
Zeppelin est le compagnon idéal de toute installation Spark. C’est un notebook qui permet de faire des analyses interactives au travers d’un navigateur web. Il permet d’exécuter du code Spark et de visualiser les résultats dans des tableaux ou graphiques. Pour en savoir plus, suivez le guide !

Installation de Zeppelin
Si, comme moi vous avez installé une instance Spark autonome sans hadoop, je vous conseille de faire une « build » de Zeppelin à partir des sources. Il est cependant nécessaire pour cela d’installer au préalable Maven.
Pour lancer la build de Zeppelin avec Spark 1.5.2, il faut exécuter la commande suivante :
mvn clean package -Pspark-1.5
Ensuite, il faut configurer Zeppelin en indiquant les paramètres pour se connecter à votre instance Spark. Cela se passe au niveau des fichiers zeppelin-env.sh et zeppelin-site.xml situés dans le répertoire conf de Zeppelin. Dans mon cas, voici ce que cela donne :
Extrait de mon fichier zeppelin-env.sh
export MASTER=spark://spark.bd:7077
export SPARK_HOME=/root/spark_
Extrait de mon fichier zeppelin-site.xml
zeppelin.server.addr
0.0.0.0
Server address
zeppelin.server.port
8090
Server port.
Laissez 0.0.0.0 pour l’adresse du serveur. Ensuite, précisez le numéro de port que vous souhaitez.
Cela fait, on va pouvoir lancer Zeppelin. On commence par lancer Spark en mode cluster.
start-master.sh
start-slave.sh spark://spark.bd:7077 –m 2G
Le slave doit être lancé avec suffisamment de mémoire pour exécuter Zeppelin. Si ce n’est pas le cas, vous pourrez accéder à vos notebook mais vous ne pourrez pas exécuter de traitements Spark.
Il faut ensuite lancer Zeppelin.
cd /root/incubator-zeppelin
./bin/zeppelin-daemon.sh start
Vous pouvez contrôler le bon lancement de Spark et de Zeppelin en allant sur la page de monitoring de Spark (dans mon cas à l’adresse: « https://localhost:8080 »)

Présentation de Zeppelin
Si tout s’est bien passé, vous pourrez accéder à la page d’accueil de Zeppelin en allant sur l’url suivante : « https://localhost:8090 »
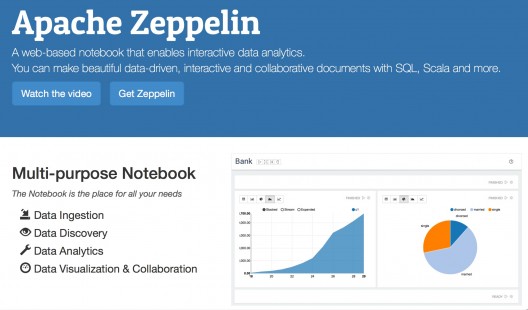
Vous pouvez ouvrir un notebook existant ou créer un notebook.
Traitement Spark
Le premier intérêt de Zeppelin est de pouvoir écrire du code Spark. A noter que les librairies principales sont (spark, sparkContext) sont automatiquement importées.
Vous pouvez donc écrire votre code directement dans l’une des fenêtres du notebook. Une fois le code écrit, il suffit de cliquer sur le triangle en haut à droite pour l’exécuter. La sortie s’affiche à la suite du code.

On bénéficie avec Zeppelin des avantages du spark-shell (exécution directe du code sans compilation) tout en ayant à l’écran l’ensemble des lignes de notre traitement (ce qui permet de le modifier simplement).
En outre, il ne se limite pas aux fonctions de base de Spark. On peut faire tourner par exemple des algorithmes de Machine Learning en important les librairies nécessaires en début de script.
Visualisation graphique
Si notre traitement enregistre les données dans des DataFrames puis des tables, on peut ensuite les exécuter du code SQL et représenter les résultats sous forme de tableaux ou de graphiques.
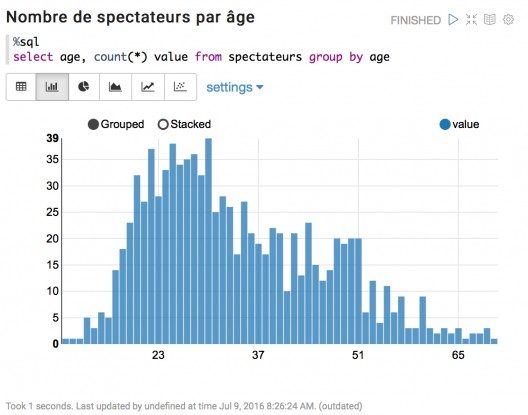
Bien sûr, les possibilités sont limitées : l’objectif de Zeppelin n’est pas de concurrencer les cadors du secteur comme Qlik ou Tableau. L’intérêt est d’offrir au sein d’un même outil les capacités de traiter les données avec Spark sur un cluster puissant et de visualiser les résultats.
Commandes Shell
Zeppelin permet également d’exécuter des commandes shell au sein de la même interface. Pas besoin d’ouvrir un terminal et de se connecter à notre cluster Spark. On peut retrouver directement le chemin de nos fichiers de données ou encore visualiser les premières lignes.
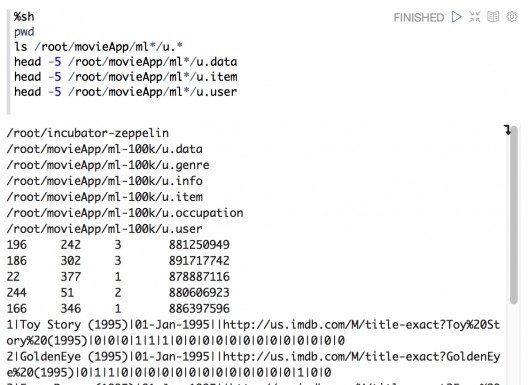
Paramétrage
Il est possible de paramétrer les différentes fenêtres de notre notebook en cliquant sur la petite roue crantée en haut à droite.
On peut alors mettre un titre ou réduire la largeur de notre fenêtre.
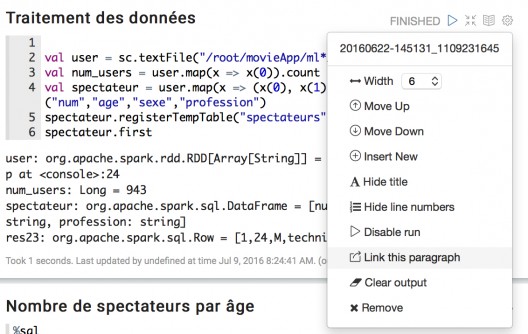
Voilà un exemple de rendu sur deux colonnes avec le code affiché et la sortie du traitement masquée :
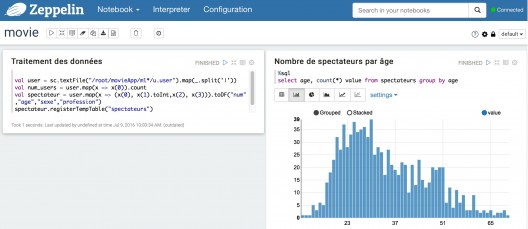
Encore d’autres fonctionnalités
Un notebook peut s’exporter. Il intègre le code et les visuels s’ils ont été générés mais pas les données : le fichier généré est donc très léger.
On peut l’exporter pour sauvegarder le notebook sur son disque ou encore le transmettre à un ami par email qui pourra l’importer sur sa propre plateforme.
Sur une plateforme d’entreprise, on peut aussi partager son notebook en ajustant les droits mais je ne l’ai pas testé.
Autre fonctionnalité intéressante : le clonage qui permet de dupliquer son notebook pour faire des modifications sans risque.
Un outil prometteur
Zeppelin est un outil prometteur. En effet, il répond à un vrai besoin d’outil intégré pour tous les travaux de type Datalab avec Spark. En incubation jusqu’au mois de mai de cette année, il vient d’être adoubé par la communauté Apache. Preuve de son succès, il est déjà proposé sur la distribution Hortonworks. N’hésitez pas à le découvrir en consultant la page Apache du projet.


![[Data Rider] REX Collecte de données IoT – Étape 1 : Initier la collecte](https://fr.blog.businessdecision.com/wp-content/uploads/2025/05/data-rider-rex-collecte-donnees-1024x512-1.jpg)











Commentaires (3)
Votre adresse de messagerie est uniquement utilisée par Business & Decision, responsable de traitement, aux fins de traitement de votre demande et d’envoi de toute communication de Business & Decision en relation avec votre demande uniquement. En savoir plus sur la gestion de vos données et vos droits.
Pour pouvoir faire des requêtes sql sous zeppelin, il faut créer dans la partie script une dataframe puis appliquer la fonction createOrReplaceTempView() pour pouvoir l'utiliser comme une table.
Imaginons que l'on crée une dataframe df contenant des informations sur les personnes, il suffit ensuite d'écrire:
df.createOrReplaceTempView("Personne")
On peut alors créer dans un bloc spécifique préfixé par %sql sa requête sql.
En espérant que cela puisse t'aider.
pour et le comment sql s'applique normalement ???