
Nous arrivons à notre quatrième et dernier volet de notre série de tutoriels destinés à vous faire découvrir MongoDB. Je vous propose aujourd’hui d’aborder les possibilités d’agrégation. C’est parti !

Agrégation simple
Pour illustrer l’agrégation, nous allons travailler sur une collection zips qui contient les villes des États-Unis. Le niveau de granularité est le code postal (ZIP: Zoning Improvement Plan). Outre ce code ZIP, chaque document contient la population de la zone considérée, les coordonnées GPS, la ville et l’état de rattachement.
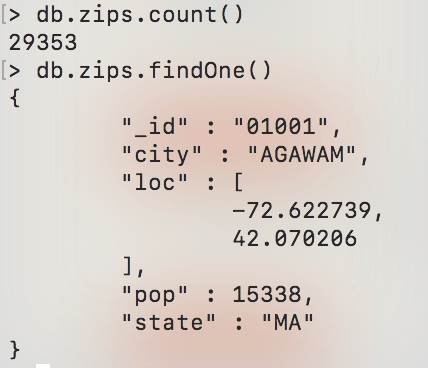
Nous pouvons commencer par calculer la population de chaque Etat en utilisant la fonction aggregate , le mot clé $group pour regrouper sur les Etats, le mot clé $sum pour sommer les éléments de population.
db.zips.aggregate({$group:{_id:"$state",population:{$sum:"$pop"}}})
Replay
Optimiser, gérer et contrôler ses coûts avec la Plateforme Data Cloud Snowflake
Lire la suiteExaminons plus en détail la syntaxe.
$group indique un regroupement. La clé de regroupement est indiquée par id.
Dans notre cas, nous lui passons le code de l’Etat $state(le $ précise qu’il faut reprendre le champ state de notre collection zip.
$sum: ” $pop “ indique que l’on va additionner les populations de chaque code postal.
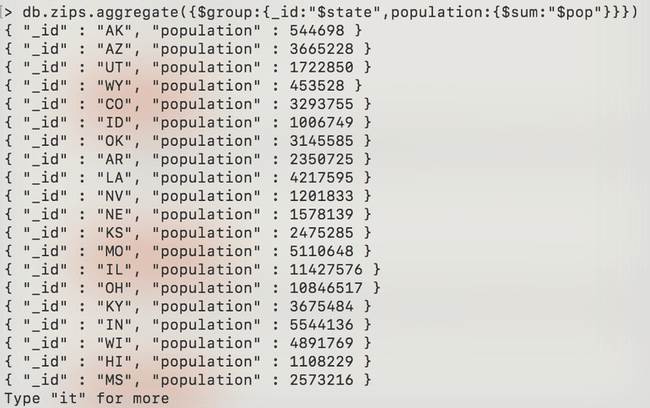
Nous pouvons faire des additions. Nous pouvons aussi faire des moyennes.
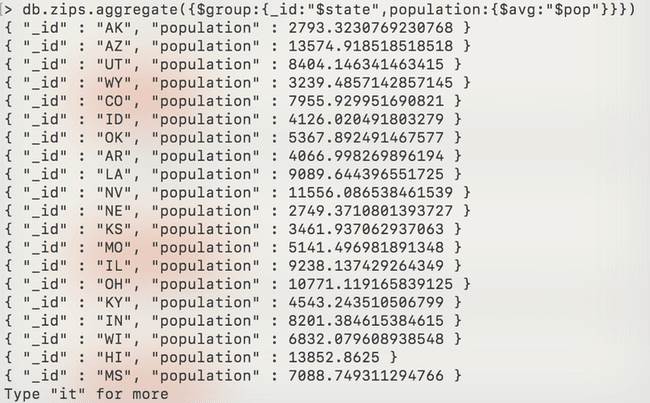
MongoDB propose plusieurs opérateurs d’agrégation ($min, $max, $first, $last, $push, $addToSet, $stdDevPop, $stdDevSamp).
Vous trouverez plus de précisions sur ces opérateurs dans la documentation MongoDB.
Calculer, c’est bien. Trier c’est mieux !
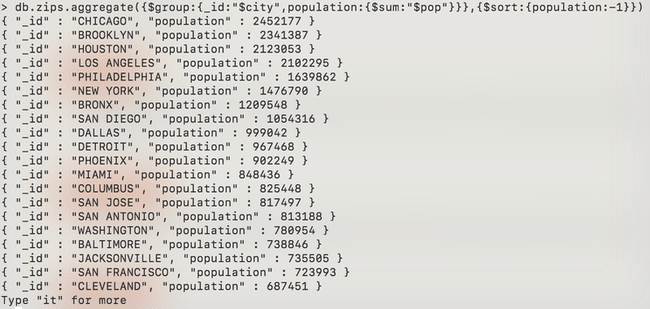
Comment faire si nous souhaitons trouver les villes les plus peuplées des Etats-Unis ? Nous aimerions calculer la population de chaque ville puis trier les villes par ordre décroissant de leur population.
C’est possible grâce au mot clé $sort.
db.zips.aggregate({$group:{_id:"$city",population:{$sum:"$pop"}}},{$sort:{population:-1}})
Dans notre cas, la fonction aggregate prend en deuxième argument le tri des données qui sont traités séquentiellement. On parle ici d’étape ou de stage dans le traitement d’agrégation.
Rajoutons maintenant un filtre pour ne conserver que les villes de Californie. On pourrait le placer n’importe où dans notre chaîne de traitement. Néanmoins, le plus efficace est de le placer en début de chaîne pour limiter les calculs ultérieurs.
Cela se fait avec le mot clé $match.
db.zips.aggregate({$match:{state:"CA"}},{$group:{_id:"$city",population:{$sum:"$pop"}}},{$sort:{population:-1}})
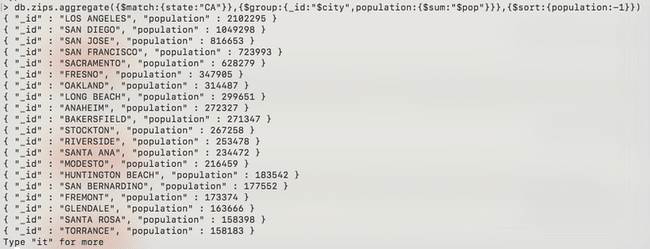
Dans nos exemples précédents, nous avons toujours utilisé un champ de la collection (dans notre cas, « pop ») pour faire nos calculs (somme ou moyenne). Néanmoins, ce n’est pas une obligation.
La commande suivante permet ainsi de compter le nombre de codes postaux par état.
db.zips.aggregate({$group:{_id:"$state",nb_zip:{$sum:1}}},{$sort:{nb_zip:-1}})
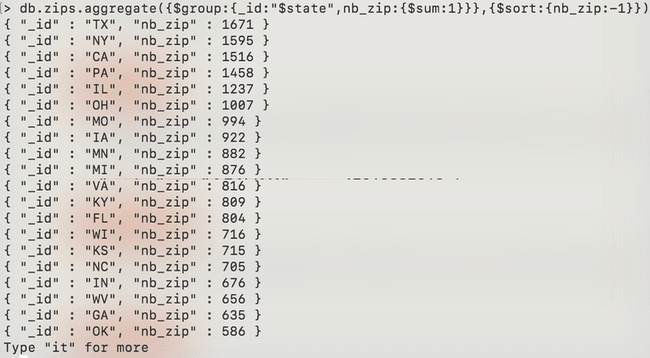
Cette approche nous permet ainsi d’avoir l’équivalent d’un count en SQL.
Le pipeline d’agrégation
Lorsque nous avons fait notre requête d’agrégation sur les villes les plus peuplées de Californie, nous avons en fait créer un enchaînement de 3 étapes (filtre, agrégation, tri). MongoDB appelle cette approche le pipeline d’agrégation.
Les étapes peuvent être multiples. Ainsi, imaginons qu’au lieu de compter les codes postaux par Etat, nous désirions comptabiliser le nombre de villes par état.
Comment faire ?
Nous allons simplement faire un premier regroupement par Etat et ville (pour éviter de regrouper des villes situées dans des états différents mais portant le même nom) puis comptabiliser ensuite le nombre de villes par état.
La première étape consiste donc à opérer un regroupement sur 2 champs.
db.zips.aggregate({$group:{_id:{state:"$state",city:"$city"}}})

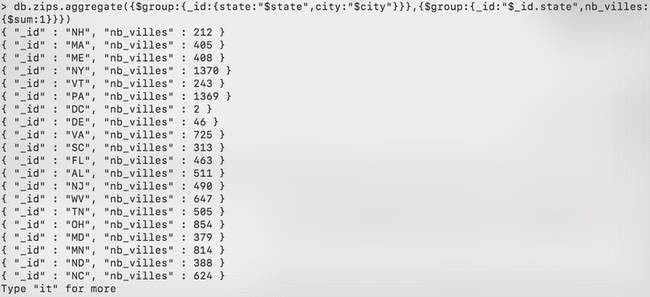
Puis, on regroupe maintenant les villes par Etat. Le champ « état » s’appelle maintenant _id.state.
db.zips.aggregate({$group:{_id:{state:"$state",city:"$city"}}},{$group:{_id:"$_id.state",nb_villes:{$sum:1}}})
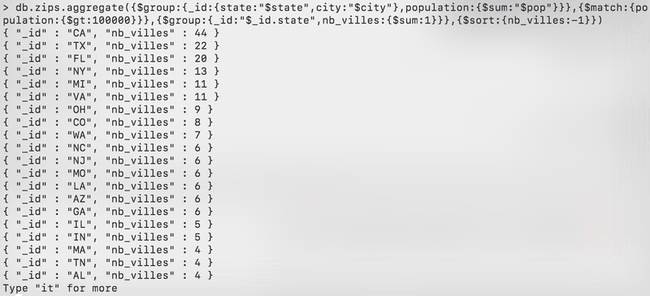
Amusons-nous alors un peu. Imaginons maintenant que nous souhaitions afficher les états ayant le plus de villes à plus de 100 000 habitants. Nous allons alors intercaler dans notre traitement un filtre sur le nombre d’habitants et rajouter à la fin un tri par ordre décroissant. Bien sûr, il ne faut pas oublier dans la première étape de calculer la population de chaque ville puisque nous allons en avoir besoin dans notre filtre à l’étape 2.
db.zips.aggregate({$group:{_id:{state:"$state",city:"$city"},population:{$sum:"$pop"}}},{$match:{population:{$gt:100000}}},{$group:{_id:"$_id.state",nb_villes:{$sum:1}}},{$sort:{nb_villes:-1}})
Encore d’autres possibilités
Nous avons donc vu les types d’étape suivants :
- $group: groupement des données
- $match: filtre des données
- $sort: tri des données
MongoDB propose de nombreux autres types. Citons par exemple, sans que cette liste soit exhaustive :
- $project: pour sélectionner les champs que l’on souhaite conserver dans le résultat
- $limit: pour limiter les résultats
- $skip: pour sauter n résultats
- $unwind: pour opérer une transposition sur un champ contenant un tableau
- $out: pour enregistrer le résultat dans une nouvelle collection
Mais aussi des limitations
La documentation précise que les étapes d’agrégation ne doivent pas consommer plus de 100 Mo en mémoire sous peine de générer une erreur.
Cette limitation pouvant être rapidement contraignante, on peut l’outrepasser en passant le paramètre allowDiskUse à true.
Le passage de paramètre se fait en fin de commande après les stages. Pour différencier les stages des paramètres, il faut veiller à mettre les stages dans un tableau.
db.zips.aggregate([{$group:{_id:{state:"$state",city:"$city"},population:{$sum:"$pop"}}},{$match:{"_id.state":"CA"}},{$sort:{population:-1}}],{allowDiskUse:true})

Bien évidemment, si cela permet de dépasser la limitation, les performances vont s’en ressentir.
Dans tous les cas, n’oublions pas que MongoDB est une solution scalable permettant de répondre à un grand nombre de requêtes concurrentes. Pour des besoins d’agrégation sur un historique profond, privilégiez plutôt Hadoop ou Spark.
👉 Retrouvez toute notre actu en temps réel en nous suivant sur LinkedIn 👈














Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.