une solution alternative. Une solution plus simple consiste à rajouter une redirection du port 50070 au niveau du paramétrage réseau de notre machine virtuelle.
👉 Retrouvez toute notre actu en temps réel en nous suivant sur LinkedIn 👈


![[Data Rider] REX Collecte de données IoT – Étape 1 : Initier la collecte](https://fr.blog.businessdecision.com/wp-content/uploads/2025/05/data-rider-rex-collecte-donnees-1024x512-1.jpg)











Commentaires (4)
Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.
malheureusement rien sur l'adresse
127.0.0.1:50070
Pourquoi ce numero de port ?
C'est le port par défaut d'accès à la console Hadoop.
Difficile de t'aider sur ton problème sinon.
Je t'invite à bien t'assurer que l'accès au port 50070 est bien ouvert.
Bon courage.
On peut récupérer l'adresse IP avec "ifconfig" sur la VM qui commence par 192.168.
on peut ensuite aller sur https://192.168.X.X:50070 et ca marche.
Je pense que le problème initial vient de la redirection de port qui n'est pas faite sur le 50070.
Cela évite de créer un deuxième réseau.