
Nous allons aborder aujourd’hui l’apprentissage d’un réseau de neurones. Cet article fait suite à notre précédent tutoriel « Comprendre ce qu’est un réseau de neurones et en créer un ! ». Vous découvrirez ici comment apprend un réseau de neurones et surtout comment vous allez pouvoir, concrètement, mettre en place cet apprentissage.
![[TUTORIEL] Machine Learning : comment mettre en place l'apprentissage d'un réseau de neurones ?](https://blog.businessdecision.com/wp-content/uploads/2020/11/tuto-resaux-neurones-apprentissage-part2-835x400-1.jpg)
Notre réseau de neurones
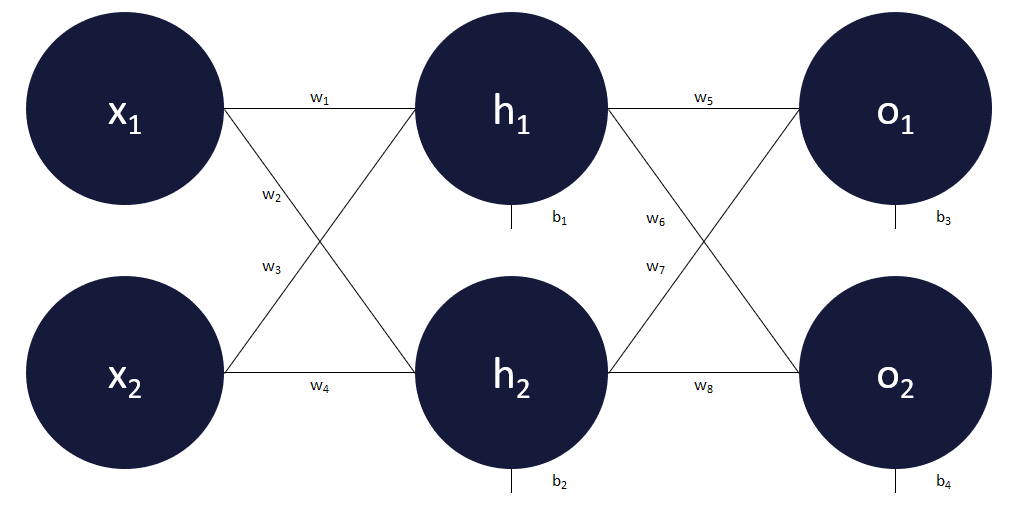
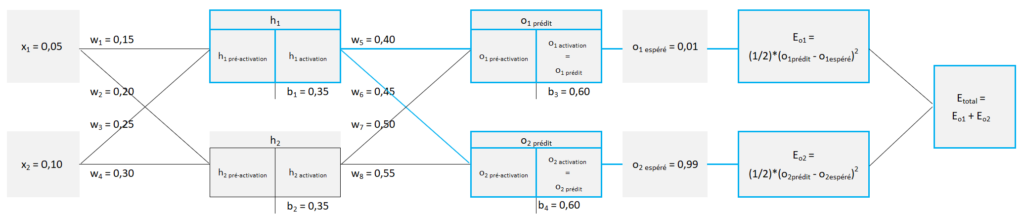
Voici le réseau de neurones que nous allons utiliser dans cet article afin de vous expliquer comment un réseau de neurones apprend par lui-même à corriger ses erreurs.
Ce réseau est donc composé :
- d’une couche d’entrée qui comprend 2 entrées x1 et x2,
- d’une couche cachée qui comprend 2 neurones h1 et h2,
- d’une couche de sortie qui comprend également 2 neurones o1 et o2, ces 2 sorties seront respectivement désignées comme o1prédit et o2prédit,
- il y a 8 poids et 4 biais.
La fonction d’activation choisie est la fonction sigmoïde.
Pour des raisons pratiques, et comme j’utilise Excel afin d’illustrer mes propos, notre réseau devient le suivant (rien n’a changé, hormis la mise en page).
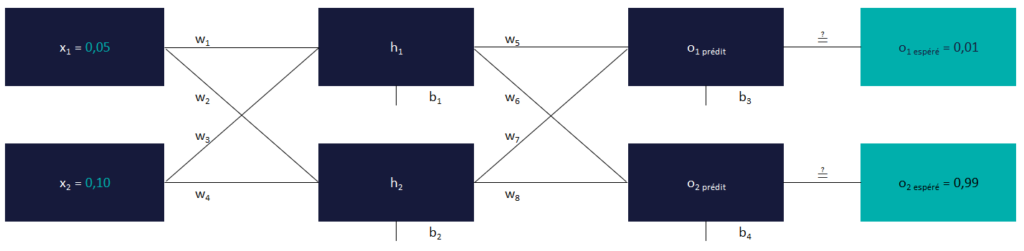
Nos données d’entrées et nos sorties attendues
Ce que nous souhaitons faire avec ce réseau :
Quelles que soient les valeurs x1 et x2 renseignées en entrée, nous souhaitons que o1 soit le plus proche possible de 0,01 et o2 le plus proche possible de 0,99.
Rem. cet objectif n’a aucun intérêt dans un environnement de production, il est simplement utilisé ici pour des raisons pédagogiques.
Nous allons utiliser, pour la phase d’apprentissage, des valeurs fixes pour x1 et x2 (respectivement 0,05 et 0,10). Puis, nous changerons ces valeurs après la phase d’apprentissage afin de voir si les sorties prédites restent respectivement proches de 0,01 et de 0,99.
Nos poids et biais aléatoires
Nous allons commencer avec des poids et biais aléatoires, ce sont ces valeurs que la machine va faire évoluer, seule, afin que x1 et x2 soient, respectivement, e plus proche de 0,01 et 0,99, et ce, indépendamment de leur valeur.
Notre réseau, dans son état initial, est donc le suivant (cliquer sur le schéma pour l’agrandir).

Comme vous pouvez le voir, 3 éléments ont été ajoutés :
- Eo1 >>> l’erreur o1 représente la moitié de la différence, au carré, entre o1prédit et o1espéré (ex. o1prédit = 0,5 ; o1espéré = 0,01 ; Eo1 = (1/2) * (0,5 – 0,01)2 = 0,12005)
- Eo2 >>> l’erreur o2 représente la moitié de la différence, au carré, entre o2prédit et o2espéré (ex. o2prédit = 0,3 ; o1espéré = 0,99 ; Eo2 = (1/2) * (0,3 – 0,99)2 = 0,23805)
- Etotal >>> l’erreur totale est tout simplement la somme de Eo1 et de Eo2.
Dans la mesure où nos 2 dernières couches (couche cachée et couches de sortie) comprennent une formule de pré-activation et une formule d’activation, notre réseau se présente sous la forme suivante (cliquer sur le schéma pour l’agrandir).

Pour rappel, si l’on prend h1, il est calculé en 2 temps :
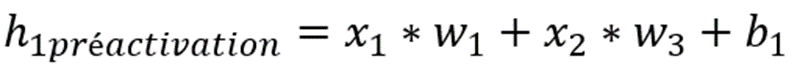

C’est la même chose pour h2, o1, o2.
1ère itération
En faisant les calculs, voici les résultats obtenus (cliquer sur le tableau pour l’agrandir).
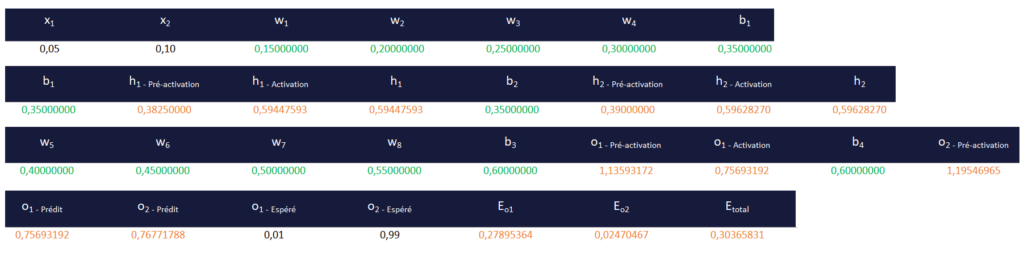
- En noir : des données fixes, qui ne changeront pas entre 2 itérations,
- En vert : les poids et biais qui vont être optimisés à chacune des itérations, et donc être modifiés
- En orange : les résultats des formules de pré-activation et d’activation qui seront calculés à chaque itération en fonction des nouveaux poids et biais modifiés à chaque itération
h1préactivation par exemple, est égal à :
x1 * w1 + x2 * w3 + b1 = 0,05 * 0,15 + 0,10 * 0,25 + 0,35 = 0,3825
h1activation, est donc égal à :
1 / (1 + e-0,3825) = 0,594475931
L’action consistant à faire les calculs de la gauche vers la droite, au regard des poids et biais à un instant T, est appelée forward.
Descente de gradient
Pour rappel, nous souhaitons trouver des poids et biais qui permettent, quelles que soient les entrées x1 et x2, d’avoir un o1prédit le plus proche de 0,01 et o2prédit le plus proche de 0,99.
Comme pour les régressions linéaires simple et multiple, nous allons utiliser la méthode de la descente de gradient, appelée rétropropagation du gradient dans un réseau de neurones.
Notre fonction coût Etotal dépend des valeurs de :
– w1
– w2
– w3
– w4
– w5
– w6
– w7
– w8
– b1
– b2
– b3
– b4
Ce sont les seules valeurs qui peuvent être modifiées dans ce réseau de neurones.
Nous allons chercher les 12 dérivées partielles de Etotal par rapport à chacune de ces variables, puis utiliser ces dérivées pour calculer leurs nouvelles valeurs.
Pour rappel et par exemple pour b4 :

Si vous ne comprenez pas l’intérêt d’utiliser les dérivées afin d’optimiser ces 12 valeurs, nous vous invitons à consulter notre article sur la régression linéaire et la descente de gradient.
Pour calculer ces dérivées, nous allons partir de la couche de sortie puis revenir vers la couche d’entrée en calculant, pour chacune des couches, les dérivées de chacun des poids et biais la constituant.
Dérivée de Etotal par rapport à w5

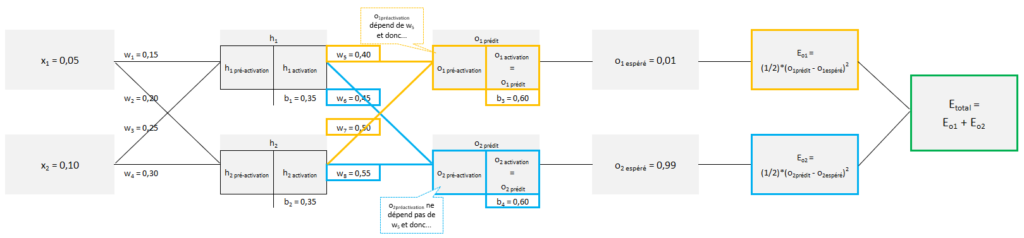
Avant de rentrer dans les calculs, nous allons décomposer Etotal.
Etotal est la somme de Eo1 et de Eo2.
Prenons Eo1.
Les éléments qui permettent de calculer Eo1 sont indiqués en orange ci-dessus.
Effectivement,
- Eo1 dépend de o1prédit,
- o1prédit (qui est égal à o1activation) dépend de o1préactivation
- o1préactivaion dépend de b3, w5 et de w7.
Pour rappel, nous souhaitons dériver Etotal par rapport à w5. Si l’on prend le « chemin » de Eo1, on voit bien que Eo1 dépend de w5. La dérivée de Eo1 par rapport à w5 n’est pas nulle.
Prenons maintenant Eo2.
Les éléments qui permettent de calculer Eo2 sont indiqués en bleu ci-dessus.
Effectivement,
- Eo2 dépend de o2prédit,
- O2prédit (qui est égal à o2activation) dépend de o2préactivation
- O2préactivaion dépend de b4, w6 et de w8.
Pour rappel, nous souhaitons dériver Etotal par rapport à w5. Si l’on prend le chemin de Eo2, on voit, à la différence de Eo1, que Eo2 ne dépend pas de w5. La dérivée de Eo2 par rapport à w5 est nulle.
Revenons à nos calculs, si on développe notre formule, voici ce que cela donne.
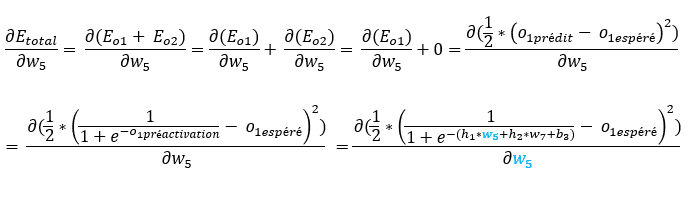
Rappelez-vous…
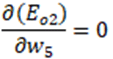
Cela semble compliqué sauf si on utilise le « théorème de dérivation des fonctions composées ».
Celui-ci indique que :
– si nous avons une fonction : f(g(h(x)))
– alors sa dérivée partielle est :
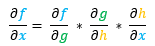
Dans notre situation :
f = Eo1
x = w5
g = o1activation
h = o1préactivation
Effectivement,
- f (Eo1) dépend de g (o1activation),
- g (o1activation) dépend de h (o1préactivation).
Ainsi :
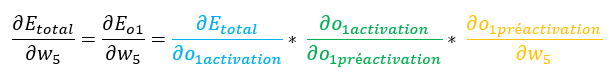
On va traiter ces éléments un par un.
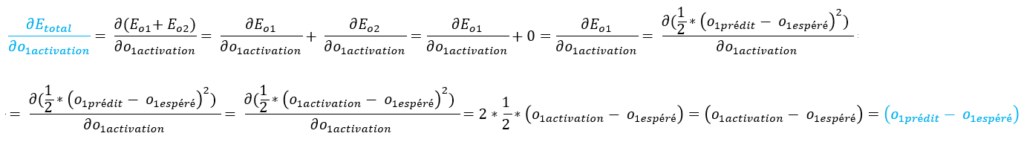
Explications :
– la dérivée de Eo2 par rapport à o1activation est égale à 0 car Eo2 ne dépend pas de o1activation.
– o1activation = o1prédit

Explications :
– la dérivée d’une sigmoïde est égale à : (sigmoïde * (1 – sigmoïde))
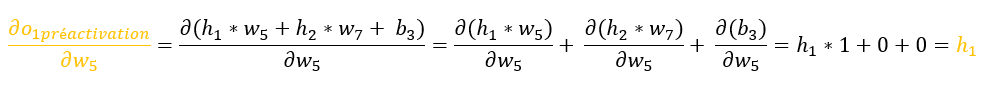
Revenons donc à :

Dérivée de Etotal par rapport à w6
Le raisonnement est identique, je vais simplement indiquer en bleu les éléments qui ont changé par rapport à la dérivée de Etotal par rapport à w5.
Dérivée de « Etotal » par rapport à « w6«
= (o2prédit – o2espéré) * (o2prédit * (1 – o2prédit)) * h1
Dérivée de Etotal par rapport à w7
Dérivée de « Etotal » par rapport à « w7«
= (o1prédit – o1espéré) * (o1prédit * (1 – o1prédit)) * h2
Dérivée de Etotal par rapport à w8
Dérivée de « Etotal » par rapport à « w8«
= (o2prédit – o2espéré) * (o2prédit * (1 – o2prédit)) * h2
Dérivée de Etotal par rapport à b3
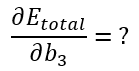
Comme ci-dessus, si l’on remplace les éléments par leur calcul, voici, de manière littéraire, ce que cela donne.
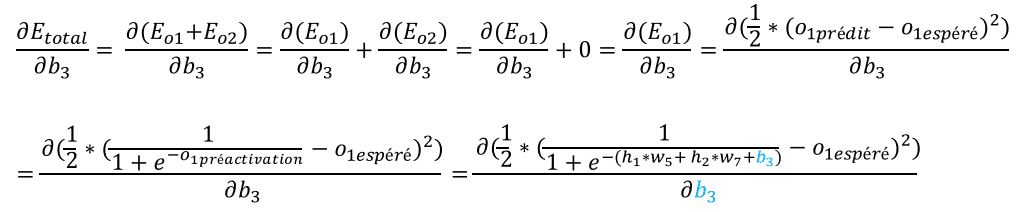
Explications :
– la dérivée de Eo2 par rapport à b3 est nulle car Eo2 ne dépend pas de b3.
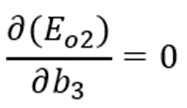
Comme précédemment, nous allons utiliser le « théorème de dérivation des fonctions composées ».
Ainsi :
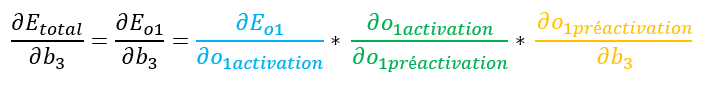
Comme précédemment, on va traiter ces éléments un par un.

Notre équation complète est donc :

Dérivée de Etotal par rapport à b4
Le raisonnement étant identique, j’indique en bleu les éléments qui changent.
Dérivée de « Etotal » par rapport à « b4«
= (o2prédit – o2espéré) * (o2prédit * (1 – o2prédit))
Dérivée de Etotal par rapport à w1
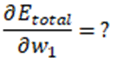
En raison du théorème de dérivation des fonctions composées…
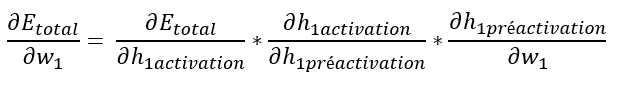
Intéressons-nous tout d’abord à :
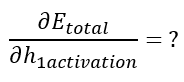
Si l’on regarde notre réseau de neurones, on voit que h1activation influence o1 (et donc Eo1) mais aussi o2 (et donc Eo2).
On peut donc écrire :
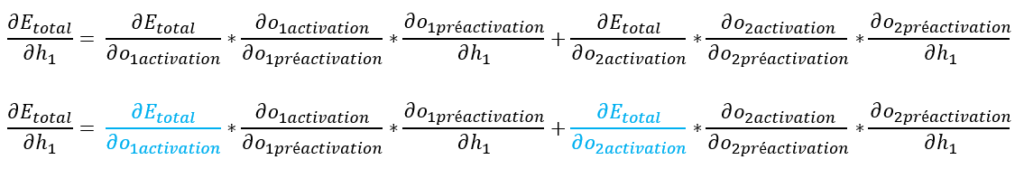
Nous allons nous intéresser aux dérivées de Etotal par rapport respectivement à o1activation et à o2activation.
Commençons par ∂Etotal / ∂o1activation.
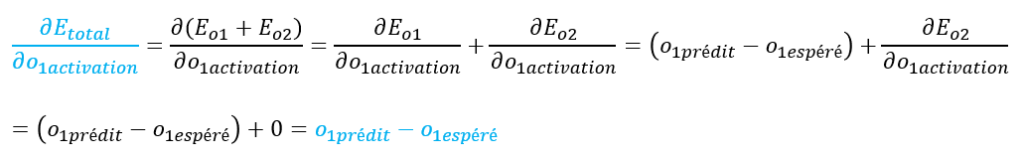
Explications :
– la dérivée de Eo1 par rapport à o1activation a déjà été calculée précédemment
– la dérivée de Eo2 par rapport à o1activation est égale à 0 car Eo2 ne dépend pas de o1activation
– o1activation = o1prédit
Et maintenant, ∂Etotal / ∂o2activation.

Explications :
– la dérivée de Eo1 par rapport à o2activation est égale à 0 car Eo1 ne dépend pas de o2activation
– la dérivée de Eo2 par rapport à o2activation a déjà été calculée précédemment
– o2activation = o2prédit
Notre formule ∂Etotal / ∂h1 devient :
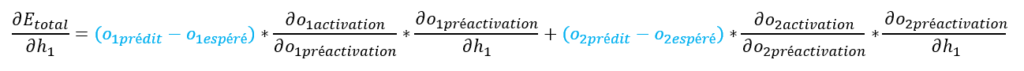
Les éléments en noir ont déjà été calculés précédemment, notre formule finale Etotal / ∂h1 devient :
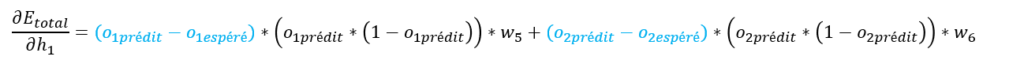
Revenons à l’objectif de cette partie, à savoir le calcul de ∂Etotal / ∂w1.
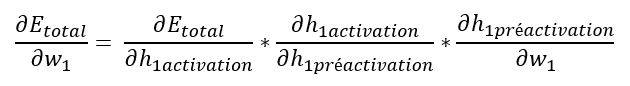
Nous venons de calculer ∂Etotal / ∂h1 (rappel, h1 = h1activation), il nous reste à calculer les 2 autres éléments de notre formule (en jaune et violet ci-dessous).

Notre équation complète est donc :

Dérivée de Etotal par rapport à w2
Dérivée de « Etotal » par rapport à « w2«
= [ ((o1prédit – o1espéré)*(o1prédit)*(1-o1prédit)*w7) + ((o2prédit – o2espéré)*(o2prédit)*(1-o2prédit)*w8) ] * [ ((h2)*(1-h2)) ] * [ x1 ]
Dérivée de Etotal par rapport à w3
Dérivée de « Etotal » par rapport à « w3«
= [ ((o1prédit – o1espéré)*(o1prédit)*(1-o1prédit)*w5) + ((o2prédit – o2espéré)*(o2prédit)*(1-o2prédit)*w6) ] * [ ((h1)*(1-h1)) ] * [ x2 ]
Dérivée de Etotal par rapport à w4
Dérivée de « Etotal » par rapport à « w4«
= [ ((o1prédit – o1espéré)*(o1prédit)*(1-o1prédit)*w7) + ((o2prédit – o2espéré)*(o2prédit)*(1-o2prédit)*w8) ] * [ ((h2)*(1-h2)) ] * [ x2 ]
Dérivée de Etotal par rapport à b1
Dérivée de « Etotal » par rapport à « b1«
= [ ((o1prédit – o1espéré)*(o1prédit)*(1-o1prédit)*w5) + ((o2prédit – o2espéré)*(o2prédit)*(1-o2prédit)*w6) ] * [ ((h1)*(1-h1)) ]
Dérivée de Etotal par rapport à b2
Dérivée de « Etotal » par rapport à « b2«
= [ ((o1prédit – o1espéré)*(o1prédit)*(1-o1prédit)*w7) + ((o2prédit – o2espéré)*(o2prédit)*(1-o2prédit)*w8) ] * [ ((h2)*(1-h2)) ]
Forward et Backward
L’activité consistant à faire les calculs de la gauche vers la droite, c’est-à-dire de la couche d’entrée vers la couche de sortie, est appelé Forward.
A la fin de celle-ci, une erreur est calculée. Dans notre cas, il s’agit de Etotal.
Cette erreur va nous permettre de faire une marche arrière, et de corriger légèrement – et à chaque itération – nos poids et biais.
Nous allons donc faire des itérations successives afin que les dérivées partielles de Etotal par rapport à tous les poids et biais soient le plus proche possible de 0.
Concrètement, voici les étapes que nous allons suivre :
- Etape initiale : cette étape initiale a déjà été faite car elle consiste à donner des valeurs aléatoires aux poids et biais. Cette étape n’est à faire qu’une seule fois.
- Etape 1 : calcul de toutes les dérivées partielles de tous les poids (w) et biais (b) par rapport à Etotal, et ce au regard de toutes les valeurs à un instant T du réseau,
- Etape 2 : si celles-ci ne tendent pas vers 0, les variables associées peuvent encore être optimisées selon la descente de gradient. De nouveaux poids (w) et biais (b) seront calculés en même temps, de la même manière que dans le cas de la régression linéaire, à savoir : nouveau w<sup>i</sup> = ancien w<sup>i</sup> – learning rate * ∂Etotal/∂w (rem. c’est la même chose pour les biais).
- Etape 3 : les nouveaux poids (w) et biais (b) calculés seront utilisés dans le cadre d’une nouvelle itération, et permettront de recalculer tout ce qui en dépend, à savoir : h1préactivation, h1activation, h2préactivation, h2activation, o1préactivation, o1activation, Eo1, o2préactivation, o2activation, Eo2, Etotal
On recommence les étapes 1, 2, 3 un très grand nombre de fois jusqu’à trouver :
Eo1 très proche de 0
Eo2 très proche de 0
et par voie de conséquence
o1prédit très proche de 0,01
o2prédit très proche de 0,99
Si l’on change les valeurs de x1 et de x2, on trouvera toujours en sortie Eo1 et Eo2 très proche de 0… et donc… et donc o1prédit très proche de 0,01, o2prédit très proche de 0,99.
Vous pouvez trouver un fichier excel ici qui je l’espère vous aidera à lever vos interrogations éventuelles. Celui-ci vous décrira à nouveau notre réseau de neurones, ce que l’on en attend, son fonctionnement, mais surtout les calculs.








![[Data Rider] Booster Mario Kart à l'IoT et à l'IA – Étape 3 : écoconduite et consommation électrique](https://fr.blog.businessdecision.com/wp-content/uploads/2024/08/data-rider-ecoconduite-1024x512-1.jpg)




Commentaires (3)
Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.
Une seule envie faire votre connaissance pour apprendre car je suis passionné du data sciences en général et en particulier le Machine Learning, le Deep Learning et la Visualisation des données.
merci pour votre commentaire.
Business & Decision travaille tout particulièrement sur les sujets que vous évoquez (Machine Learning, Deep Learning et DataViz).
Certains de ces sujets sont traités dans d'autres articles :
- DataViz : https://fr.blog.businessdecision.com/les-concepts-de-data-story-telling-au-service-de-la-dataviz-replay/
- D’autres tutoriels sur le Machine Learning :
https://fr.blog.businessdecision.com/tutoriel-machine-learning-comprendre-ce-quest-un-reseau-de-neurones-et-en-creer-un/
https://fr.blog.businessdecision.com/tutoriel-regression-lineaire-et-descente-de-gradient-en-machine-learning/
D'autres articles sur la Data Science seront prochainement publiés et leur exploitation sur Excel à travers des exemples simples.
Si vous souhaitez nous rejoindre, vous pouvez retrouver toutes nos offres d’emploi et postuler sur : https://rh.businessdecision.com/
Bonne journée
Kévin V.
Un grand merci pour l'article.